PandasTutor——一个用于可视化pandas操作的神器
pandas是Python中一个非常重要的分析工具,在数据处理方面应用非常广泛。但是,也是因为pandas包含的操作很多,所以初学者很多时候也不能特别能理解这些操作。 为了让初学者能够充分理解pandas中的操作,Pandas Tutor将pandas的操作变成可视化的过程,让我们充分理解这个过程。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
pandas是Python中一个非常重要的分析工具,在数据处理方面应用非常广泛。但是,也是因为pandas包含的操作很多,所以初学者很多时候也不能特别能理解这些操作。 为了让初学者能够充分理解pandas中的操作,Pandas Tutor将pandas的操作变成可视化的过程,让我们充分理解这个过程。

Python是目前最流行的编程语言,也是开放生态做得最好的编程语言之一。大多数深度学习框架、机器学习的框架都有很优秀的Python版本。这篇博客主要为大家介绍5个python生态系中解决NLP任务的框架。

九月份刚过去,GitHub上最火的AI研究排序出炉。这是根据9月份GitHub上创建的新的AI研究相关的项目排序,根据Star的数量来的。都是AI各大领域比较受欢迎和重要的项目。

Jupyter Notebook虽然在教学等领域有着非常大的优势,但是实际编程中,它的效率、可维护性等方面与python脚本相比的差距到底在哪也一直不那么清晰。就在上个月底,JetBrains的研究人员使用了大量的数据详细对比了二者的差异。这里总结一下其主要结论。
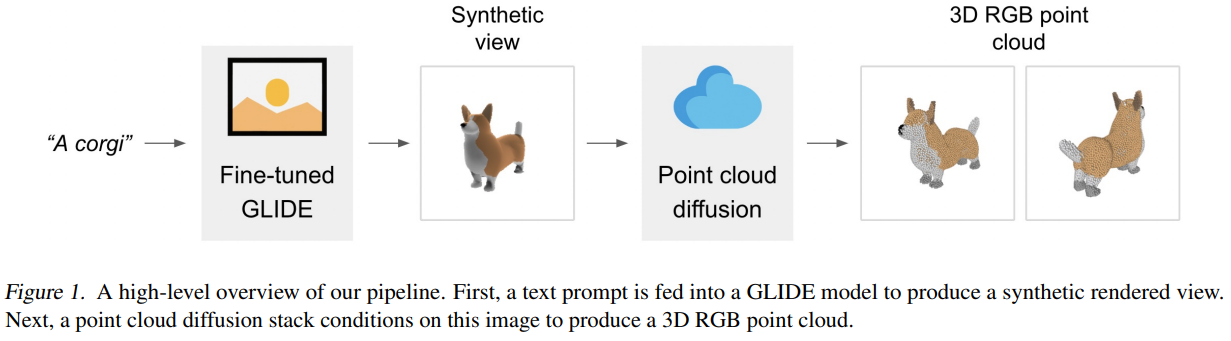
三维物体的生成(3D)其实是AR/VR领域一个非常重要的技术。但是,受限于算力和现有模型的限制,三维物体的生成相比较图像生成来说效率太低。目前,最好的图像生成模型在几秒钟就可以根据文字生成图像结果,但是3D物体的生成通常需要多个GPU小时才可以生成一个对象。为此,OpenAI在今天开源了一个速度极快的3D物体生成模型——Point-E,需要注意的是,这是今年来OpenAI罕见的源代码和预训练结果都开源的一个模型。
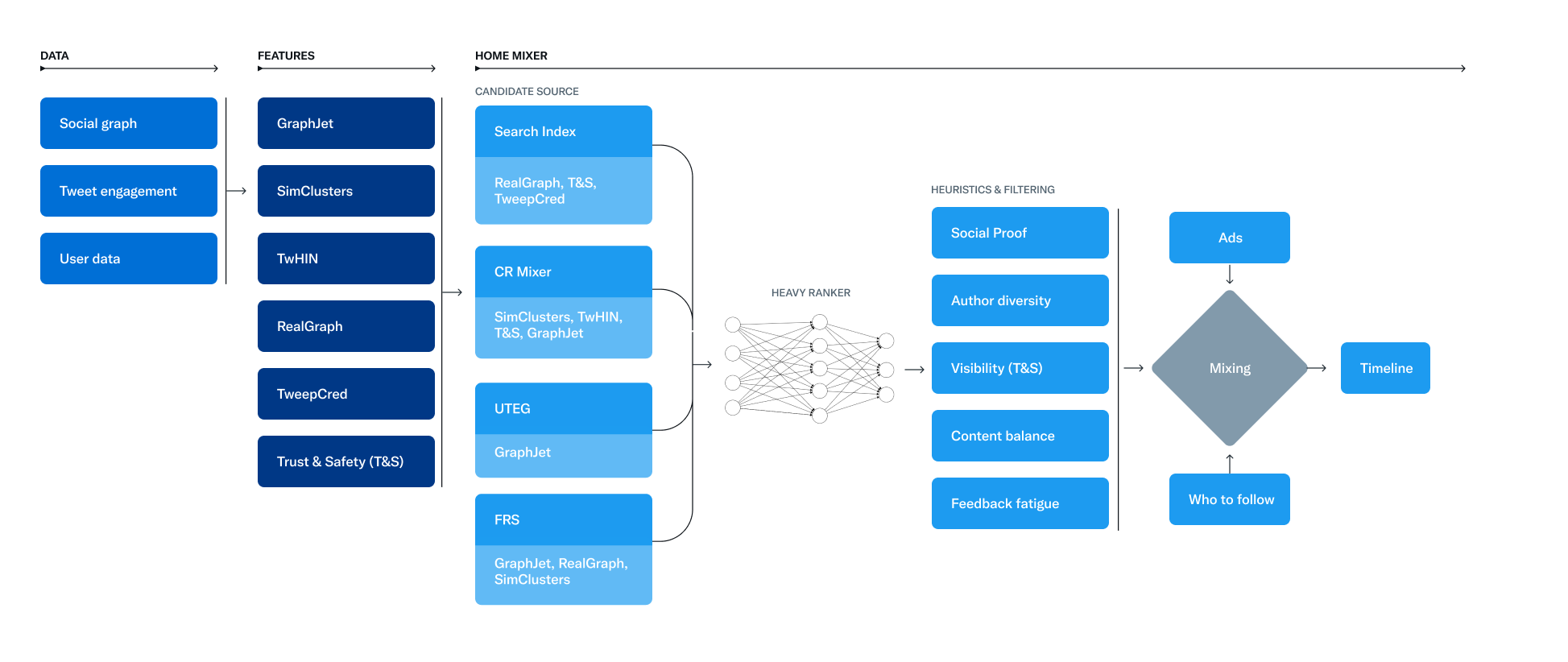
虽然最近一段时间大模型十分火爆,但是传统的推荐依然是当前很多业务的核心能力,就在几个小时前,Twitter官方开源了自己的推荐系统,并详细介绍了它们的推荐算法。本文将简单介绍一下推特的推荐算法和架构!
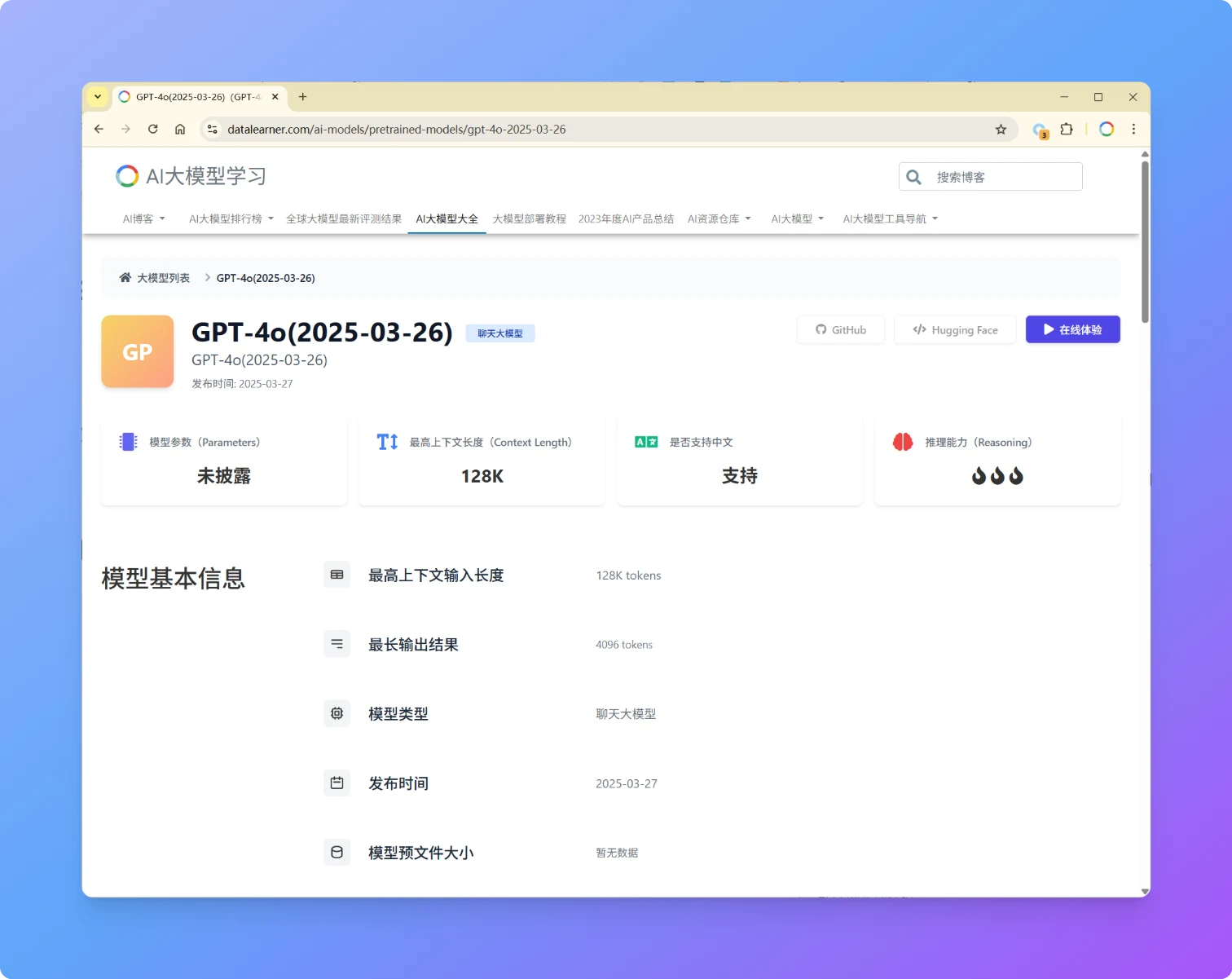
OpenAI再次发布GPT-4o更新版本,版本号为GPT-4o(2025-03-26),本次发布的GPT-4o模型在性能、易用性和协作能力上迎来多项优化,进一步提升了模型的直觉性、创造力和任务执行能力。此次更新聚焦于 STEM 与编程问题解决、指令遵循精度以及自然交互体验,各方面评测进步明显,超过了GPT-4.5。
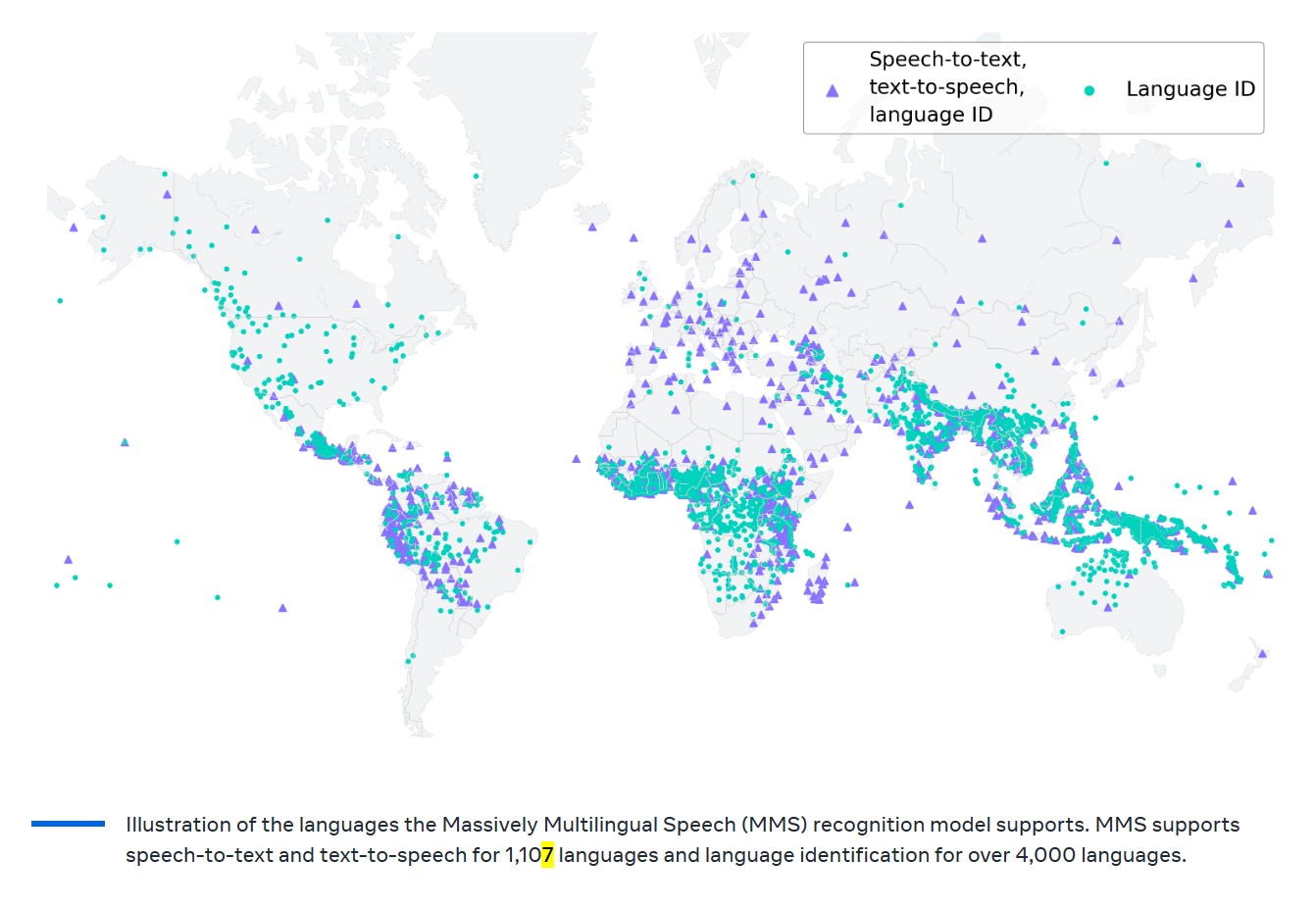
今天,Meta的首席AI科学家Yann LeCun在推特上宣布了MetaAI的最新研究成果:MMS,一个支持1107种语言的自动语音识别模型和语音合成模型,该模型自动语音识别的单词错误率只有OpenAI开源的Whisper的一半!但是支持的语言却有1107种,是Whisper的11倍!代码与预训练结果已开源,不过不可以商用哦~

Google旗下自动驾驶公司Waymo的研究人员Mingxing Tan发现了一个可以替代Cross-Entropy Loss的新的损失函数:PolyLoss,这是发表在ICLR 22的一篇新论文。什么都不变的情况下,只需要将损失函数的代码替换成PolyLoss,那么模型在图像分类、图像检测等任务的性能就会有很好的提升!
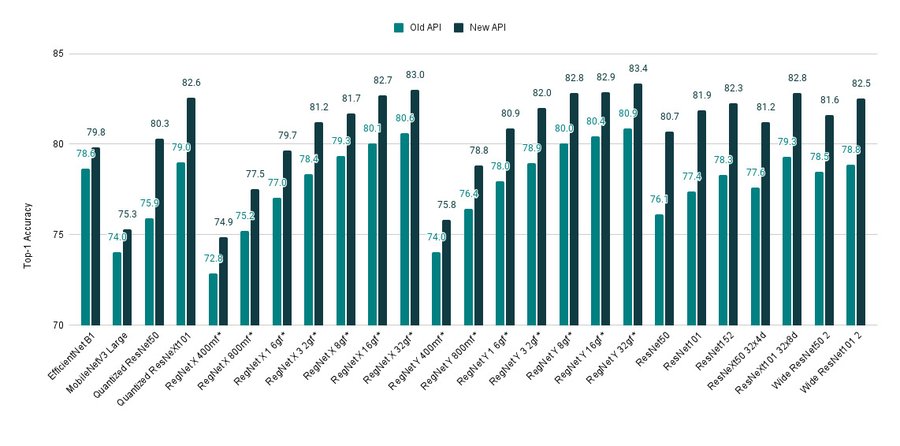
PyTorch最新的1.12版本已经在前天发布。而其中TorchVision是基于PyTorch框架开发的面向CV解决方案的一个PyThon库,其最主要的特点是包含了很多流行的数据集、模型架构以及预训练模型等。本次也随着PyTorch1.12的发布更新到了v0.13。此次发布包含几个非常好的提升,值得大家关注。

此前,OpenAI的CEO说今年等算力不那么紧张的时候就可以让大家微调OpenAI的GPT模型,现在这个功能已经发布了!OpenAI发布了GPT-3.5 Turbo的微调接口,允许大家用自己的数据微调GPT-3.5模型!

大模型应用中一个非常重要的问题就是大模型的响应速度。尤其是作为聊天应用来说,在用户输入之后,大模型可以在多短的时间内给出回应对于用户体验来说影响巨大。这里有2个问题经常会被大家所关注,一个是大模型每秒输出多少个tokens就可以满足用户的日常聊天使用,另一个问题是单张显卡最多可以支撑多少个用户的聊天需求。在前几天的vllm meetup上,贾扬清给出了一些讨论,他认为我们目前可能高估了大模型的聊天应用成本。
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。

本文介绍 Terminal-Bench 的设计理念,深入讲解 core、Terminal-Bench Hard 与最新 Terminal-Bench 2.0 的区别,帮助开发者选择合适的 AI 终端评测基准。
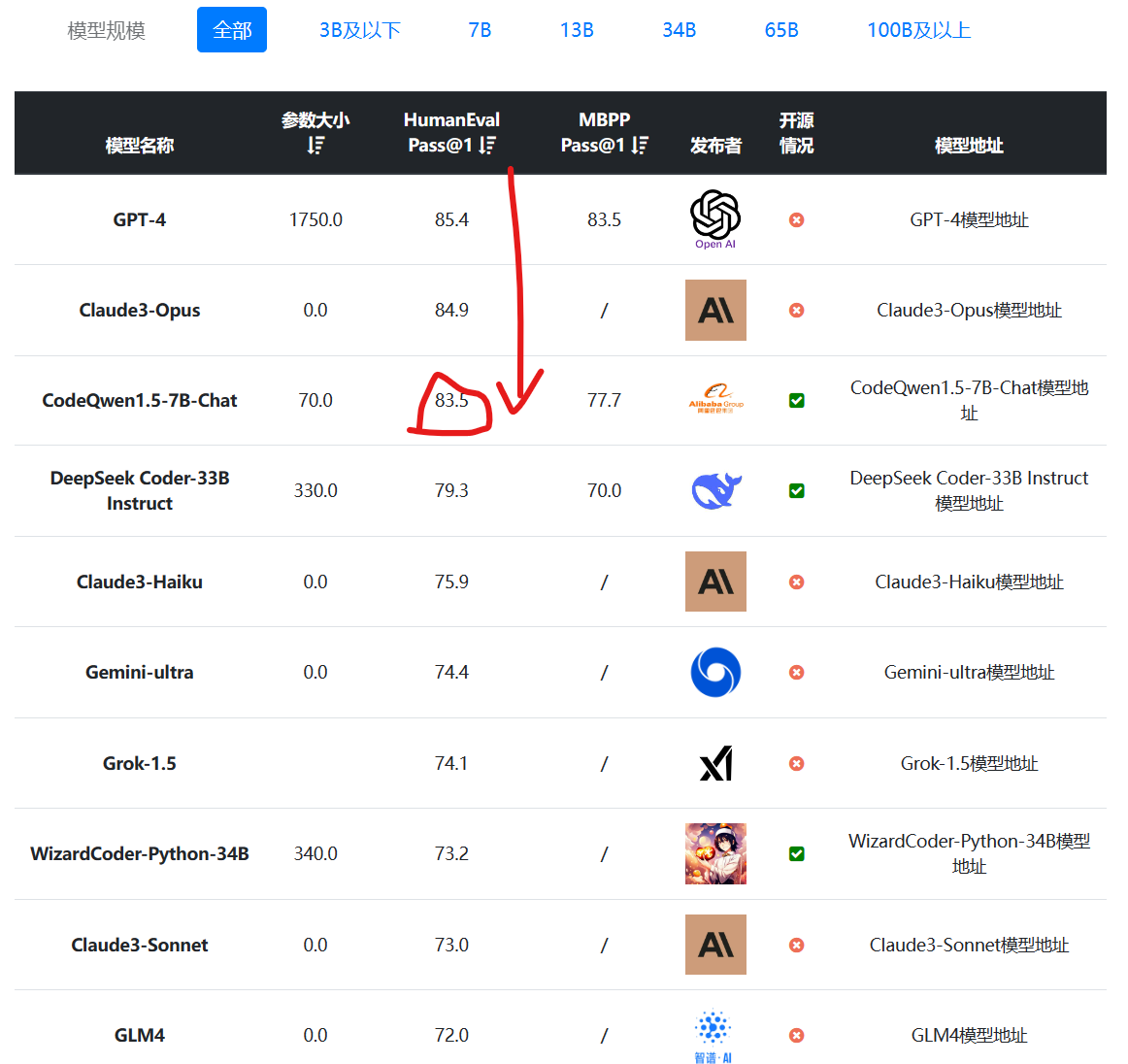
编程大模型是当前大语言模型里面最重要的一类。一般是基础大模型在预训练之后,加入代码数据集继续训练得到。在代码补全、代码生成方面一般强于常规的大语言模型。阿里最新开源的70亿参数大模型CodeQwen1.5-7B在HumanEval评测结果上超过了GPT-4早期版本,表现异常地好!

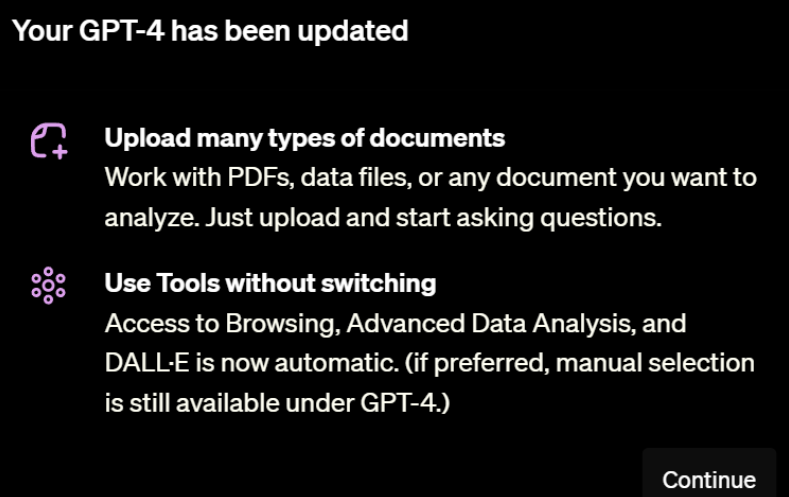
此前OpenAI的ChatGPT Plus版本为GPT-4模型提供了多个强大的插件供大家使用,包括基于Bing的带网络浏览的Browse、文本生成图片的DALL·E3、高级数据分析功能等。就在几个小时前,OpenAI的部分用户收到了官方的一个非常重磅的更新,即上传任意文档的分析以及整合了所有工具后的GPT-4!这个功能被称为GPT-4(All Tools)!这个工具可以在一次对话中自主选择调用多个不同工具完成用户的输入指令,非常接近AI Agent形态!
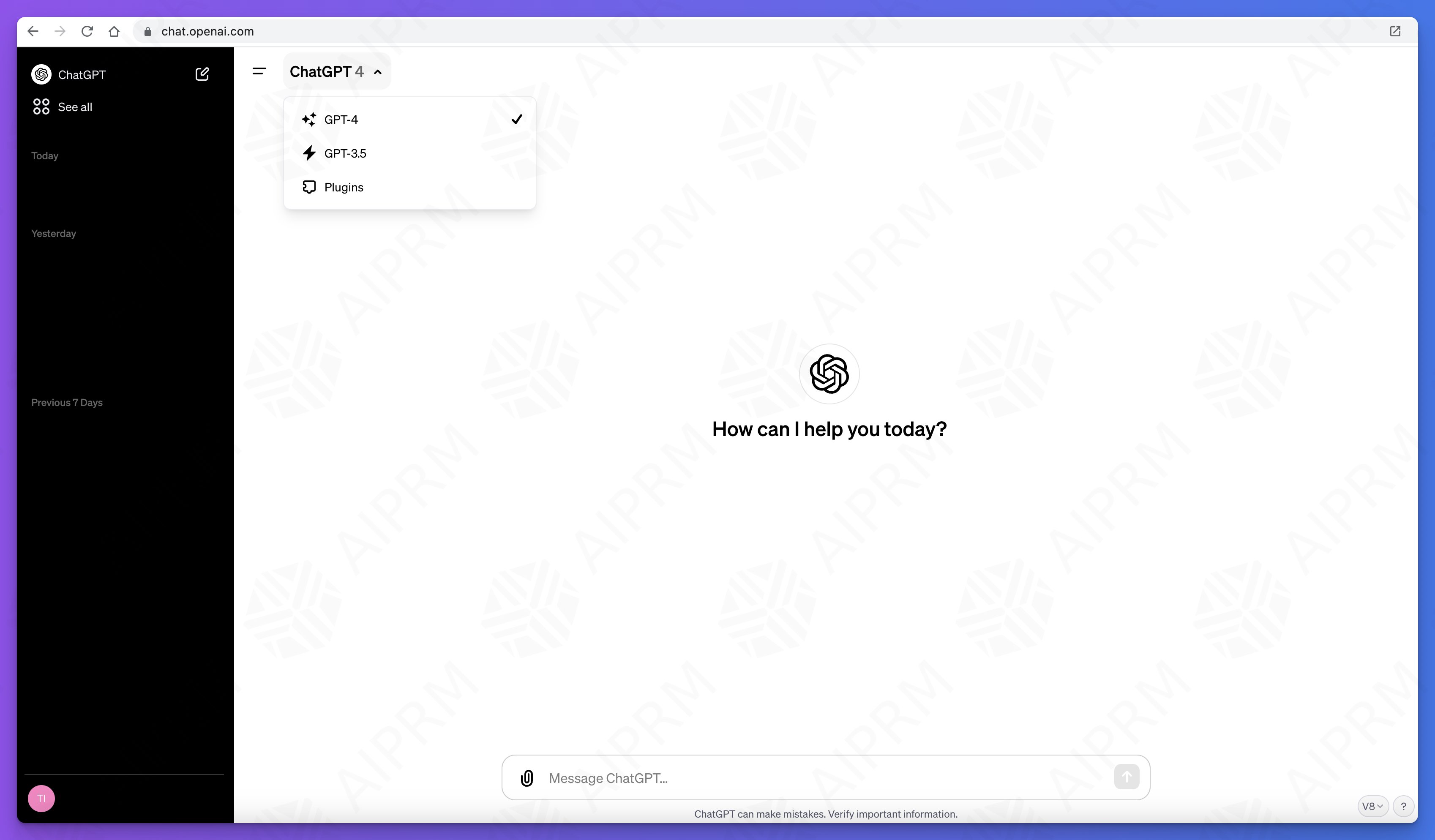
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!

随着大语言模型(LLM)的发展越来越快,我们需要更好的方法来评估它们到底有多“聪明”,特别是在处理复杂数学问题的时候。AIME 2025 就是这样一个工具,它专门用来测试当前 AI 在高等数学推理方面的真实水平。