
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




在深度学习和计算机视觉的发展历程中,视频生成技术一直是一个极具挑战和创新的领域。而发布了一系列开源领域最强图像生成模型Stable Diffusion系列模型背后的企业StabilityAI最近又开源了一个的文本生成视频大模型Stable Video Diffusion模型,这个模型可以生成最多20帧的视频。测试效果,这个模型普通版本与runway差不多,20帧版本则超过了runway!

自从2019年OpenAI开始商业化以来,OpenAI的成果越来越封闭,而商业化的进程越来越快。GPT系列的发展正好印证了这个路径。GPT最初的版本包含了论文、代码和预训练结果。GPT-2刚开始也认为可能会造成不好的伤害而在论文官宣了大半年之后才公布了完整模型。到GPT-3的时候也就给了官方介绍博客和论文,模型则是彻底闭源且开始商业化。而今天OpenAI直接官方博客宣布GPT-3.5商业化,连论文都没有了!

xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。xAI今天也宣布了Grok模型的细节。其在多个知名榜单评测上的得分结果超过了ChatGPT-3.5水平。本文详细介绍一下这个模型。

文中整理和总结了几个关于开源大模型微调方面的问题,答案主要来自gpt4 + google,如果其中部分问题的答案不准确,烦劳指正 (文中引用了外部资源链接,如果涉及版权问题,烦劳联系作者删除)

大家都知道,编程的开发离不开互联网的支持,不管是编程的学习还是bug的修复,都需要社区和外部的支持。因此,我们全新开通了一个程序必备网站列表栏目,为大家提供一站式访问目录。也欢迎评论,大家可以说一下你们写代码时候喜欢用的网站,我们也会更新上去。在这里我们挑选几个必备网站简单介绍一下。

Mistral-7B是由MistralAI开源的一个73亿参数规模的大语言模型,最早在2023年9月底开源。因为其良好的性能和友好的开源协议被很多人使用。今天,这个模型升级到来v0.2版本Mistral-7B-v0.2。基于Mistral-7B-v0.2进行指令微调的模型 Mistral-7B-Instruct-v0.2在2023年11月11日公布,而这个基座模型则是在2023年3月24日开源。
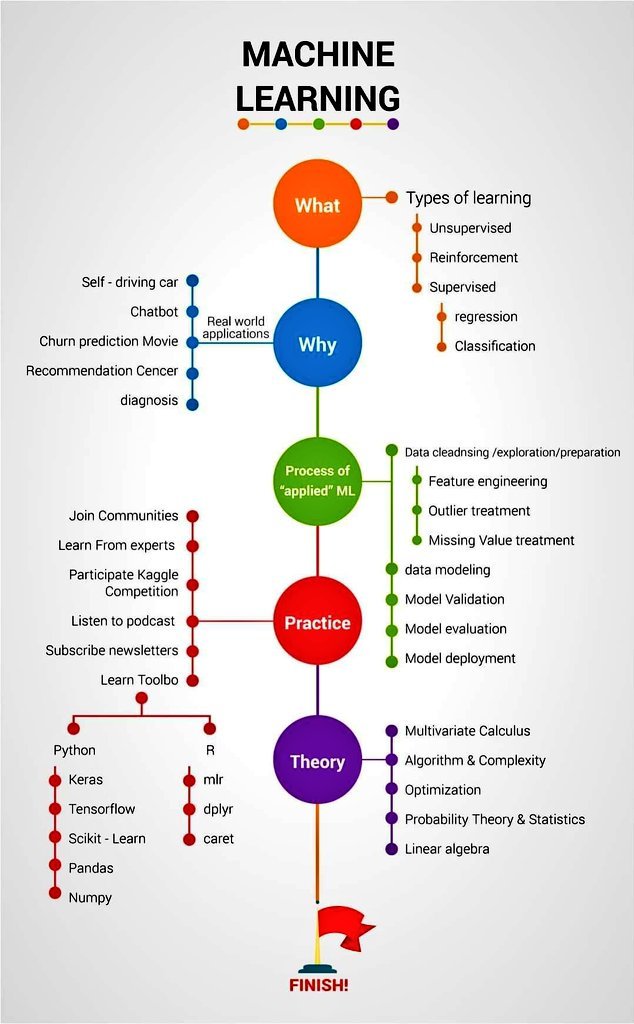
这是推特上Ternium的CIO发的一个图,关于机器学习理论和实践概念的信息图。这个图概括了机器学习实践流程的相关概念,简洁明了。对于入门的同学有很好的总结作用。
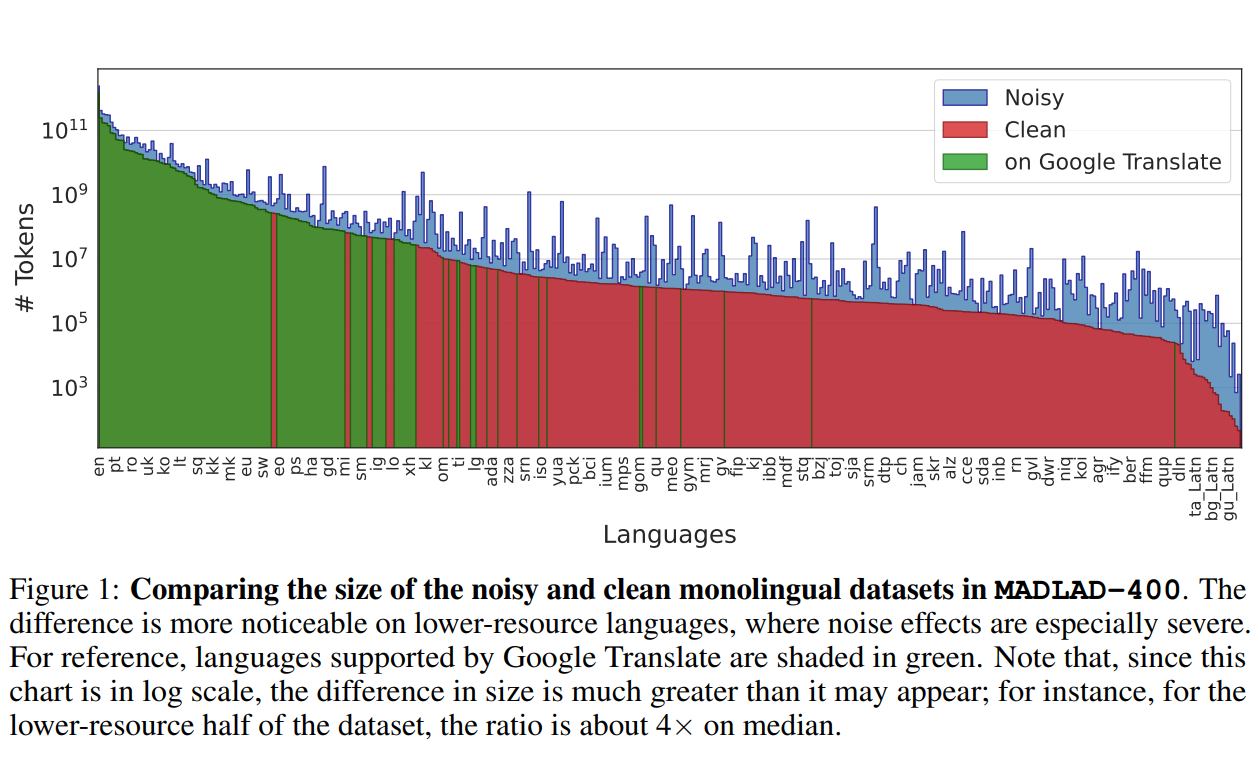
Google DeepMind与Google Research的研究人员推出了一个全新的多语言数据集——MADLAD-400!这个数据集汇集了来自全球互联网的419种语言的大量文本数据,其规模和语言覆盖范围在公开可用的多语言数据集中应该是最大的。研究人员从Common Crawl这个庞大的网页爬虫项目中提取了大量数据,并进行了人工审核,删除了许多噪音,使数据集的质量得到了显著提升。
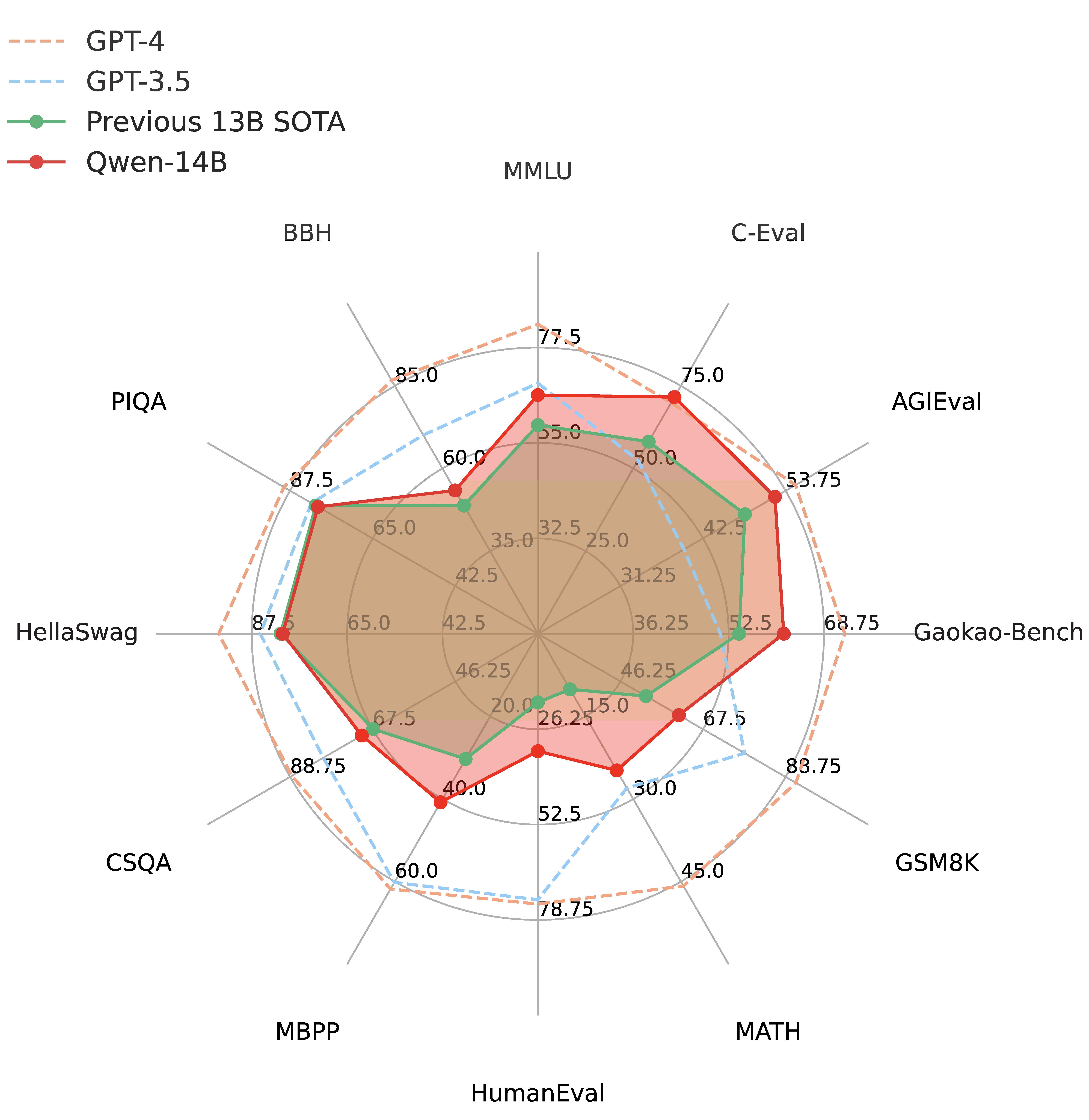
通义千问是阿里巴巴推出的一个大语言模型,此前开源的Qwen-7B引起了广泛的关注,因为他的理解能力很强但是参数规模很小,因此受到了很多人的欢迎。而目前再次开源全新的Qwen-14B的模型,参数规模142亿,但是它的理解能力接近700亿参数规模的LLaMA2-70B,数学推理能力超过GPT-3.5。
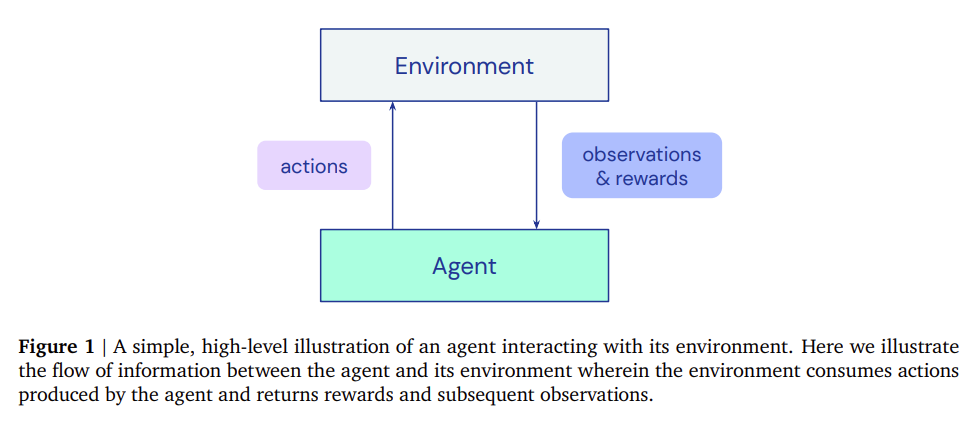
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的

今天Google发布了TensorStore,这是一个开源的C++和Python软件库,设计用于存储和操作大规模n维数据。TensorStore已经被用来解决科学计算中的关键工程挑战(例如,管理和处理神经科学中的大型数据集,如石油级的三维电子显微镜数据和神经元活动的 "4d "视频)。TensorStore还被用于创建大规模的机器学习模型,如PaLM,解决了分布式训练期间管理模型参数(检查点)的问题。
自然语言处理预训练大模型在最近几年十分流行,如OpenAI的GPT-3模型,在很多领域都取得了十分优异的性能。谷歌的PaLM也在很多自然语言处理模型中获得了很好的效果。而昨天,PapersWithCode发布了一个学术论文处理领域预训练大模型GALACTICA。功能十分强大,是科研人员的好福利!

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。
很多算法的开源实现都包含多个文件,因此,学习这些开源代码的时候通常难以找到入口,也无法快速理解作者的逻辑,对于学习的童鞋来说都带来了不小的挑战。这里推荐一个非常优秀的强化学习开源库,它将经典的强化学习算法都实现在一个文件中,想要学习源代码的童鞋只需要看单个文件即可,这就是ClearRL!

Anthropic是一家专注于人工智能(AI)研究的公司,由OpenAI的前首席科学家Ilya Sutskever和Dario Amodei共同创立。Claude是Anthropic公司发布的基于transformer架构的大语言模型,被认为是最接近ChatGPT的商业产品。今天,Anthropic宣布Claude 2正式开始上架。
今日推荐
【转载】全面解读ICML 2017五大研究热点 | 腾讯AI Lab独家解析
OpenAI CEO详解今明两年GPT发展计划:10万美元部署私有ChatGPT、最高支持100万tokens、建立微调模型应用市场
Anthropic的Claude 4即将发布前新功能曝光:带有Thinking模式,且可以看到推理过程
Hugging Face发布最新的深度学习模型评估库Evaluate!
OpenAI官方教程:如何针对大模型微调以及微调后模型出现的常见问题分析和解决思路~以GPT-3.5微调为例
微软发布大语言模型与传统编程语言的集成编程框架——Python版本的Semantic Kernel今日发布
没有显卡也没关系!基于Google Colab免费GPU额度部署Stable Diffusion XL模型,可以生成4K的图!