
网络爬虫中Json数据的解析
网络爬虫中Json数据的解析
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
网络爬虫中Json数据的解析
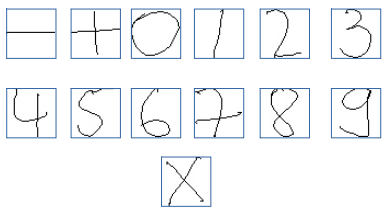
本文是发在Medium上的一篇博客:《Handwritten Equation Solver using Convolutional Neural Network》。本文是原文的翻译。这篇文章主要教大家如何使用keras训练手写字符的识别,并保存训练好的模型到本地,以及未来如何调用保存到模型来预测。

Dask的集群启动创建也很简单,有好几种方式,最简单的是采用官方提供dask-scheduler和dask-worker命令行方式。本文描述如何使用命令行方法建立Dask集群。
GGML是在大模型领域常见的一种文件格式。HuggingFace上著名的开发者Tom Jobbins经常发布带有GGML名称字样的大模型。通常是模型名+GGML后缀,那么这个名字的模型是什么?GGML格式的文件名的大模型是什么样的大模型格式?如何使用?本文将简单介绍。
使用eclipse打包java工程并导出java包
Sequence-to-Sequence model

Java多线程网络爬虫(时光网为例)
看过很多书,都说了神经网络的进展,但总有一些小问题没有明白。这次基本上都明白了,记录一下。
这篇博客主要翻译自Gregor Heinrich的技术博客Parameter estimation for text analysis,介绍极大似然估计、极大后验估计和贝叶斯参数估计的原理和案例
221
MySQL支持对文本进行全文检索,全文检索可以类似搜索引擎的功能,相比较模糊匹配更加灵活高效且更快。MySQL5.7之后也支持对中文的全文检索,这里描述如何启用MySQL的中文全文检索。
我出生在一个不大不小的南方城市,那里纵横着大大小小的巷子,而通往我记忆深处的是寺巷子。

SVN是Subversion的简称,是一个开放源代码的版本控制系统,相较于RCS、CVS,它采用了分支管理系统,它的设计目标就是取代CVS。互联网上很多版本控制服务已从CVS迁移到Subversion。说得简单一点SVN就是用于多个人共同开发同一个项目,共用资源的目的。

自从Hadoop生态发展以来,基于开源软件提供服务的盈利公司也越来越多。大家这才发现,开源不仅不会削弱企业竞争力,还可以带来生态,增强企业的竞争力。本文总结全球最挣钱的十大开源公司供大家参考。
从问题定义,到数据获取以及模型选择调参,这篇博客指出了每个过程中需要注意的问题

这是来自AnalyticsVidhya的Pranav Dar的帖子
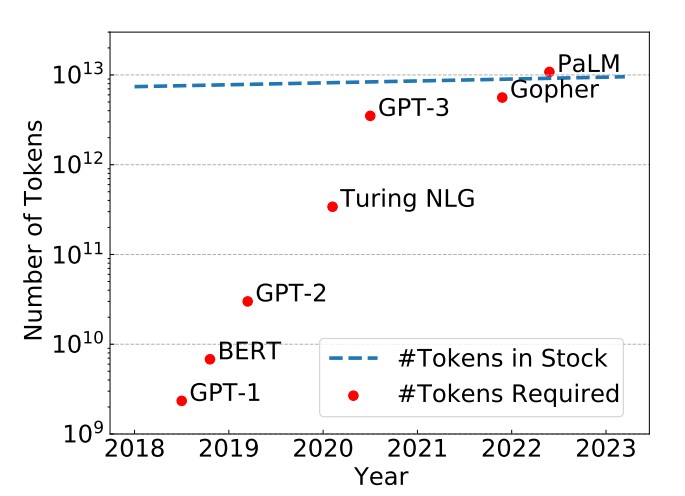
epoch是一个重要的深度学习概念,它指的是模型训练过程中完成的一次全体训练样本的全部训练迭代。然而,在LLM时代,很多模型的epoch只有1次或者几次。这似乎与我们之前理解的模型训练充分有不一致。那么,为什么这些大语言模型的epoch次数都很少。如果我们自己训练大语言模型,那么epoch次数设置为1是否足够,我们是否需要更多的训练?
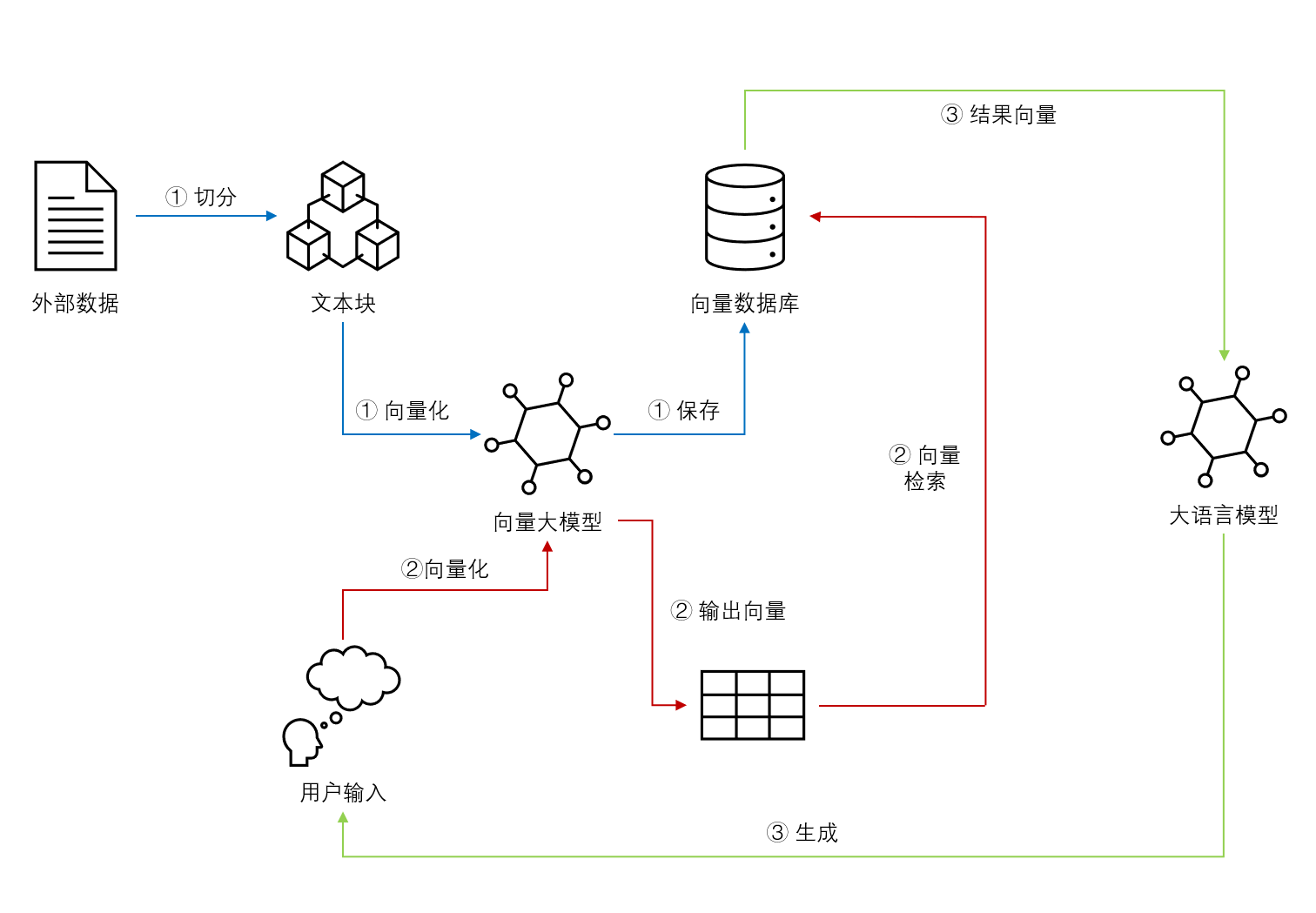
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。
端到端(end-to-end)学习