如何对向量大模型(embedding models)进行微调?几行代码实现相关原理
大语言模型是通过收集少量专门数据对模型的部分权重进行更新后得到一个比通用模型更加专业的模型。但是,当前大家讨论较多的都是语言模型的微调,对于嵌入模型(或者向量大模型)的微调讨论较少。Modal团队的工作人员发布了一个博客,详细介绍了向量大模型的微调工作,本文将其翻译之后提供给大家(原文:https://modal.com/blog/fine-tuning-embeddings )。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
大语言模型是通过收集少量专门数据对模型的部分权重进行更新后得到一个比通用模型更加专业的模型。但是,当前大家讨论较多的都是语言模型的微调,对于嵌入模型(或者向量大模型)的微调讨论较少。Modal团队的工作人员发布了一个博客,详细介绍了向量大模型的微调工作,本文将其翻译之后提供给大家(原文:https://modal.com/blog/fine-tuning-embeddings )。

Microsoft Visual C++ 14.0 is required
TensorFlow基本概念
Keras框架下的保存模型和加载模型

LiveCodeBench 由加州大学伯克利分校、麻省理工学院和康奈尔大学的研究人员开发,是一个先进的评测基准套件,专门用于严格评估大语言模型 (LLMs) 在代码处理方面的能力,并解决现有基准测试的局限性。通过引入实时更新的问题集和多维度评估方法,LiveCodeBench 确保对 LLM 进行公平、全面和稳健的评估。
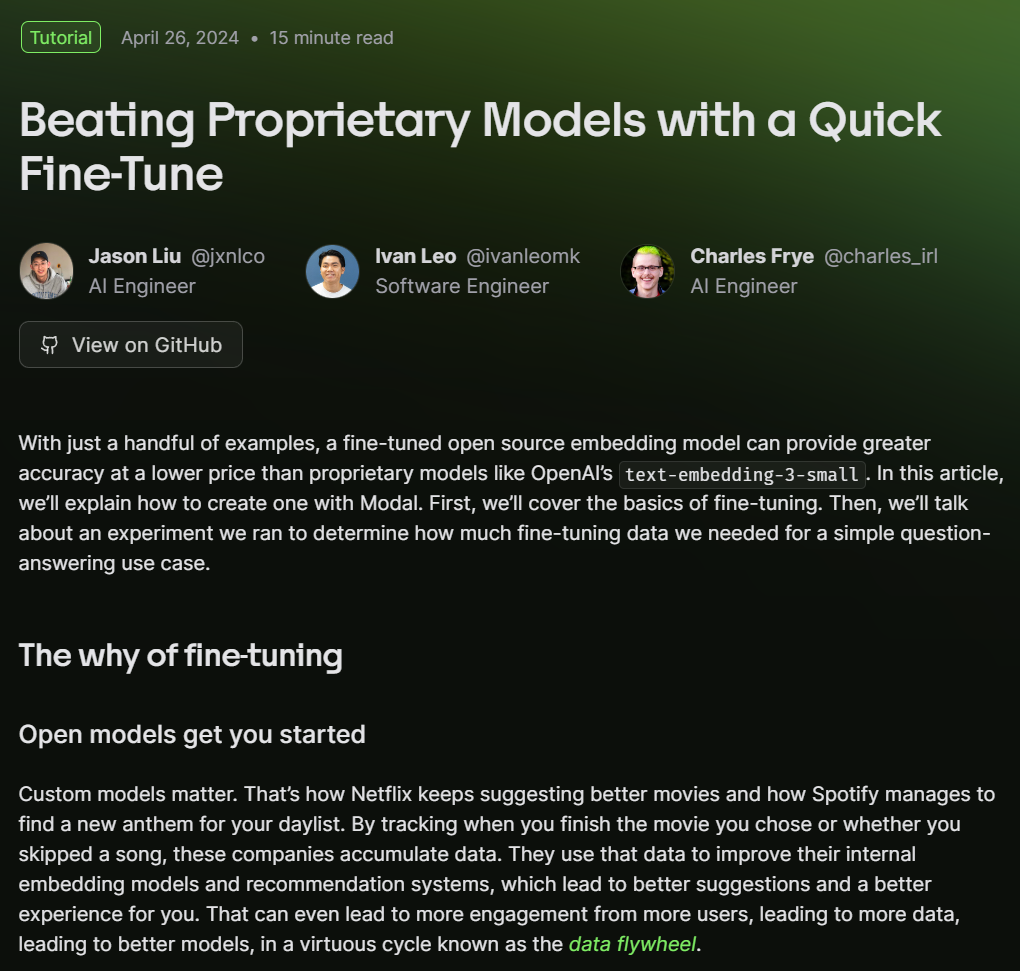
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
R语言操作数据库

马尔可夫链(Markov Chain)是由马尔可夫性质推导出来的一种重要的概率模型。马尔科夫链是一种离散时间的随机过程,作为现实世界的统计模型,有很多应用。在热力学、统计力学、排队理论、金融领域等都有重要的应用价值。 作为一种离散时间的随机过程,与其对应的模型是马尔可夫过程(Markov Process),这是一种连续时间随机过程的模型。本节将主要介绍马尔科夫链。
java 读写操作
hive的使用方法
原来直接用root账户授权远程访问失败,最新的MySQL8不允许直接创建并授权用户远程访问权限,必须先让自己有GRANT权限,然后创建用户,再授权。
深度学习本质上是表示学习,它通过多层非线性神经网络模型从底层特征中学习出对具体任务而言更有效的高级抽象特征。针对一个具体的任务,我们往往会遇到这种情况:需要用一个模型学习出特征表示,然后将学习出的特征表示作为另一个模型的输入。这就要求我们会获取模型中间层的输出,下面以具体代码形式介绍两种具体方法。
模型中的参数和超参数

德国的一位博士生开源了一个使用LoRA(Low Rank Adaptation)技术和PEFT(Parameter Efficient Fine Tuning)方法对Whisper模型进行高效微调的项目。可以让大家在消费级显卡(显存8GB)上对OpenAI开源的WhisperV2模型进行微调!

Git是一个版本控制系统,用来追踪计算机文件的变化的工具,也是一个供多人使用的协同工具。它是一个分布式的版本控制系统,本文将简单介绍如何使用。

数据结构中,自平衡二叉查找树搜索效率高,但是需要通过旋转和变色维护平衡。而列表虽然简单,但是对元素的查找需要比对列表中的每个元素,查找速度较慢。为了兼顾列表的简单易用,并提高查找效率,跳跃列表(Skip List)应运而生。
在使用Dask进行两个dataframe的concatenate操作的时候抛出ValueError,本文记录这个错误以及解决方案。
网络爬虫模拟登陆获取数据并解析实战
大语言模型训练的一个重要前提就是高质量超大规模的数据集。为了促进开源大模型生态的发展,Cerebras新发布了一个超大规模的文本数据集SlimPajama,SlimPajama可以作为大语言模型的训练数据集,具有很高的质量。除了SlimPajama数据集外,Cerebras此次还开源了处理原始数据的脚本,包括去重和预处理部分。官方认为,这是目前第一个开源处理万亿规模数据集的清理和MinHashLSH去重工具。
本文转自雷锋网,原文《通过从零开始实现一个感知机模型,我学到了这些》,作者:恒亮,文章转载已获授权。感知器(英语:Perceptron)是Frank Rosenblatt在1957年就职于Cornell航空实验室(Cornell Aeronautical Laboratory)时所发明的一种人工神经网络。它可以被视为一种最简单形式的前馈神经网络,是一种二元线性分类器。本文介绍了搭建感知机模型的基本操作也包含了作者的一些心得。