
2023年4月25日的AI技术新进展快报:Chatbot Arena、Track Anything、600+AI工具、RedPajama 7B进展、科大讯飞大模型内测等
最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。

最近一段时间Text-to-Image模型十分火热。OpenAI的DALL·E2模型的效果十分惊艳。不过,由于Open AI现在的不Open策略,大家还无法使用这个模型,业界只开放了一个小版本的DALL·E mini。不过,前段时间,Stability AI发布的Stable Diffusion其效果明显好于现有模型,且免费开放使用,让大家都开心了一把。不过原有模型是Torch实现的,而现在,基于Tensorflow/Keras实现的Stable Diffusion已经开源。
这是一位热心网友(faridrashidi)收集的Kaggle竞赛的解决方案。这是在过去的Kaggle竞赛中表现最好的选手所分享的几乎所有可用的解决方案和想法的列表。一旦有新的比赛结束,这个列表就会更新。
HuggingFace是近几年最火热的AI社区,在短短几年时间里已经称为AI模型的GitHub。目前,HuggingFace上已经托管了18万多的模型、3万多的数据集以及4万多的模型demo(spaces)。今天,HuggingFace发布了HuggingChat,声称要做最好的开源AI Chat项目,并且对所有人开放。

这是一篇来自Sayak Paul的预测,这个哥们长期混迹于各个开源社区,积极参与各大公司的开发者大会。目前在一家初创企业工作,简历非常丰富,非常积极在社区推广自己。但是不管怎么说,他在计算机视觉领域也是一直在一线工作。他对未来计算机视觉的发展方向有五个预测,虽然不一定准确,但是我们可以借助这个进行思考。

微软在去年4月份的时候推出了一个构建虚拟助手的指南:《构建人工智能应用的开发者指南·第二版》。这份报告帮助我们借助微软的工具构建一个虚拟助手,本文将简要描述一下这份报告,文末有相关资源下载。

近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。

就在刚才,OpenAI官方宣布即将推出GPT-4o mini模型,这是一个成本很低的AI大模型,是GPT-3.5的替代版本。OpenAI官方说,该模型最大的特点是很便宜,但是能力更强,因此可以极大提高AI在不同领域的应用。

昨天,卡地夫大学的NLP研究小组CardiffNLP发布了一个全新的NLP处理Python库——TweetNLP,这是一个完全基于推文训练的NLP的Python库。它提供了一组非常实用的NLP工具,可以做推文的情感分析、emoji预测、命名实体识别等。

开源大语言模型经过一年多的发展,终于有一个模型可以在权威榜单上击败GPT-4的较早的版本,这就是CohereAI企业开源的Command R+。这是一个开源但是不允许商用的模型,参数规模达到1040亿,也是目前为止开源参数规模最大的一个模型。
OpenAI再次发布GPT-4o更新版本,版本号为GPT-4o(2025-03-26),本次发布的GPT-4o模型在性能、易用性和协作能力上迎来多项优化,进一步提升了模型的直觉性、创造力和任务执行能力。此次更新聚焦于 STEM 与编程问题解决、指令遵循精度以及自然交互体验,各方面评测进步明显,超过了GPT-4.5。

OpenAI在3月15日发布了一个最新的GPT-3和Codex的版本,这个版本最大的能力就是可以在已有的文本上插入或者编辑新的内容。而不是续写已有的文本。这个能力最大的应用就是重写已有文本,或者用来重构代码。
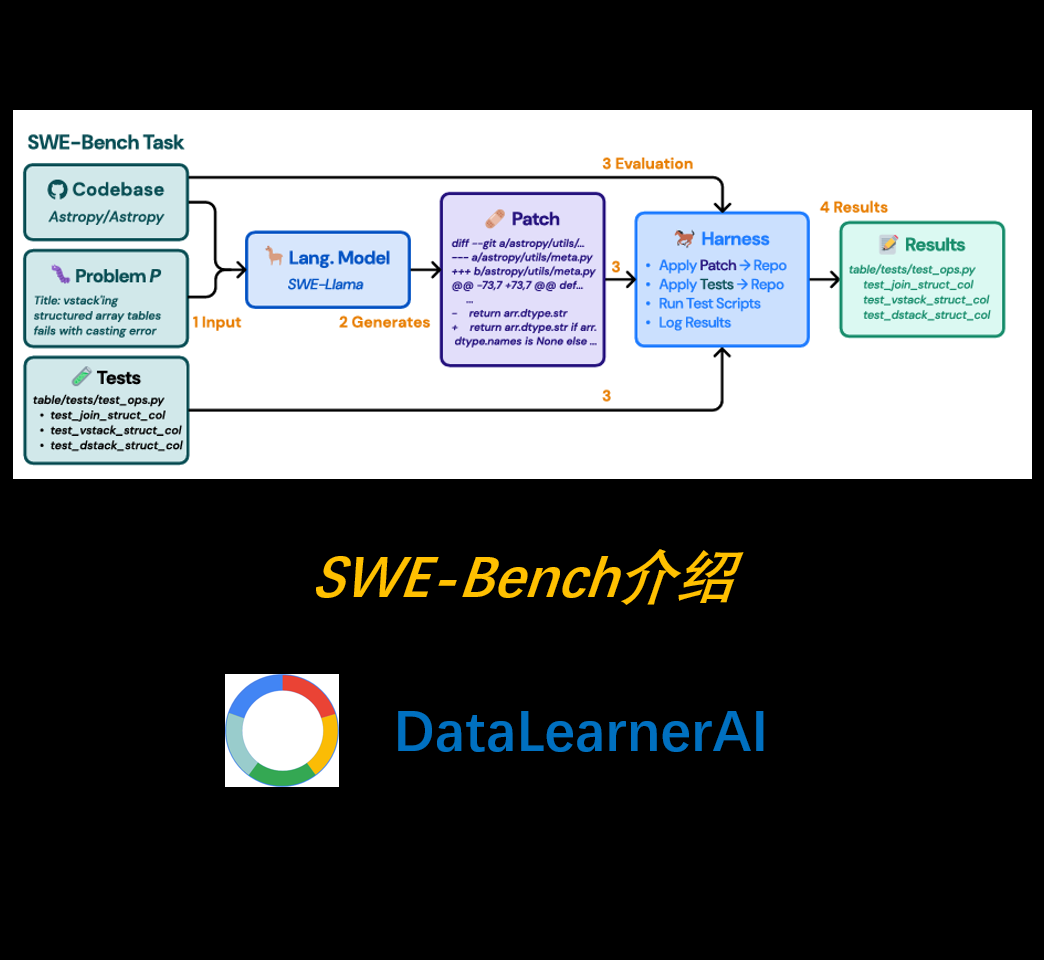
随着大语言模型(LLM)的快速发展,它们在自然语言处理(NLP)、代码生成等领域的表现已达到前所未有的高度。然而,现有的代码评测基准(如 HumanEval)通常侧重于**自包含的、较短的代码生成任务**,而未能充分模拟真实世界的软件开发环境。为弥补这一空白,研究者提出了一种全新的评测基准——**SWE-Bench**,旨在测试 LLM 在**真实软件工程问题**中的能力。

大多数编程领域的大模型应用都是单行代码补全或者单个函数生成的方式。完整的程序生成依然面临较大的挑战。而现在,一个初创企业直接发布了一个AI软件工程师,可以直接作为一个程序员来接受用户需求和反馈,独立完成编码和应用上线功能。这就是Cognition发布的全球首个AI软件工程师Devin。

今天,HuggingFace官方宣布了Transformers最大胆的功能:Transformers Agents。这是继AutoGPT开创性发布之后,AI Agent被业界接受的另一个重要的里程碑。
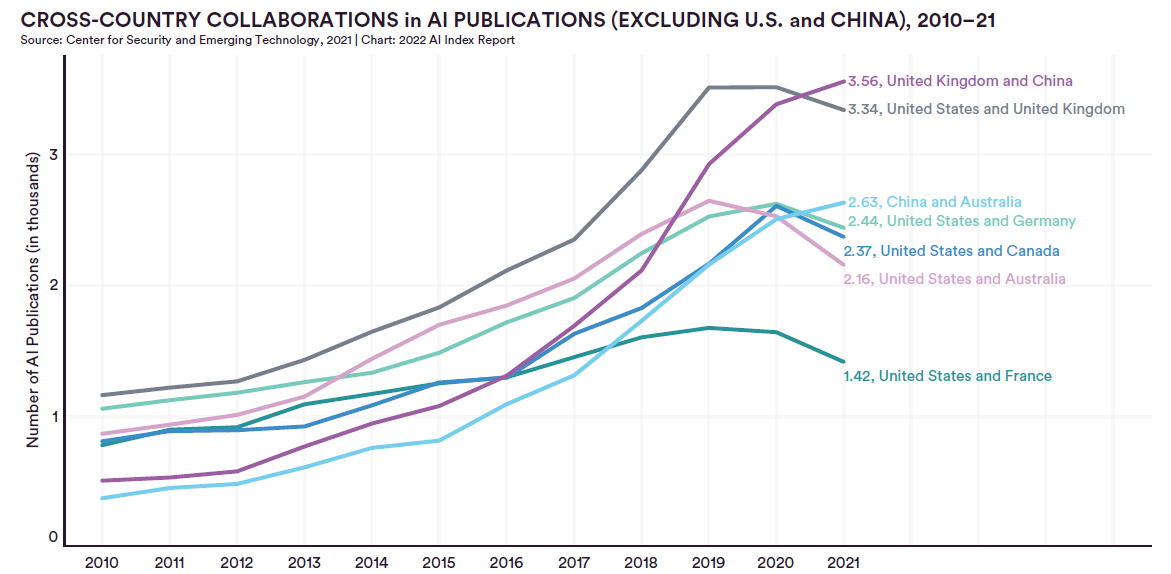
人工智能指数是斯坦福大学以人为本人工智能研究所(Stanford Institute for Human-Centered Artificial Intelligence (HAI))联合学术界、工业界的专家一起发布的人工智能相关的发展报告。2022年度AI指数报告在近几日发布。

The AI Index报告是斯坦福大学发布的人工智能发展研究报告。最早的报告开始于2017年,每年一个版本,主要是总结过去一年人工智能的发展情况。2023年斯坦福The AI Index已经在近日发布。相比较之前的报告,今年的报告新增对Foundation模型的分析。让我们看看斯坦福大学如何总结2022年人工智能领域的发展情况。
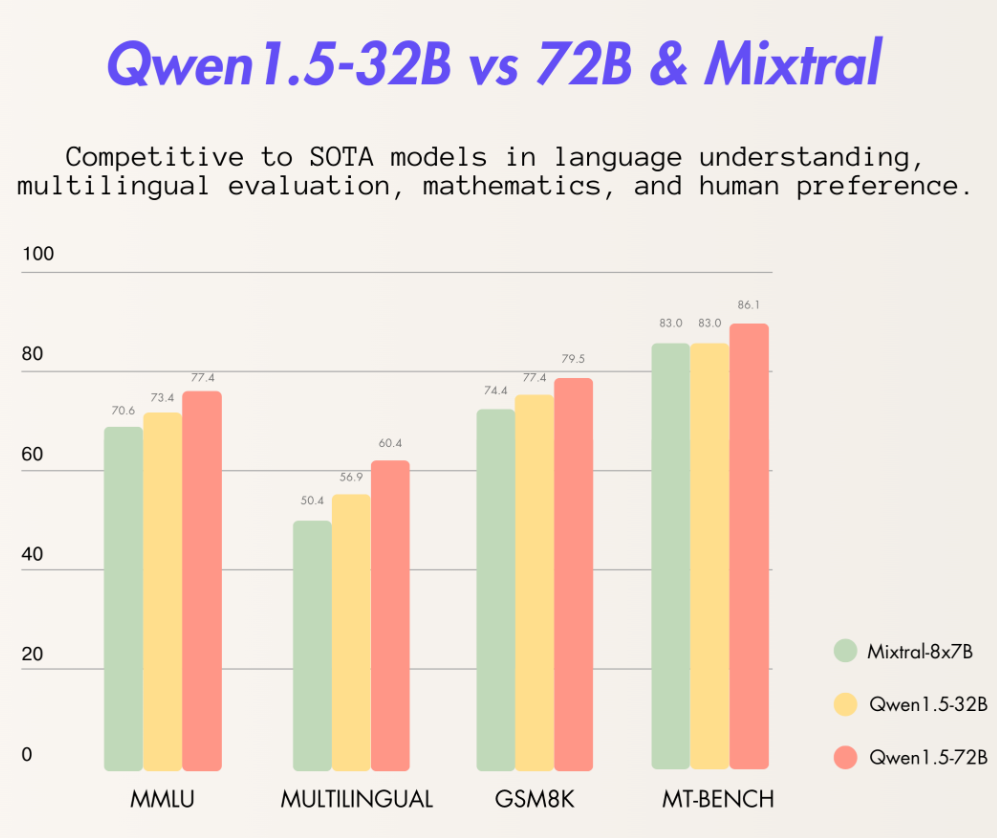
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。
介绍如何使用git下载远程、更新远程项目到本地,提交本地更改到远程

随着安全隐私被大家所重视,网站开启HTTPS访问已经是不可阻挡的趋势。HTTPS协议就是借助SSL/TLS证书实现http的加密传输的协议(HTTP Over SSL/TLS)。本文将记录如何使用第三方库申请Let's Encrypt证书,并在tomcat中开启相关的功能。
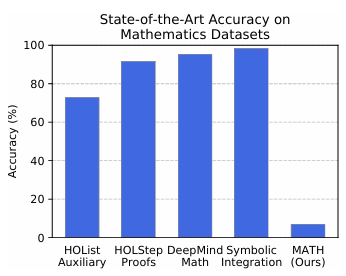
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。
几个小时前SemiAnalysis的DYLAN PATEL和DYLAN PATEL发布了一个关于GPT-4的技术信息,包括GPT-4的架构、参数数量、训练成本、训练数据集等。本篇涉及的GPT-4数据是由他们收集,并未公开数据源。但是内容还是有一定参考性,大家自行判断。
通义千问是阿里巴巴开源的一系列大语言模型。Qwen系列大模型最高参数量720亿,最低18亿,覆盖了非常多的范围,其各项评测效果也非常好。而昨天,Qwen团队的开发人员向HuggingFace的transformers库上提交了一段代码,包含了Qwen2的相关信息,这意味着Qwen2模型即将到来。

Batch Normalization(BN)是一种深度学习的layer(层)。它可以帮助神经网络模型加速训练,并同时使得模型变得更加稳定。尽管BN的效果很好,但是它的原理却依然没有十分清晰。本文总结一些相关的讨论,来帮助我们理解BN背后的原理。