机器学习之正则化项
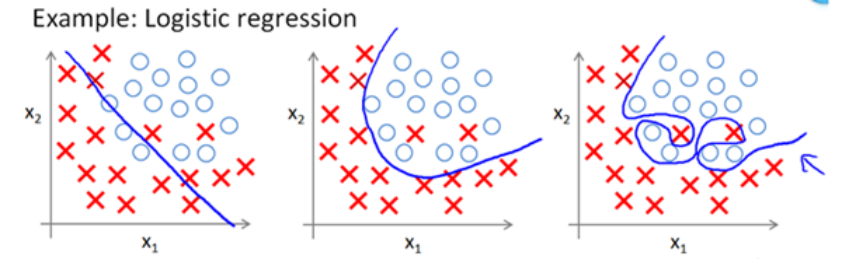
在我们给推荐问题建模时,神秘的正则化项L0、L1、L2的选择对模型很重要。为什么要加正则化?正则化有哪几种形式?到底该选择哪种正则化来建模呢?正则化项与推荐问题的关系?
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
在我们给推荐问题建模时,神秘的正则化项L0、L1、L2的选择对模型很重要。为什么要加正则化?正则化有哪几种形式?到底该选择哪种正则化来建模呢?正则化项与推荐问题的关系?