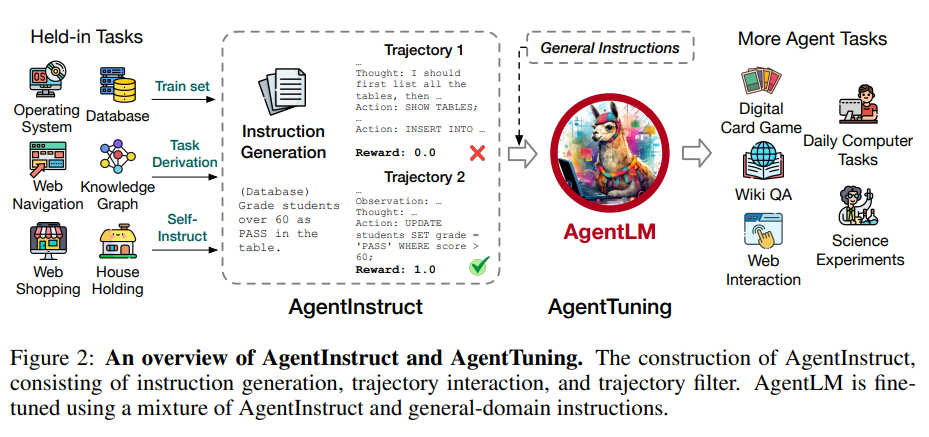
吴恩达宣布和OpenAI、LangChain、Lamini三家公司一起推出三门全新AI短视频课程:ChatGPT API、LangChain和Diffusion Models
今天,吴恩达在推特上宣布和OpenAI、LangChain以及Lamini三家公司共同推出了3门短视频课程,分别是《使用ChatGPT API构建系统》、《基于LangChain的大语言模型应用与开发》和《Diffusion模型是如何工作的》。三门课程都是1个小时的短视频课程,而且配有详细的Jupyter Notebook使用方法。