
重磅!PyTorch官宣2.0版本即将发布,最新torch.compile特性说明!
2022年的PyTorch Conference在新奥尔良举办。刚刚会上的keynote官宣PyTorch2.0版本即将到来。PyTorch是目前最流行的深度学习框架之一,它的易用性被广大的用户所喜爱。关于PyTorch2.0,官方透露了一些值得期待的特性。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
2022年的PyTorch Conference在新奥尔良举办。刚刚会上的keynote官宣PyTorch2.0版本即将到来。PyTorch是目前最流行的深度学习框架之一,它的易用性被广大的用户所喜爱。关于PyTorch2.0,官方透露了一些值得期待的特性。
Jupyter Notebook虽然在教学等领域有着非常大的优势,但是实际编程中,它的效率、可维护性等方面与python脚本相比的差距到底在哪也一直不那么清晰。就在上个月底,JetBrains的研究人员使用了大量的数据详细对比了二者的差异。这里总结一下其主要结论。


在七月初,ChatGLM-6B免费商用之后,ChatGLM2-6B宣布免费商用了!
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!

Python是目前最流行的编程语言,也是开放生态做得最好的编程语言之一。大多数深度学习框架、机器学习的框架都有很优秀的Python版本。这篇博客主要为大家介绍5个python生态系中解决NLP任务的框架。
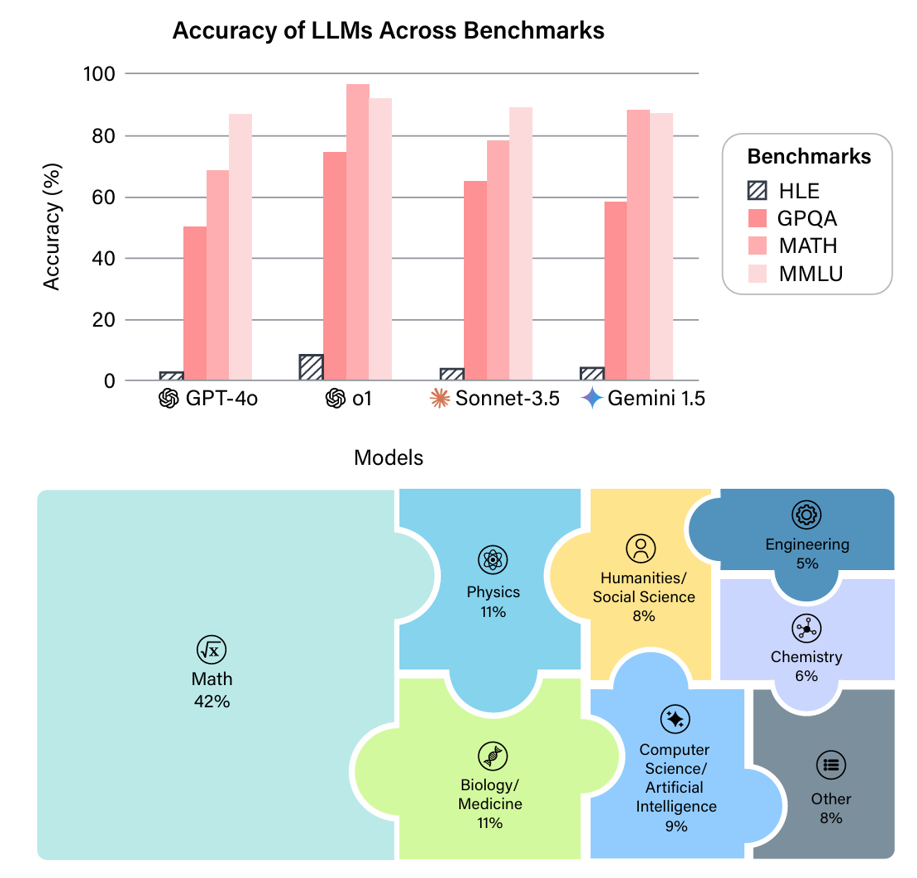
近年来,大语言模型(LLM)的能力飞速提升,但评测基准的发展却显得滞后。以广泛使用的MMLU(大规模多任务语言理解)为例,GPT-4、Claude等前沿模型已能在其90%以上的问题上取得高分。这种“评测饱和”现象导致研究者难以精准衡量模型在尖端知识领域的真实能力。为此,Safety for AI和Scale AI的研究人员推出了Humanity’s Last Exam大模型评测基准。这是一个全新的评测基准,旨在成为大模型“闭卷学术评测的终极考验”。
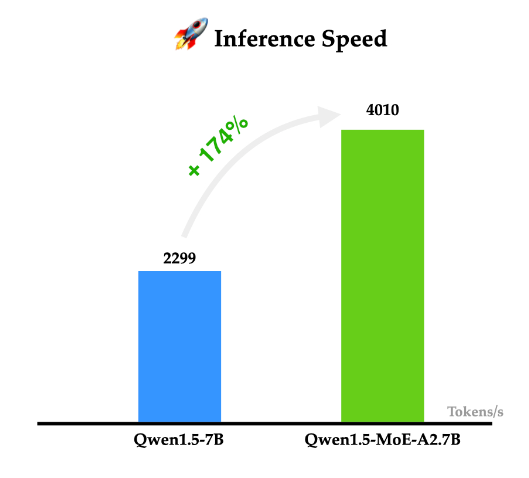
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
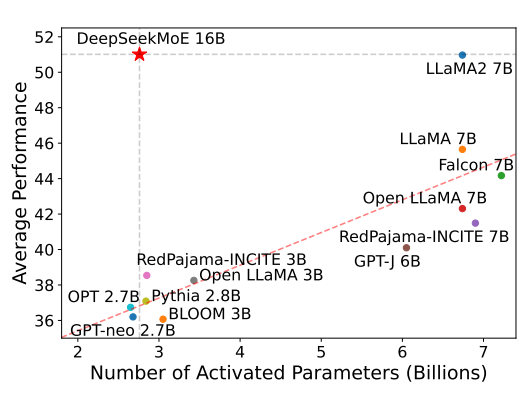
混合专家(Mixture of Experts)是大模型一种技术,这个技术将大模型划分为不同的子专家模型,每次推理只选择部分专家网络进行推理,在降低成本的同时保证模型的效果。此前Mistral开源的Mixtral-8×7B-MoE大模型被证明效果很好,推理速度很棒。而幻方量化旗下的DeepSeek刚刚开源了可能是国产第一个MoE技术的大模型,DeepSeek-MoE 16B。
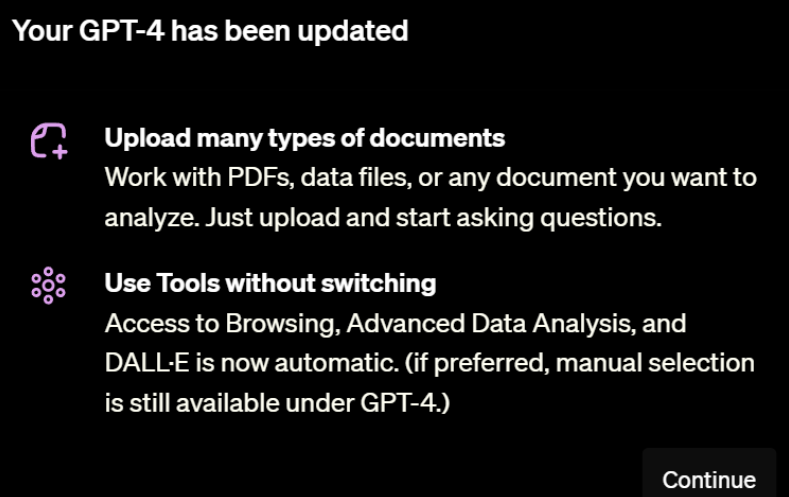
此前OpenAI的ChatGPT Plus版本为GPT-4模型提供了多个强大的插件供大家使用,包括基于Bing的带网络浏览的Browse、文本生成图片的DALL·E3、高级数据分析功能等。就在几个小时前,OpenAI的部分用户收到了官方的一个非常重磅的更新,即上传任意文档的分析以及整合了所有工具后的GPT-4!这个功能被称为GPT-4(All Tools)!这个工具可以在一次对话中自主选择调用多个不同工具完成用户的输入指令,非常接近AI Agent形态!

决定向量检索准确性的核心是向量大模型的能力,即文本转成embedding向量是否准确。今天,OpenAI宣布了他们第三代向量大模型text-embedding,模型能力增强的同时价格下降!
模拟登陆

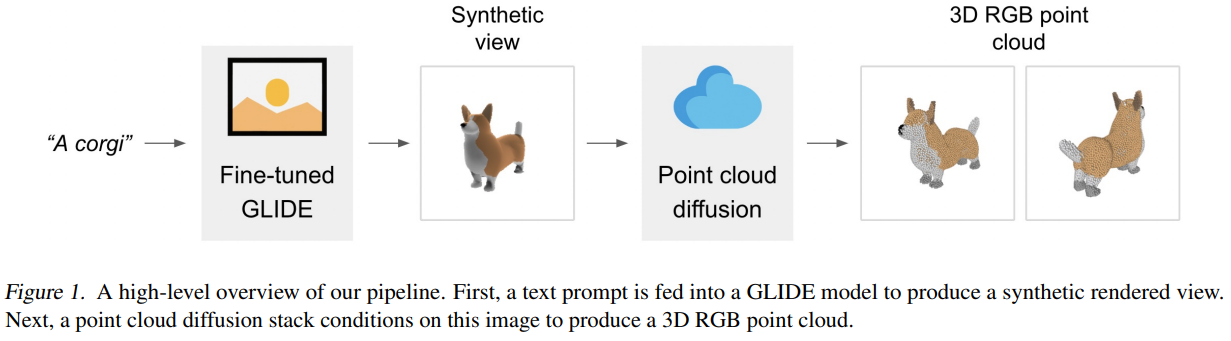
三维物体的生成(3D)其实是AR/VR领域一个非常重要的技术。但是,受限于算力和现有模型的限制,三维物体的生成相比较图像生成来说效率太低。目前,最好的图像生成模型在几秒钟就可以根据文字生成图像结果,但是3D物体的生成通常需要多个GPU小时才可以生成一个对象。为此,OpenAI在今天开源了一个速度极快的3D物体生成模型——Point-E,需要注意的是,这是今年来OpenAI罕见的源代码和预训练结果都开源的一个模型。

pandas是Python中一个非常重要的分析工具,在数据处理方面应用非常广泛。但是,也是因为pandas包含的操作很多,所以初学者很多时候也不能特别能理解这些操作。 为了让初学者能够充分理解pandas中的操作,Pandas Tutor将pandas的操作变成可视化的过程,让我们充分理解这个过程。

此前,OpenAI的CEO说今年等算力不那么紧张的时候就可以让大家微调OpenAI的GPT模型,现在这个功能已经发布了!OpenAI发布了GPT-3.5 Turbo的微调接口,允许大家用自己的数据微调GPT-3.5模型!