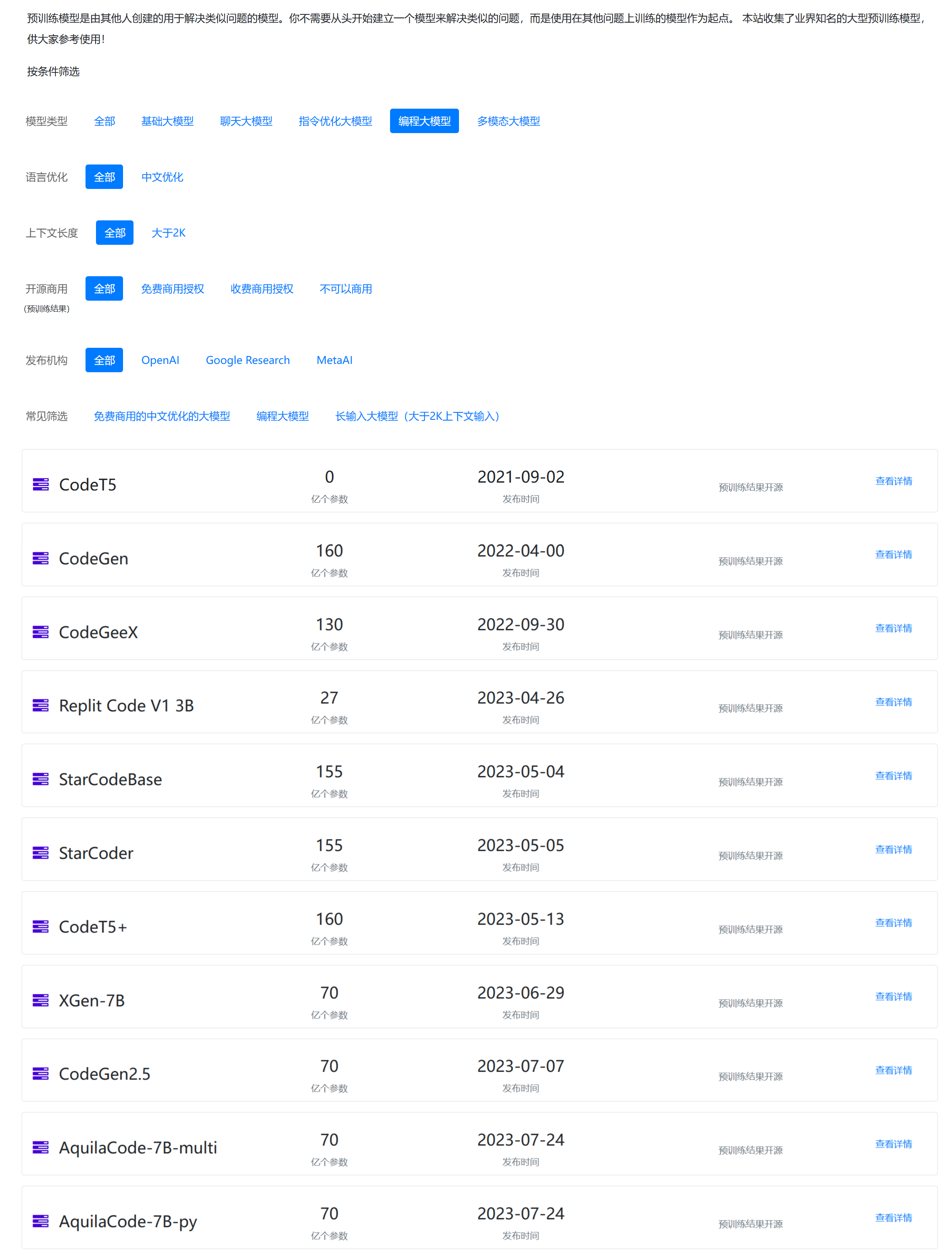
MetaAI开源高质量高精度标注的图像数据集FACET:3.2万张图片、5万个主题,平均图像解析度达到1500×2000
MetaAI在2023年8月31日开源了一个全新的图像数据集,FACET(FAirness in Computer Vision EvaluaTion),FACET数据集包含32,000张图片和50,000人,这些图片由专家进行了详细的标注,包括人口统计属性(如感知性别表达和感知年龄组)和其他物理属性(如感知肤色和发型)。这样的设计使得研究人员可以更全面、更深入地评估模型在不同人群中的表现,从而更准确地识别和解决模型的不公平性问题。