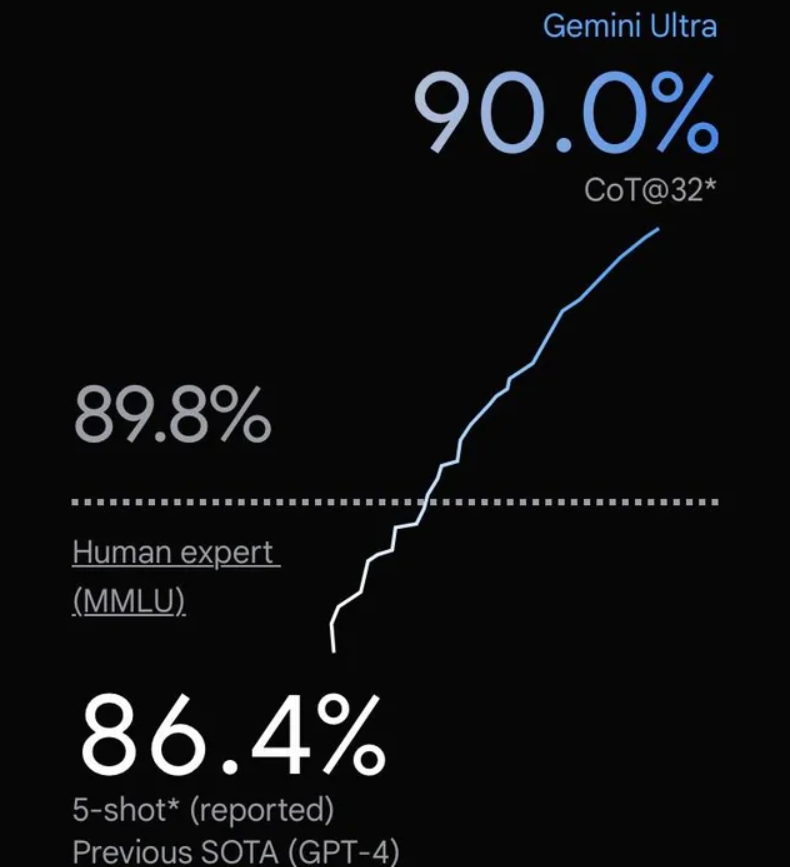
谷歌发布号称超过GPT-4V的大模型Gemini:4个版本,最大的Gemini的MMLU得分90.04,首次超过90的大模型
谷歌在几个小时前发布了Gemini大模型,号称历史最强的大模型。这是一系列的多模态的大模型,在各项评分中超过了GPT-4V,可能是目前最强的模型。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
谷歌在几个小时前发布了Gemini大模型,号称历史最强的大模型。这是一系列的多模态的大模型,在各项评分中超过了GPT-4V,可能是目前最强的模型。

The Information最新消息透露OpenAI正在抓紧准备GPT-4多模态版本的发布,可能称为GPT4-Vision。

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。
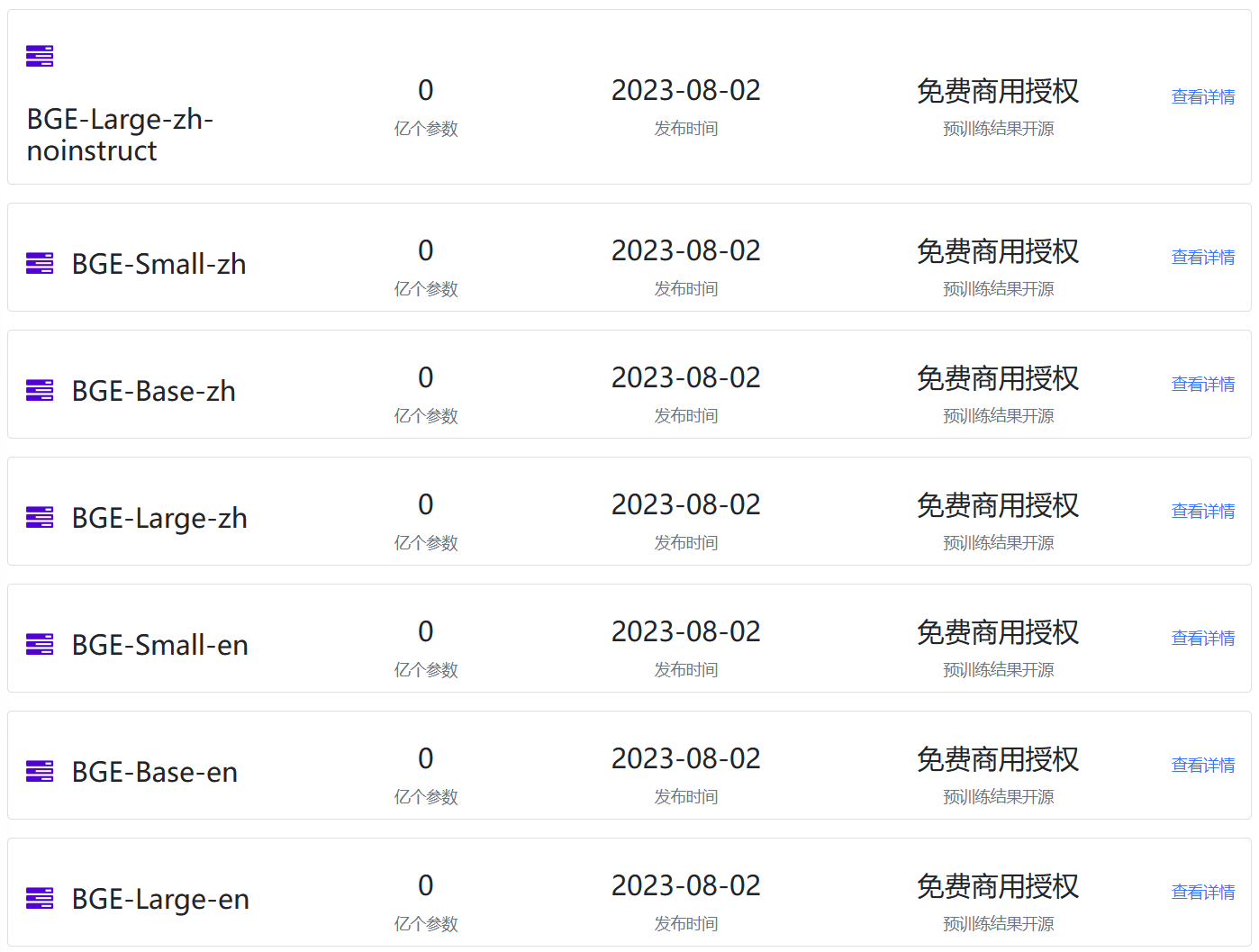
Embedding模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多LLM应用必不可少的部分。但是,现实中开源的Emebdding模型却很少。最近,北京智源人工智能研究院(BAAI)开源了BGE系列Embedding模型,不仅在MTEB排行榜中登顶冠军,还是免费商用授权的大模型,支持中文,应该可以满足相当多人的需要。

文本embedding是当前大模型应用中一个十分重要的角色。在长上下文支持、私有数据问答等方面有非常重要的应用。但是相比较开源领域快速发布的大模型节奏,开源的embedding模型和数据却非常少。今天,GPT4All宣布在其软件中增加embedding的支持,这是一个完全免费且可商用的产品,最重要的是可以在我们本地用CPU来做推理。
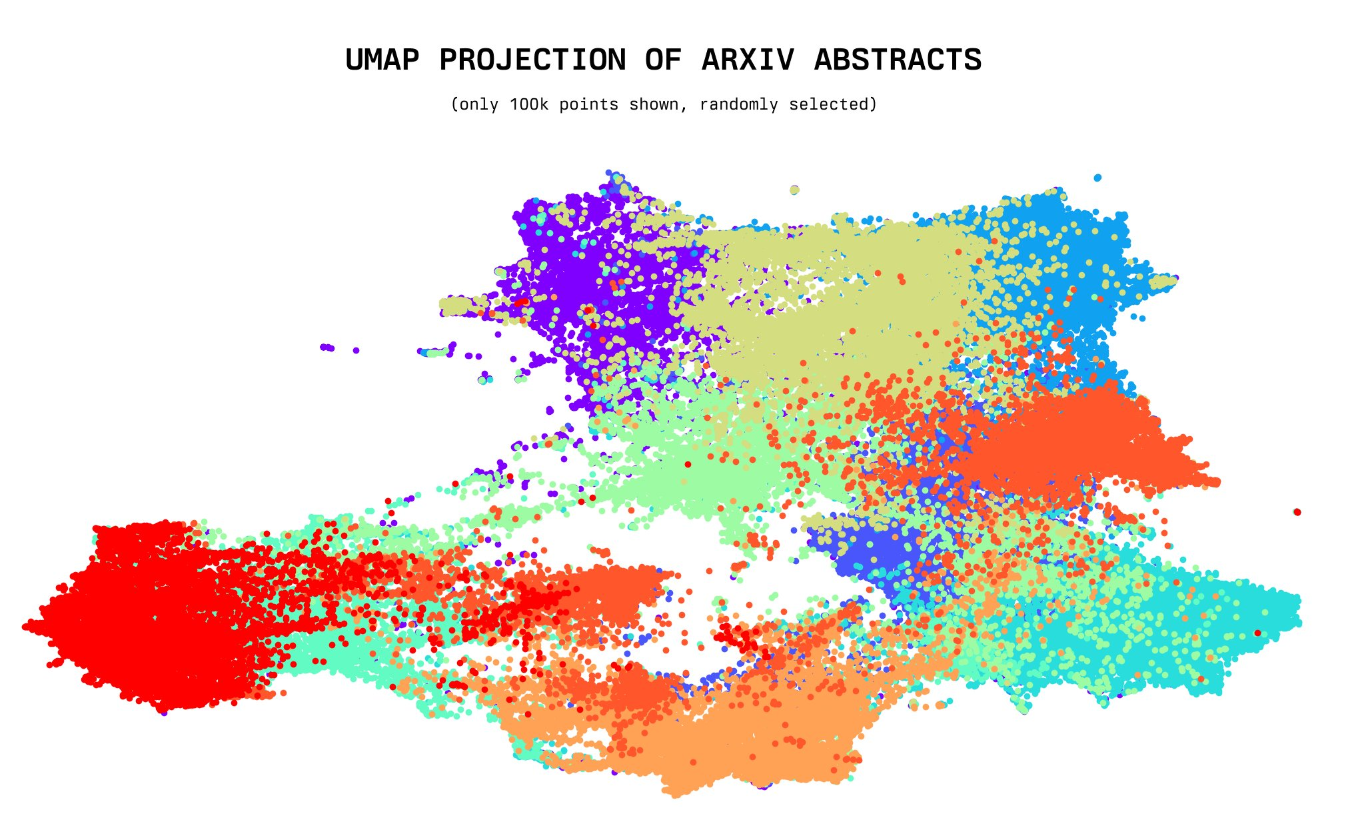
今天,一位年仅20岁的小哥willdepue 开源了230万arXiv论文的标题和摘要的embedding向量数据集,完全开源。该数据集包含截止2023年5月4日的所有arXiv上的论文标题和摘要的embedding结果,使用的是开源的Instructor XL抽取。未来将开放更多其它相关数据的embedding结果
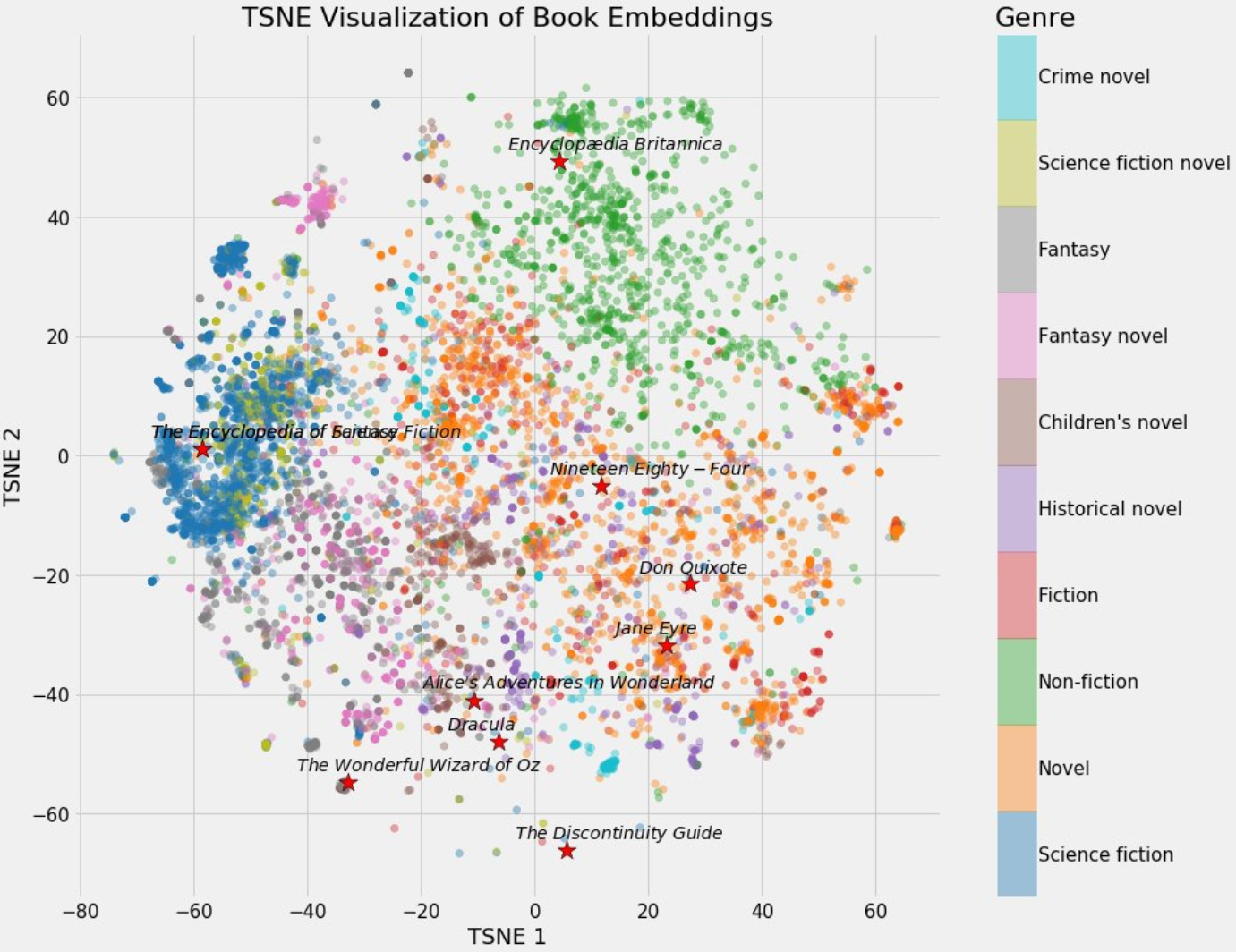
今天,推特上一位科技博主SullyOmarr分享了一个关于embedding的内容十分火爆。主要介绍为什么embedding对于在目前的AI大模型中很重要。这是一个十分不错的关于embedding知识的介绍。本文将根据SullyOmarr的内容也对embedding做一个简单的介绍,并解释为什么它在大语言模型中十分重要。
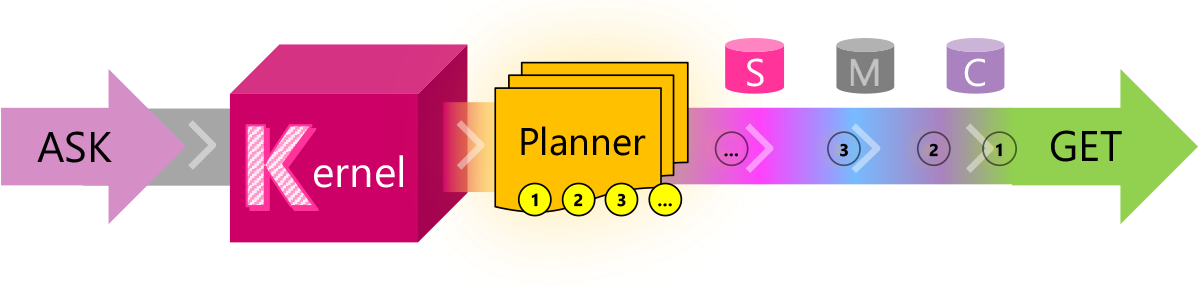
目前的LLM有很多限制,有很多问题并不能很好的解决,例如文本输入长度有限、无法记住很早之前的信息等。而这些问题目前也都缺少合适的解决方案。它们所依赖的技术:如任务规划、提示模板、向量化内存等需要的是编程的智慧。Semantic Kernel就是微软在这个背景下推出的一个结合LLM与传统编程技术的编程框架。

嵌入(Embedding)是深度学习方法处理自然语言文本最重要的方式之一。它将人类的自然语言和文本转换成一个浮点型的向量。向量之间的距离代表了它们的关系。今天,OpenAI宣布了他们的Embedding新模型——text-embedding-ada-002。官方宣称这是目前OpenAI最强的嵌入模型,可以将任意文本转换成一个向量,且效果好于目前所有OpenAI的模型。
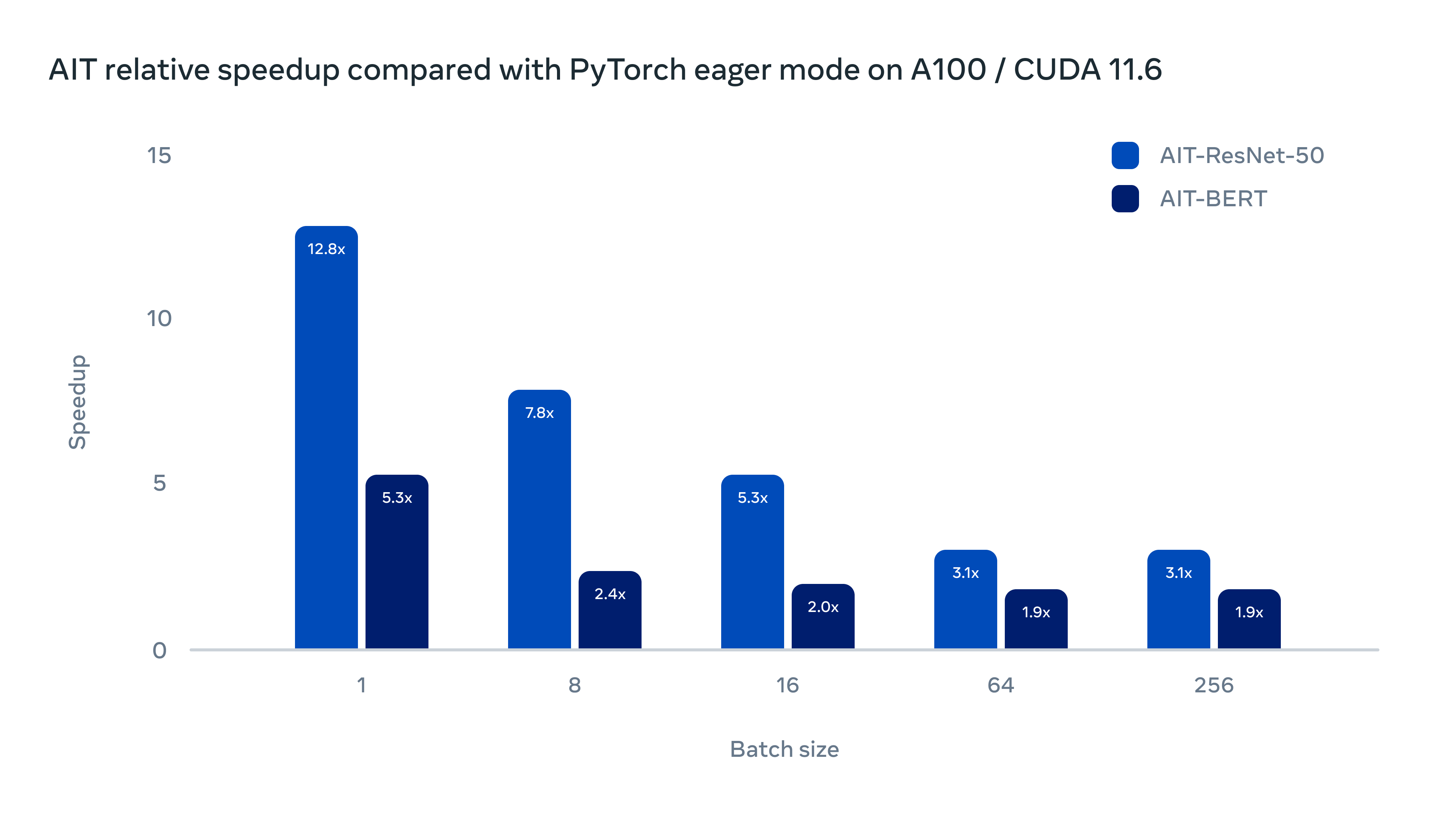
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。
Sequence-to-Sequence model
EM(expectation-maximization)算法是统计学中求统计模型的最大似然和最大后验参数估计的一种迭代式算法,模型一般是依赖于不可观测的潜在变量。
狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)是一种非参数贝叶斯模型,它可以理解为一种聚类方法,但是不需要指定类别数量,它可以从数据中推断簇的数量。这篇博客将描述该模型及其求解过程。