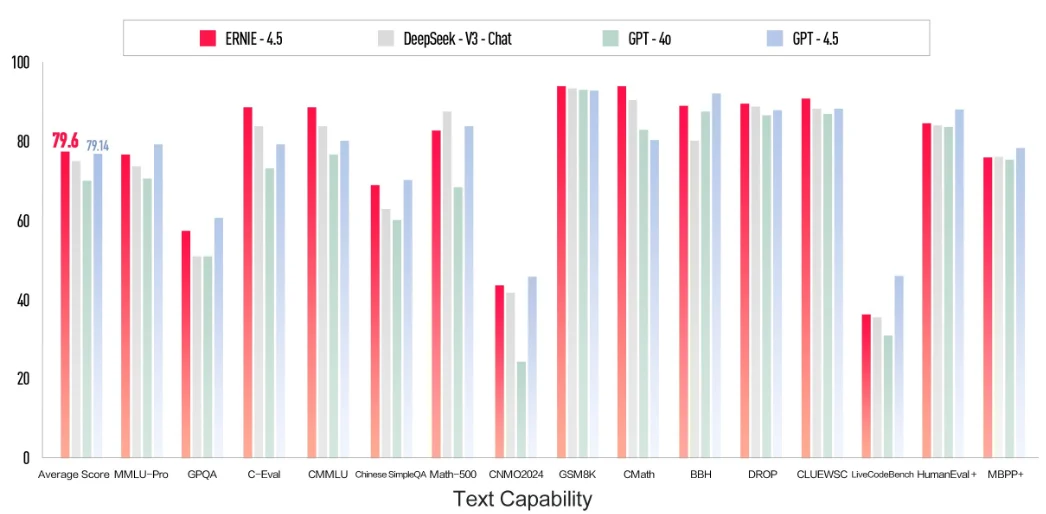
百度在周末发布了2个新一代文心一言大模型,分别是没有推理能力的ERNIE 4.5以及有推理能力的ERNIE X1,即日起可以免费使用
3月16日,百度宣布推出两款新一代文心大模型——ERNIE 4.5与ERNIE X1,并提前向公众免费开放其智能对话平台“文心一言”(ERNIE Bot)。官方宣称,这两款模型的能力均超过了GPT-4o,但是价格只有GPT-4o的1%,且是DeepSeek的一半。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
3月16日,百度宣布推出两款新一代文心大模型——ERNIE 4.5与ERNIE X1,并提前向公众免费开放其智能对话平台“文心一言”(ERNIE Bot)。官方宣称,这两款模型的能力均超过了GPT-4o,但是价格只有GPT-4o的1%,且是DeepSeek的一半。

7月28日,智谱AI(Zhipu AI)向开源社区投下了一枚重磅炸弹,正式发布了其最新的旗舰模型系列:GLM-4.5。该系列包含两个新成员——GLM-4.5和GLM-4.5-Air,两者均以开源权重形式提供。官方技术报告详细阐述了其设计理念、技术细节以及在多项基准测试中的表现。本次发布的核心目标是打造一个能够统一推理、代码和Agent智能体能力的模型,以应对日益复杂的AI应用需求。本文将深入解析这份官方报告,剖析其核心技术、性能表现,并探讨其在当前大模型竞争格局中的战略定位。
就在刚刚,MetaAI发布了全新一代Llama4大模型,Llama正式进入多模态和MoE架构时代。本次新发布的是Llama4中的2个模型分别是Llama4 Scout和Llama4 Maverick。这两个模型都是170亿激活参数,但是前者共16个专家,后者有128个专家,因此总的参数量分别达到了1090亿和4000亿!不过根据评测的情况看,即使是4000亿规模170亿激活的模型,也和DeepSeek V3.1(即DeepSeek V3 0324)版本差不多。

上周,MoonshotAI 发布了 Kimi K2,并宣布 完全开源、允许商用。发布 24 小时内,社区即完成了 MLX 移植、4-bit 量化等后续工作。外网很多人评价说,Kimi K2是另一个DeepSeek R1时刻。本文尝试以第三方视角,把Kimi开发者公开的技术讨论、社区疑问与公开配置里的数字串成一条完整的技术决策链,解释Kimi K2背后的技术决策以及他们眼中大模型创业企业的方向。

MLOps的主要目标是创建一个更有效、可重复和可靠的机器学习工作流程。现在,随着大语言模型的流行,LLMOps概念也随之提出。即如何高效地开发大模型应用,包括自动化管理升级如prompt、模型评估等。为此,吴恩达联合Google的研发人员推出了最新的大模型短课LLMOps,帮助大家学习大语言模型开发过程中的自动化测试、自动化Prompt管理等一系列实践,提高大模型应用开发的效率和质量。
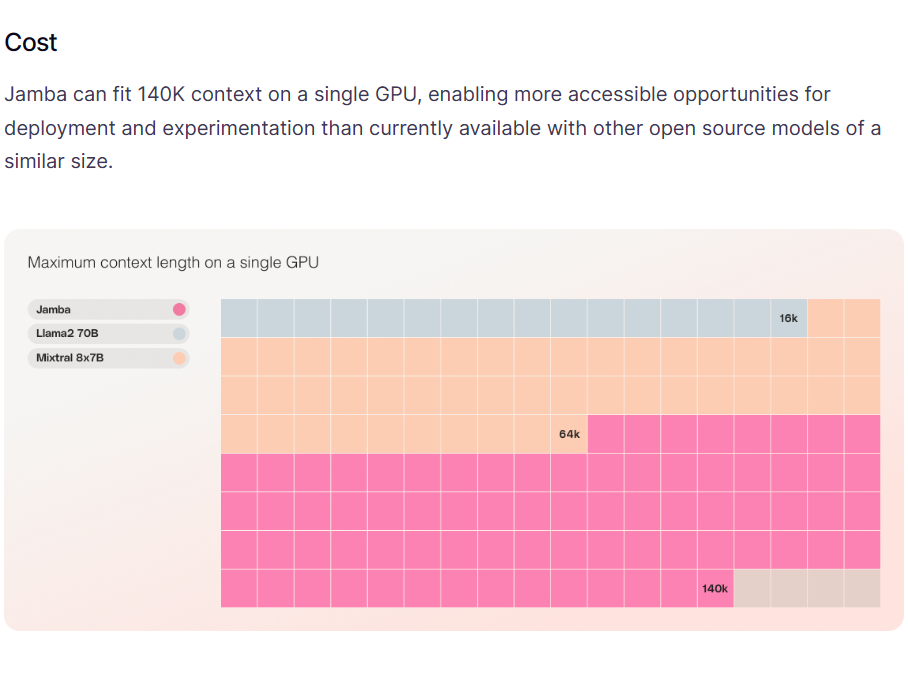
A21实验室是一家以色列的大模型研究机构,专门从事自然语言处理相关的研究。就在今天,A21实验室开源了一个全新的基于混合专家的的大语言模型Jamba,这个MoE模型可以在单个GPU上支持最高140K上下文的输入,非常具有吸引力。

上周五,OpenAI董事会突然把Sam开除的事件已经结束,闹了好几天之后Sam回归,董事会改组。而这件事的背后导火索有许多传闻,其中最重要的一个是OpenAI可能在最近有一项重大的技术突破,被认为是Sam和董事会分歧的重要原因。而今天,国外的路透社独家消息提到OpenAI内部一个称为Q\*(Q Star)项目取得了非常重大的突破,使得部分人认为AGI很接近,进而引发了一系列事件。本文将根据目前的信息汇总介绍一下Q\*项目。

就在刚才,阿里开源了Qwen Image大模型,这是阿里千问团队开源的高质量图片生成和编辑的大模型。这份发布迅速在AI社区引起了广泛关注,其核心并非又一个单纯追求图像美学或真实感的模型,而是直指一个长期存在的行业痛点:在图像中进行复杂、精准、尤其是高保真的多语言文本渲染。

智谱AI开源了一个60亿参数规模的文生图大模型CogView4-6B,支持生成的图像中加入文字,文字效果自然融入图像中,且该模型支持支持宽高范围512px至2048px内的任意尺寸图像(有限制,正文解释)。

今天,Google发布Gemini 2.5 Flash Lite。这是一款专为追求极致速度、超低延迟和高性价比场景打造的轻量级模型。它的发布标志着 Google 正在将旗舰模型的先进能力(如百万级上下文、原生多模态、工具调用等)逐步下放到更轻量、更经济的模型层级。根据 DataLearnerAI 的实测,这款模型的生成速度最高可达 400 tokens/秒,即使在输入达到 18K tokens 的情况下,也依然可以维持在 160+ tokens/秒 的性能表现,令人惊喜。
今天The Information独家披露了一个令人兴奋的消息,那就是OpenAI正在开发一种Agent产品,可以通过控制用户的设备来帮助用户完成复杂的任务。
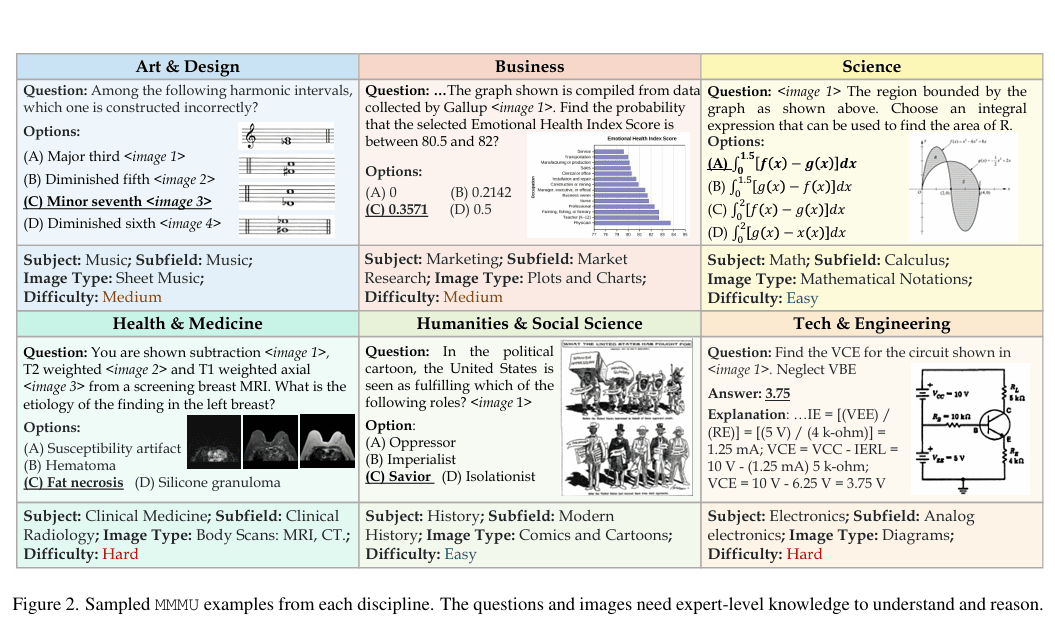
大规模多学科多模态理解与推理基准(MMMU)于2023年11月推出,是一种用于评估多模态模型的复杂工具。该基准测试人工智能系统在需要大学水平学科知识和深思熟虑推理的任务上的能力。与之前的基准不同,MMMU强调跨多个领域的先进感知和推理,旨在衡量朝专家级人工智能通用智能(AGI)的进展。
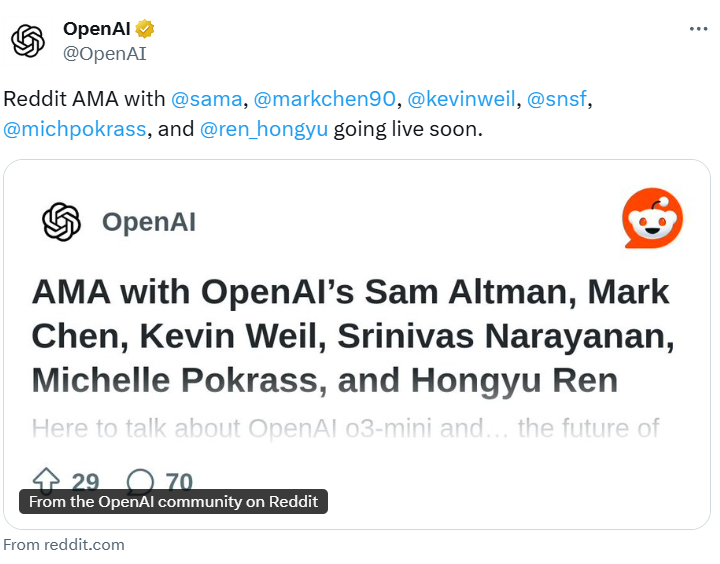
2025年1月31日,OpenAI在Reddit上举办了一场AMA(Ask Me Anything)活动,参与者包括Sam Altman、Mark Chen、Kevin Weil、Srinivas Narayanan、Michelle Pokrass和Hongyu Ren。他们分享了关于模型更新、未来功能、定价策略以及OpenAI对AI和AGI(通用人工智能)的宏观愿景。以下是此次问答的关键内容,并附有相关解释。这里最重要的信息可能是Sam透露认为当前OpenAI的闭源方式可能是历史错误的一方!

OpenAI 于 2025 年 2 月 27 日发布了 GPT-4.5,作为其语言模型系列的最新版本。尽管具体的技术细节因商业保密而未完全公开,基于现有信息和合理推测,DataLearner提供更具体的数据和分析,同时补充更多来自用户的评价。

在人工智能领域,Mistral与NVIDIA的合作带来了一个引人注目的新型大模型——Mistral NeMo。这个拥有120亿参数的模型不仅性能卓越,还为AI的普及和应用创新铺平了道路。MistralAI官方博客介绍说该模型是此前开源的Mistral 7B模型的继承者,因此未来可能7B不会再继续演进了!

MiniMaxAI于2025年6月17日正式发布了其新一代大模型——MiniMax-M1。MiniMax-M1的核心亮点在于结合了混合专家(MoE)架构和创新的闪电注意力(Lightning Attention)机制。MiniMax-M1不仅原生支持高达100万Token的上下文长度,推理的tokens也支持最高80K,是当前支持的最多推理长度的大模型。此外,MiniMax-M1在计算效率上也很高,例如在生成10万Token时,其FLOPs消耗仅为DeepSeek R1的25%!
在大模型的应用中,处理复杂请求往往伴随着较高的延迟和成本,尤其是当请求内容存在大量重复部分时。这种“慢请求”的问题,特别是在长提示和高频交互的场景中,显得尤为突出。为了应对这一挑战,OpenAI 最近推出了 **提示缓存(Prompt Caching)** 功能。这项新技术通过缓存模型处理过的相同前缀部分,避免了重复计算,从而大幅减少了请求的响应时间和相关成本。特别是对于包含静态内容的长提示请求,提示缓存能够显著提高效率,降低运行开销。本文将详细介绍这项功能的工作原理、支持的模型,以及如何通过合理的提示结

继Gemma系列模型发布并迅速形成超过1.6亿次下载的繁荣生态后,Google再次推出了其在端侧AI领域的重磅力作——Gemma 3n。这款模型并非一次简单的迭代,而是基于全新的移动优先(mobile-first)架构,旨在为开发者提供前所未有的设备端多模态处理能力。Gemma 3n的定位是成为一款高效、强大且灵活的开源模型,直接与设备端AI领域的其他先进模型(如Phi-4、Llama系列的小参数版本)竞争,其核心特性在于原生支持图像、音频、视频和文本输入。

就在几个小时前,DeepSeekAI宣布官方的聊天模型从DeepSeek-V3升级到了DeepSeek-V3.1,上下文拓展至128K。虽然,官方目前没有给出这个模型的详细信息,DataLearnerAI已经搜集到很多信息供大家参考。

今天,百度正式宣布开源其最新的旗舰级大模型系列——ERNIE 4.5。ERNIE 4.5系列模型当前包含2个多模态大模型,4个大语言模型及其不同变体的庞大家族,还区分了PyTorch版本和paddlepaddle版本,共23个模型,其核心采用了创新的异构多模态混合专家(MoE)架构,在提升多模态理解能力的同时,实现了文本处理性能的同步增强。每个版本的模型都开源了基座(Base)版本和后训练版本(不带Base)。
近日,OpenAI在发布其开源模型gpt-oss-120b和gpt-oss-20b的同时,也推出了一种专为这些模型设计的全新消息格式——Harmony。对于希望在自有解决方案中充分利用这些开源模型的开发者而言,理解Harmony至关重要。本文将以客观的第三方视角,详细解析Harmony格式的设计理念与技术细节。

微软发布了全新的Phi-4推理模型系列,是小型语言模型(SLM)在复杂推理能力上的一种新的尝试。本次发布包含三个不同规模和性能的推理模型,分别是Phi-4-reasoning(140亿参数)、Phi-4-reasoning-plus(增强版140亿参数)和Phi-4-Mini-Reasoning(38亿参数)。这三款模型尽管参数规模远小于当前主流大型语言模型,却在多项推理基准测试中展现出与甚至超越大型模型的能力。
Terminal-Bench是一个新兴的开源基准测试,专为评估人工智能Agent(AI Agent)在命令行终端环境中的实际操作能力而设计。它通过一系列模拟真实世界场景的复杂任务,旨在客观、可量化地衡量AI Agent在执行代码编译、服务器管理和数据处理等任务时的熟练程度与自主性。

昨天,Anthropic公布了一项引人注目的实验——Project Vend。他们让旗下的大模型Claude Sonnet 3.7在一个真实的办公环境中,自主经营一家小型自动化商店,为期约一个月。这个实验的目标是探索,在不久的将来,AI模型在真实经济体中自主运行任务的可行性、潜在的成功模式以及那些出人意料的失败方式。实验结果非常强大,也充满了令人深思的细节!