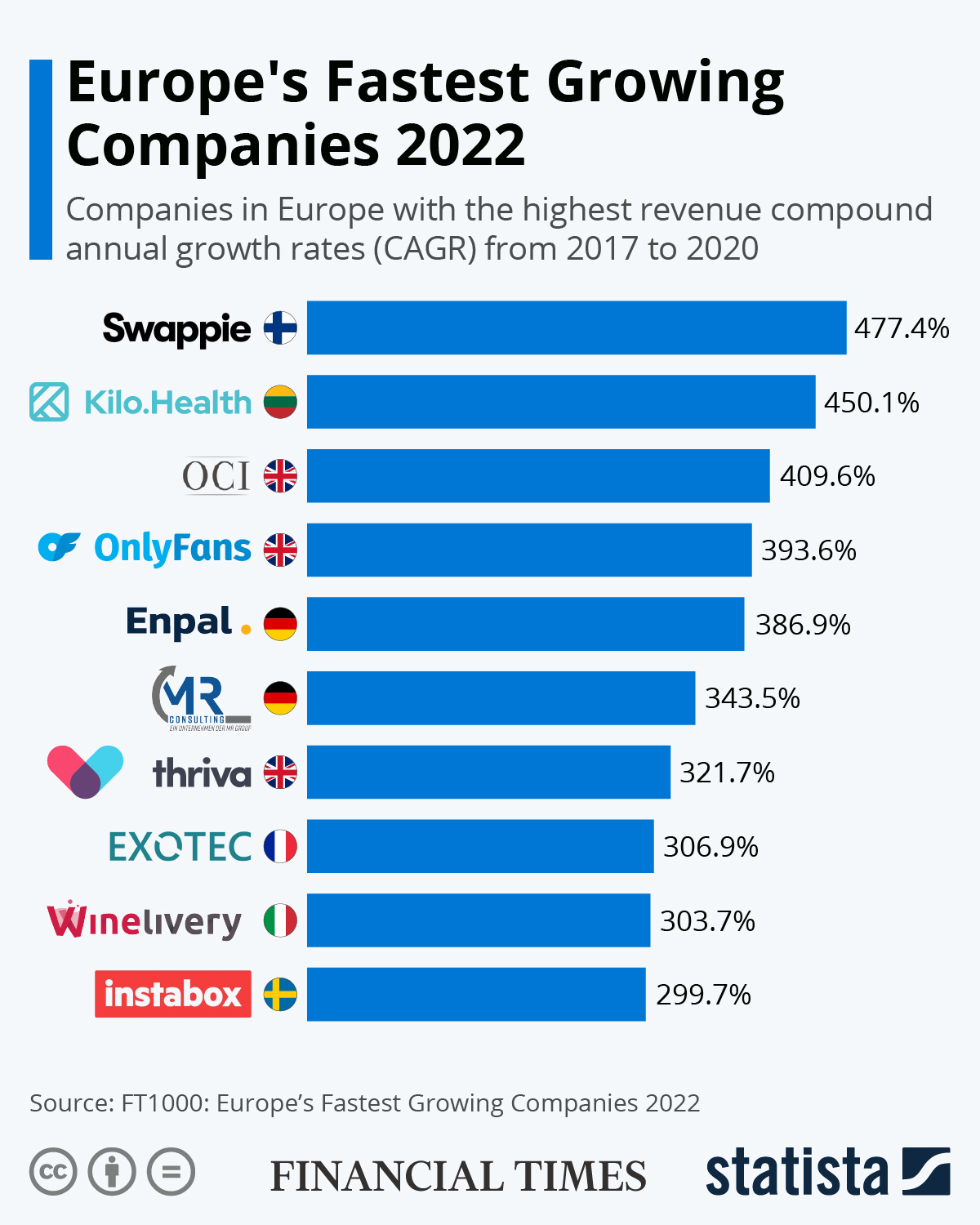
ChatGPT颠覆更新!即将发布的ChatGPT新版本带来巨变,新界面和可以自定义GPT-4功能:可以对接私有数据与私有接口的个性化ChatGPT即将到来!
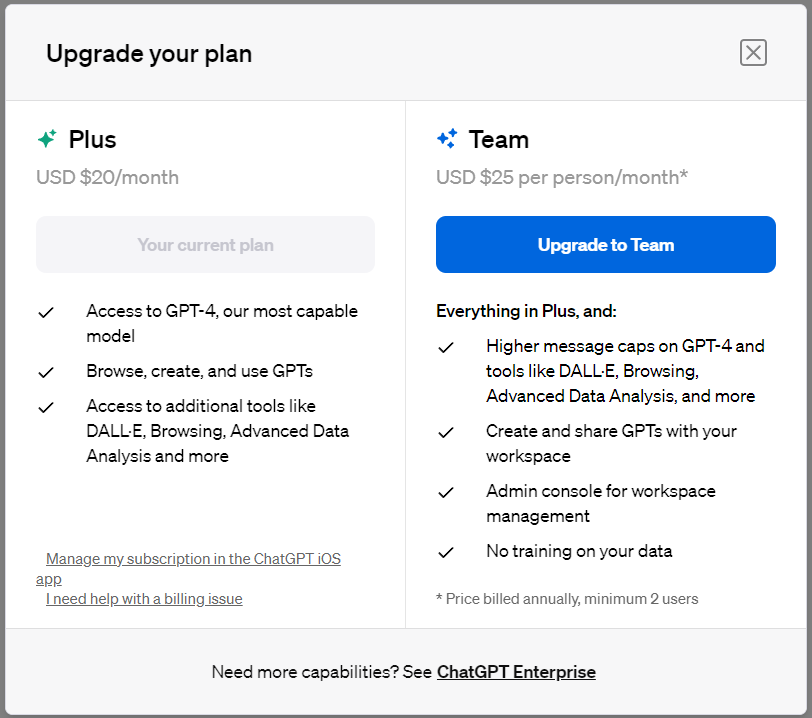
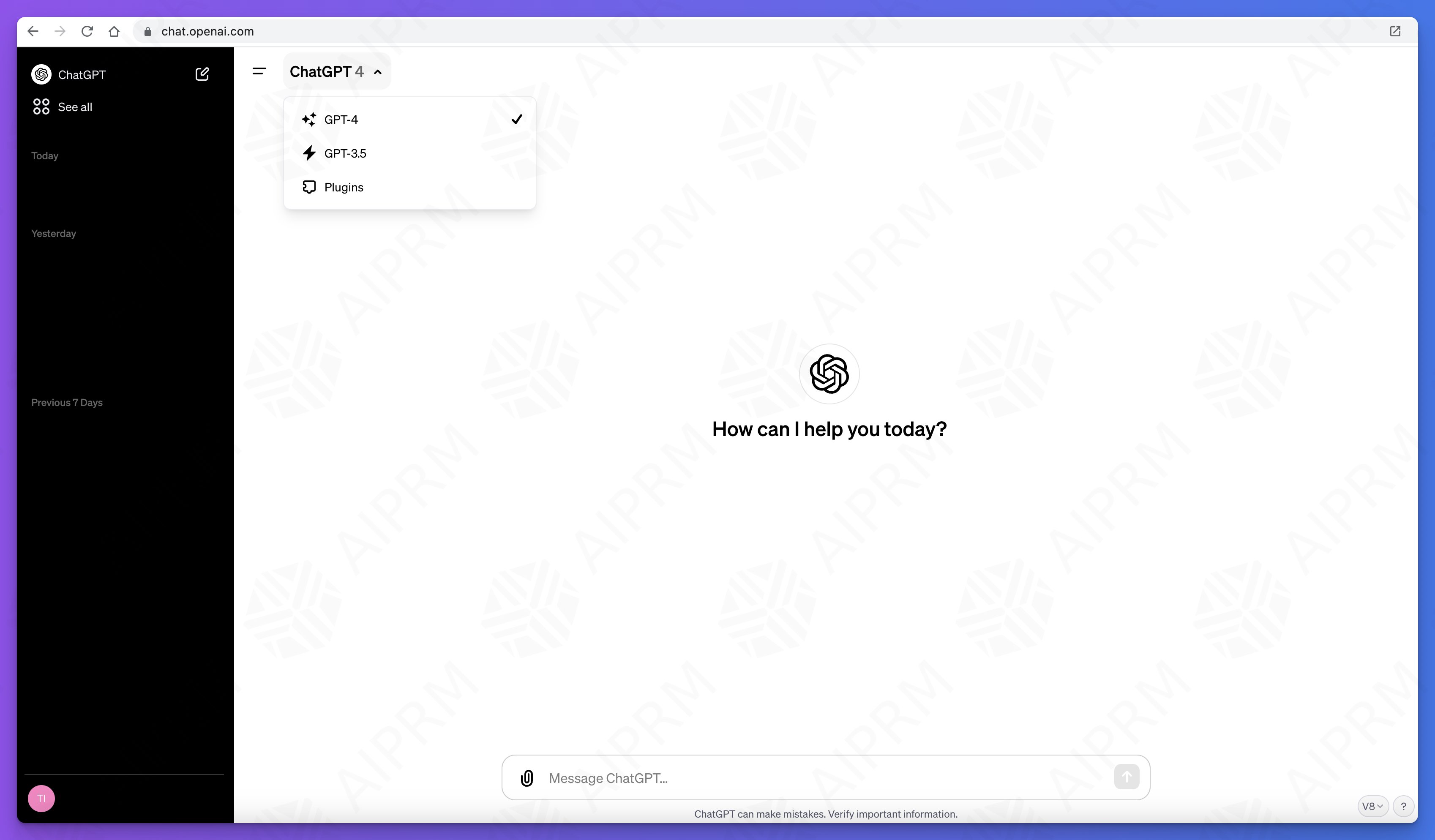
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!