
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



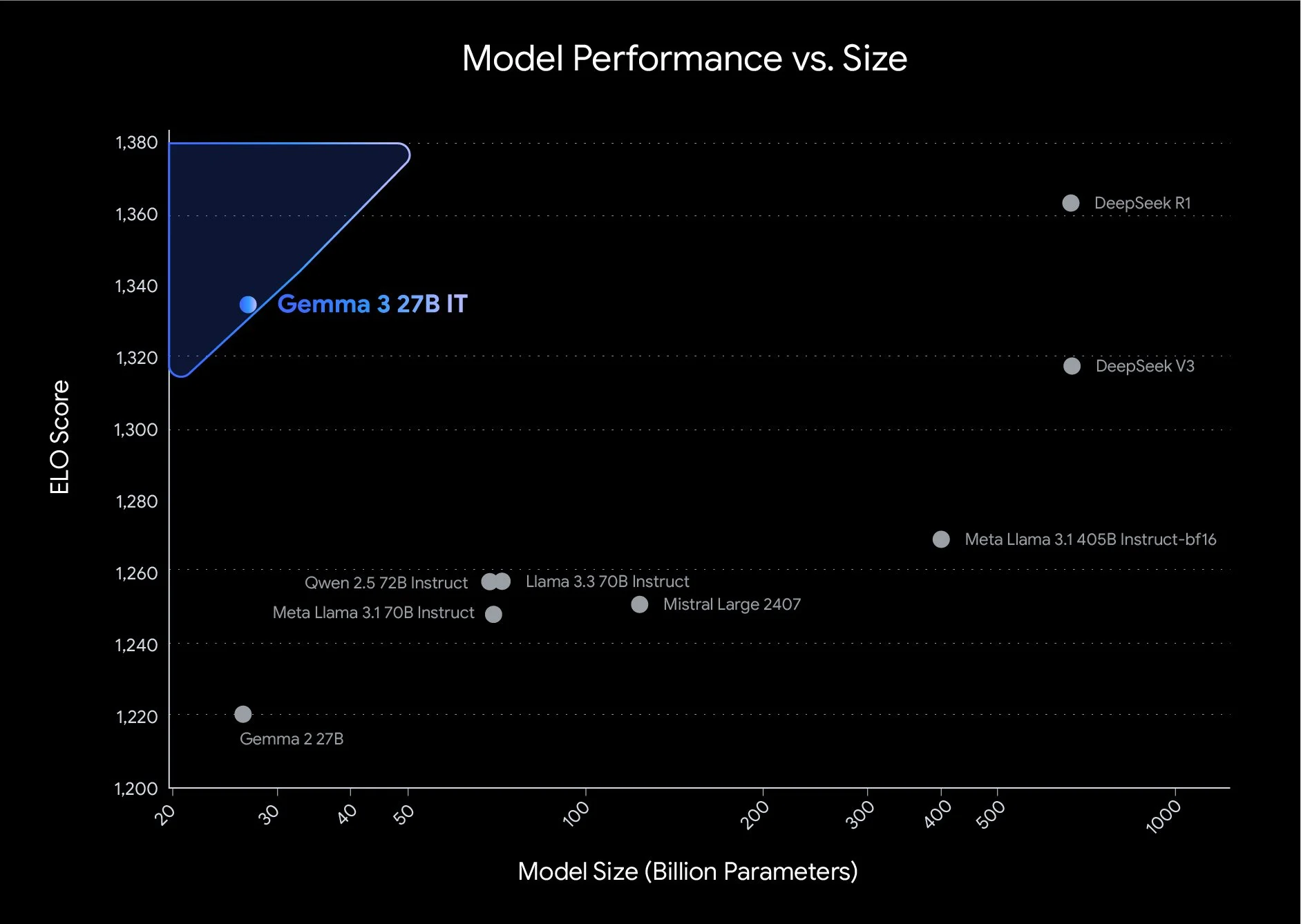
Gemma系列大模型是Google开源的一系列轻量级的大模型。就在刚才(2025年3月12日),Google开源了第三代Gemma系列大模型,共包含4个不同参数规模版本,第三代的Gemma 3系列是多模态大模型,即使是最小的10亿参数规模的Gemma 3-1B也支持多模态输入。

大模型微调依然是针对大量私有数据或者特定领域不可缺少的方法。就在前不久,LightningAI发布了一个轻量级大模型微调库Lit-Parrot,仅需一行代码即可微调当前开源大模型。

前几天初创AI企业Nebuly开源了一个AI加速库nebulgym,它最大的特点是不更改你现有AI模型的代码,但是可以将训练速度提升2倍。

零一万物(01.AI)是由李开复在2023年3月份创办的一家大模型创业企业,并在2023年6月份正式开始运营。在2023年11月6日,零一万物开源了4个大语言模型,包括Yi-6B、Yi-6B-200K、Yi-34B、Yi-34B-200k。模型在MMLU的评分上登顶,最高支持200K超长上下文输入,获得了社区的广泛关注。
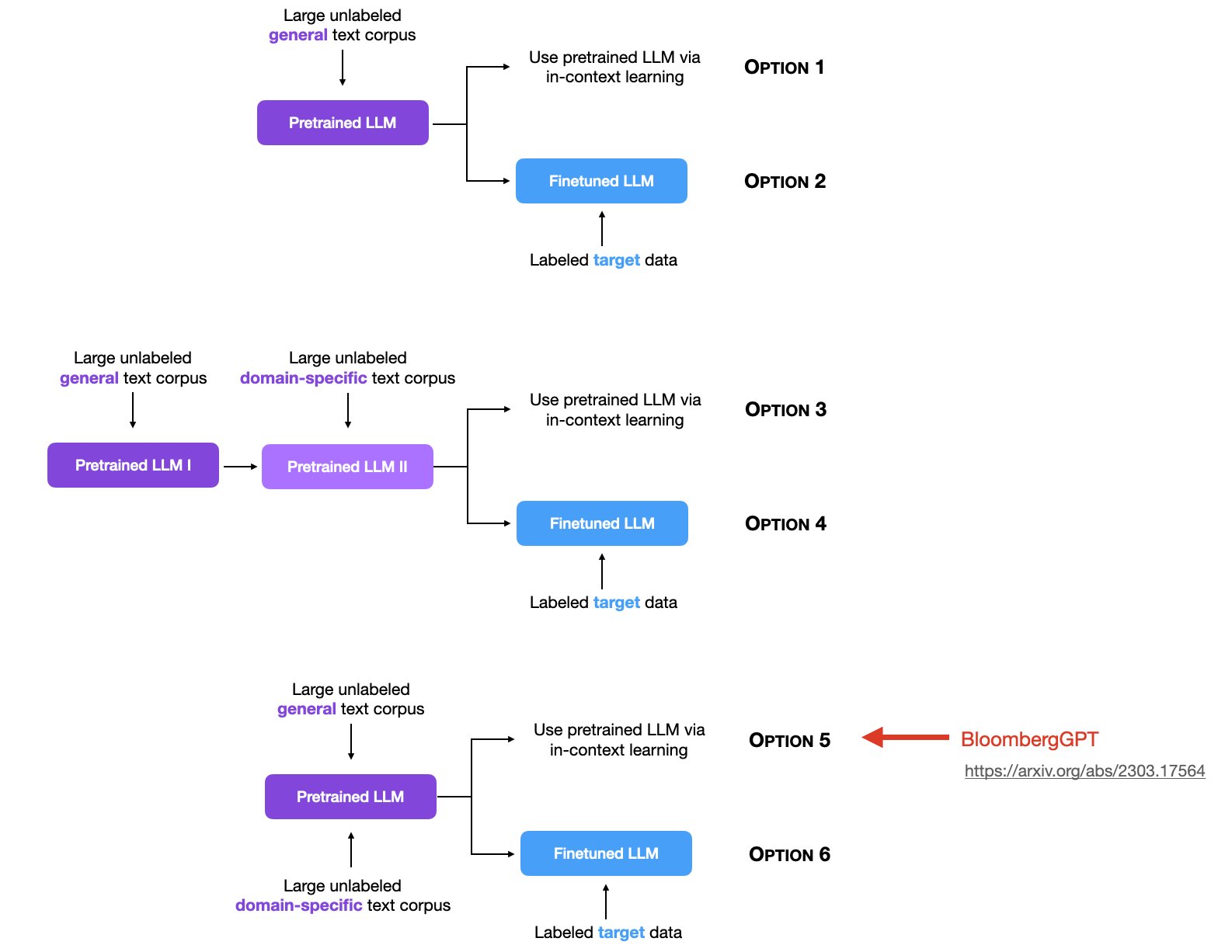
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的简介,也贡献了许多有价值的内容。在最新的一期统计中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于使用领域数据集做无监督预训练是目前讨论较少,但十分重要的一个方向。
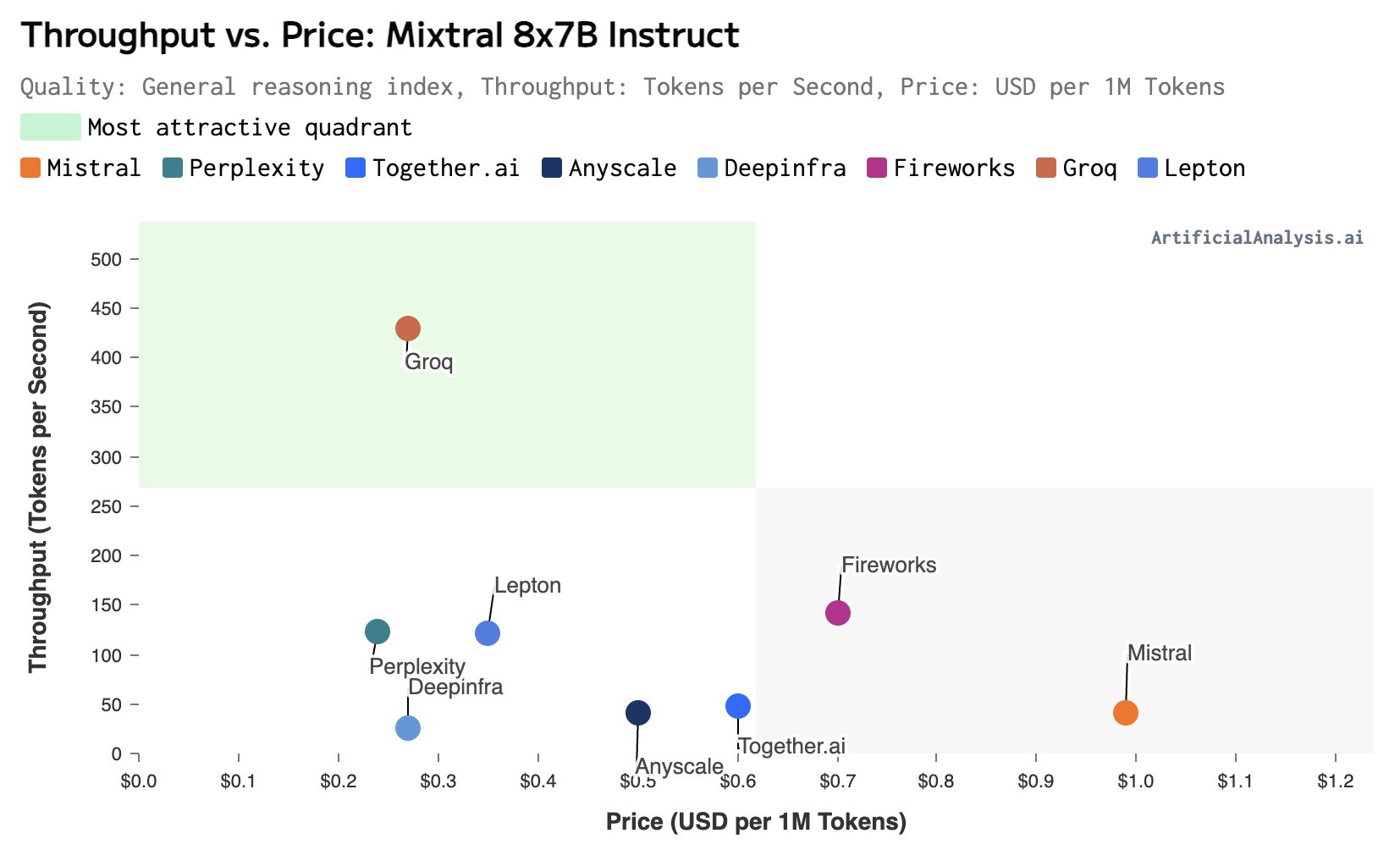
大模型的推理速度是当前制约大模型应用的一个非常重要的问题。在很多的应用场景中(如复杂的接口调用、很多信息处理)的场景,更快的大模型响应速度通常意味着更好的体验。但是,在实际中我们可用的场景下,大多数大语言模型的推理速度都非常有限。慢的有每秒30个tokens,快的一般也不会超过每秒100个tokens。而最近,美国加州一家企业Groq推出了他们的大模型服务,可以达到每秒接近500个tokens的响应速度,非常震撼。
KerasCV是由Keras官方团队发布的一个计算机视觉框架,可以帮助大家用来处理计算机视觉领域的相关任务和问题。这是2022年4月刚发布的最新产品,由于是官方团队出品的工具,所以质量有保证,且社区活跃,一直在积极更新。
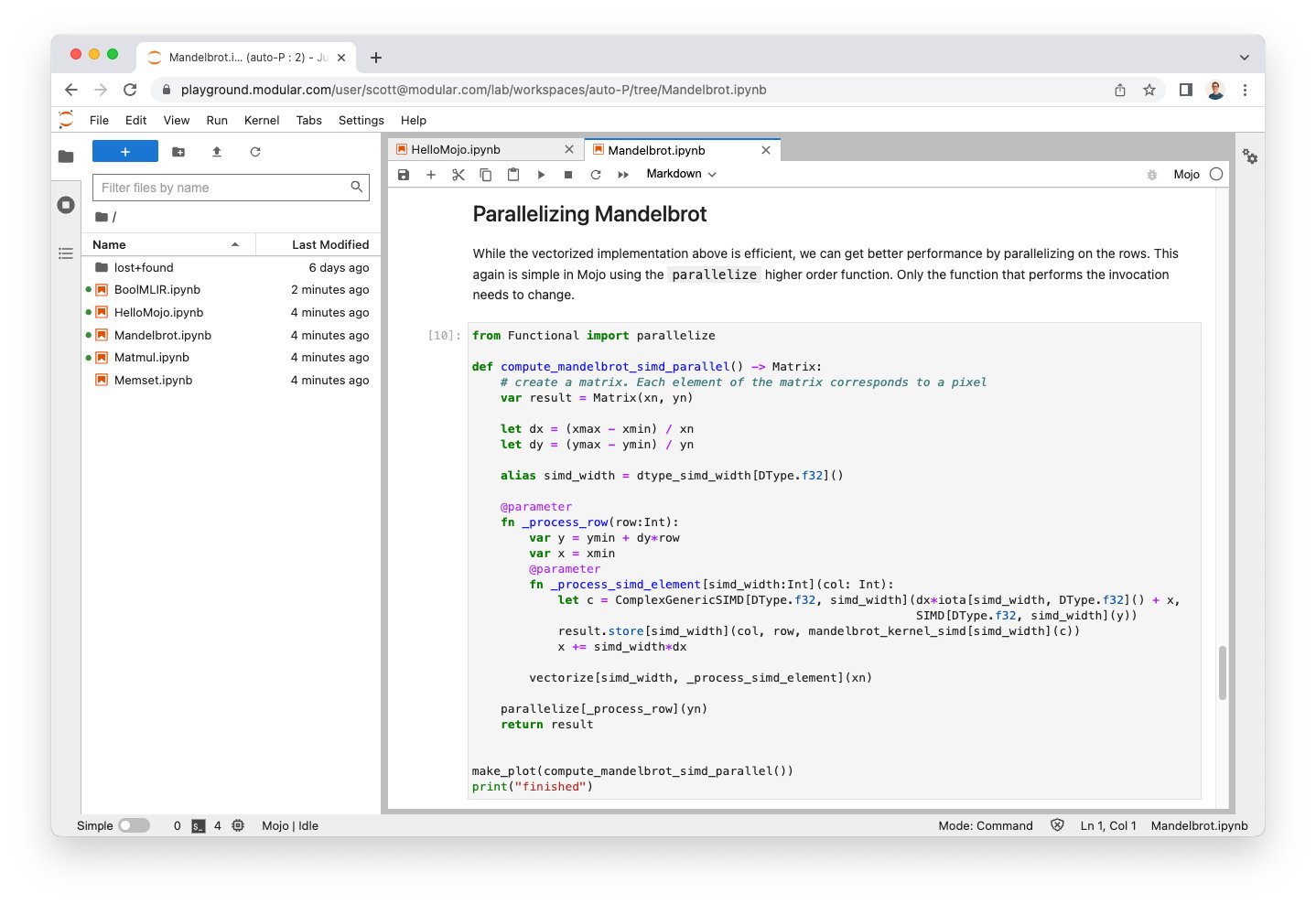
昨天,前苹果工程师、swift编程语言创建者Chris Lattner创立的ModularAI发布了一个新的编程语言Mojo。根据测试,该语言比Python最高提速35000倍!本文将简单介绍一下这个Mojo编程语言。
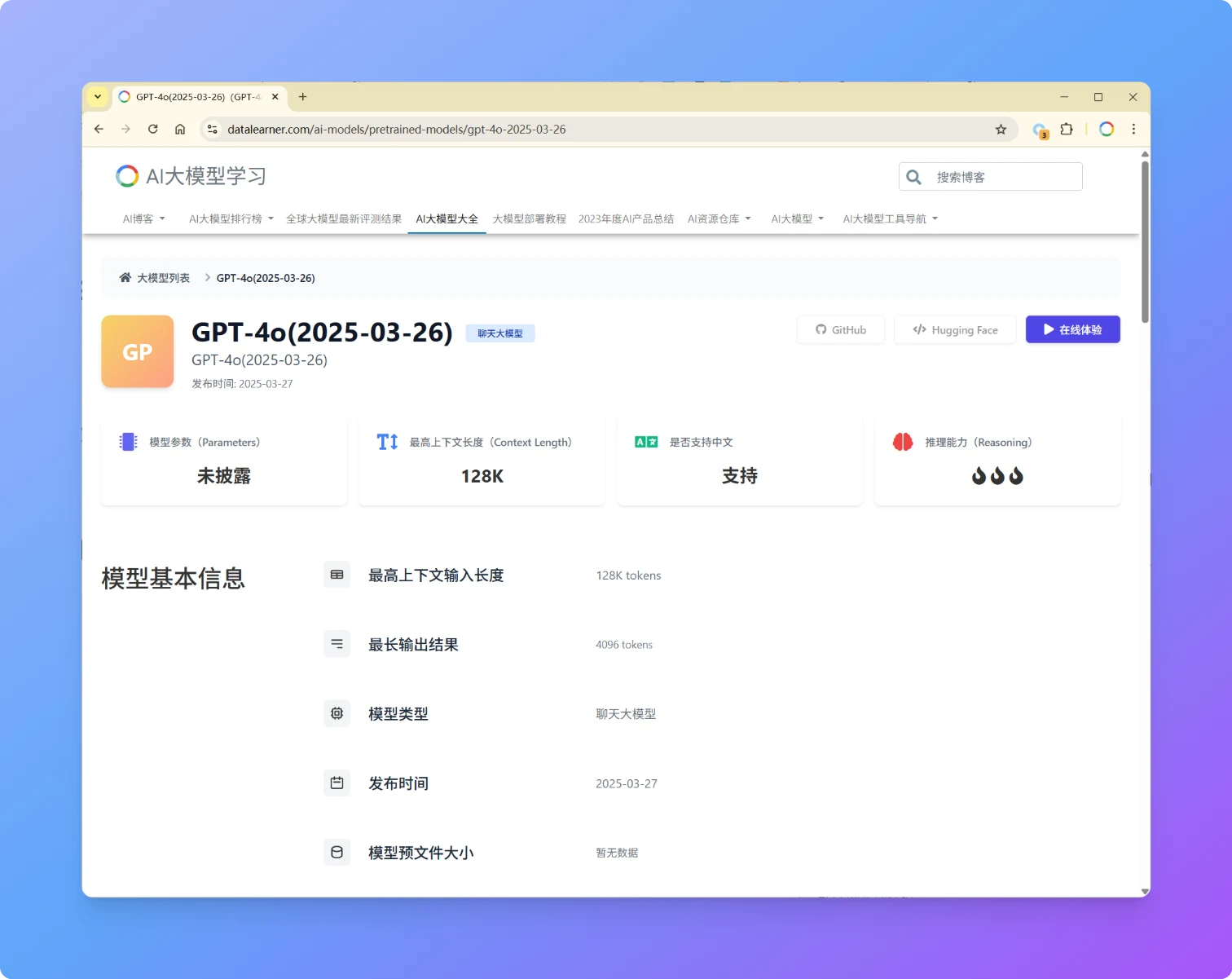
OpenAI再次发布GPT-4o更新版本,版本号为GPT-4o(2025-03-26),本次发布的GPT-4o模型在性能、易用性和协作能力上迎来多项优化,进一步提升了模型的直觉性、创造力和任务执行能力。此次更新聚焦于 STEM 与编程问题解决、指令遵循精度以及自然交互体验,各方面评测进步明显,超过了GPT-4.5。

几个小时前,OpenAI官方宣布开放ChatGPT的系统指令设置功能。主要就是现在你可以为自己的ChatGPT设置一个系统级别的指令,按照你的偏好,来回复所有问题。
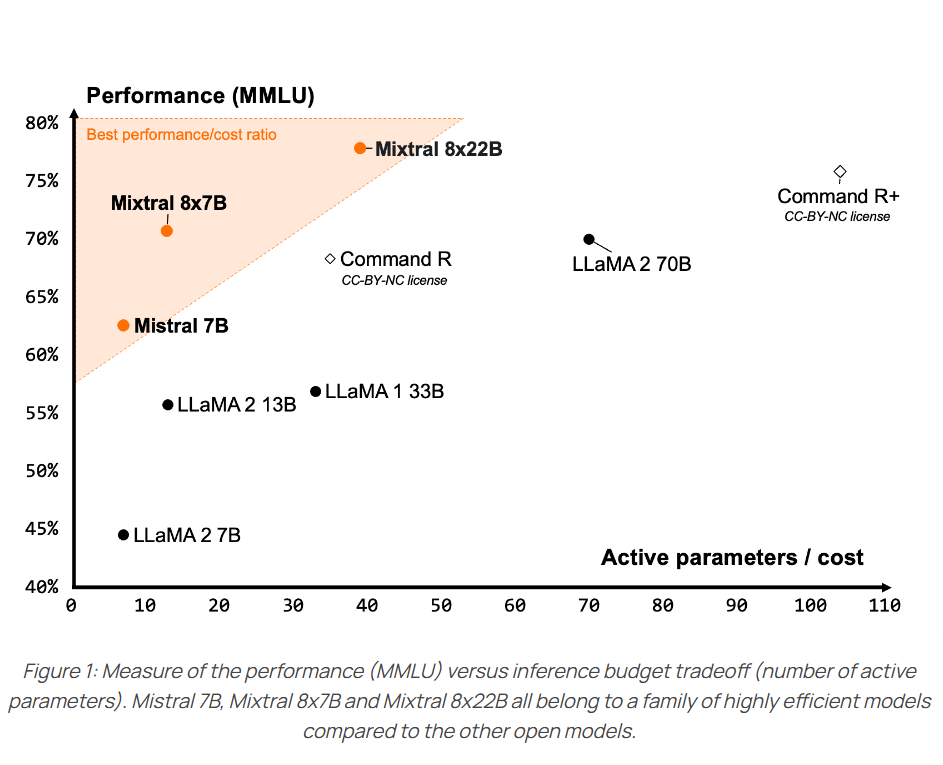
今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
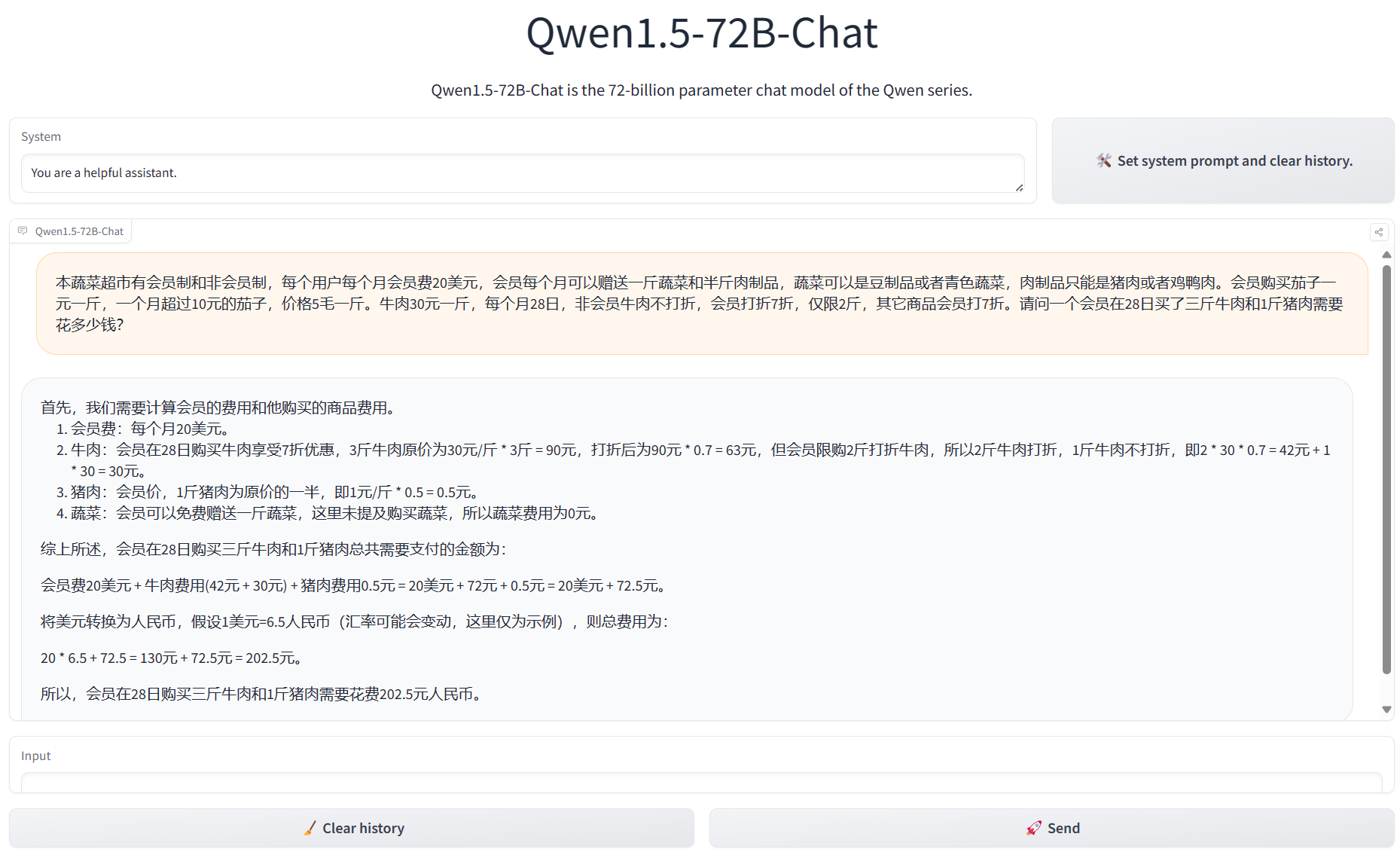
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!

影响者营销将是极好的机会,可以使你的形象更加完善,并接触到新的受众,是一个人性化的宏伟机会?的确如此。它是否充满了影响者和品牌宁愿不管理的问题?同样地,是的。

尽管OpenAI最早也是马斯克和别人一起创立,由于各种原因分道扬镳之后马斯克也没有对相关产品感兴趣,直到ChatGPT风卷全球之后,马斯克与OpenAI的人公开吵了几次之后成立了这家公司。半年后的现在,马斯克透露xAI即将发布它的首个大模型Grōk AI。而一位老哥已经透露了该模型的一些细节。