
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




Whisper是由Open AI训练并开源的语音识别模型,它在英语语音识别方面接近人类水平的鲁棒性和准确性。该模型于2022年9月21日发布之后引起了广大的关注。由于模型的准确性太过惊人,大家已经认为可以直接用于视频的配音制作了。而今天有人发现Whisper的GitHub上有了一个新的提交记录,显示Whisper V2版本即将来临。

OpenAI Startup Fund是OpenAI和微软等合作伙伴在2022年推出的一个创业基金,收到OpenAI Startup Fund投资的初创企业几乎可以等同于OpenAI认为的未来AI应用重要方向。这些企业不仅可以获得资金支持,还可以比其它企业更早使用OpenAI的模型。本文将简要介绍当前OpenAI已经投资的企业,它们可能是未来AI领域重要的角色!
Gemini是谷歌发布的一系列大语言模型。最早是2023年12月发布1.0版本,在2023年2月中旬,劈柴哥亲自宣布Gemini Pro升级到1.5版本。Gemini 1.5 Pro是一个全新的MoE模型(Mixture of Experts,混合专家),在各项评测结果中都接近Gemini Ultra 1.0的水平。而在今天,Gemini Pro 1.5再次迎来重大更新,包括音频理解、无限制文件阅读以及更好地指令遵从性等。本文将介绍这次更新,并做一些简单的实际测试。
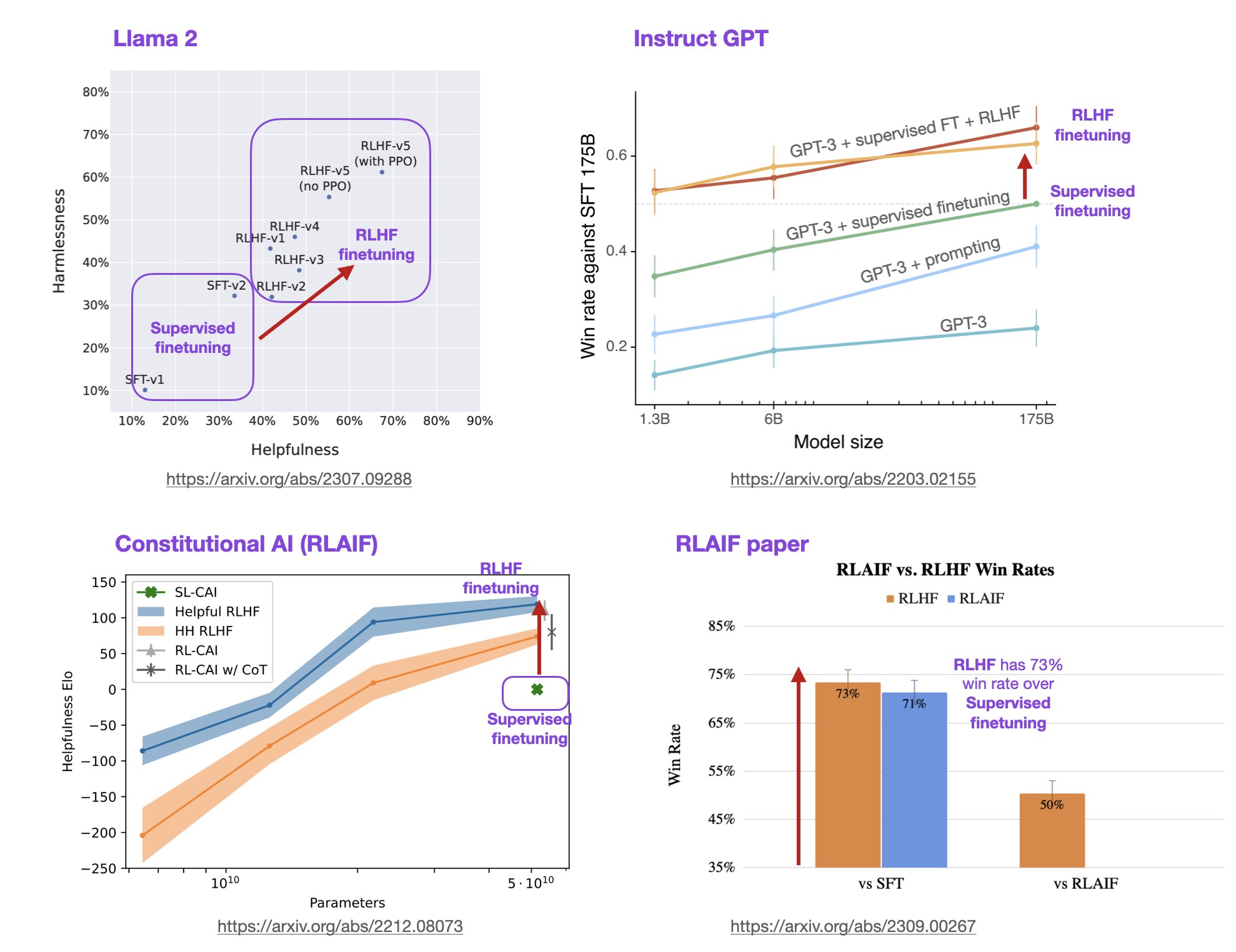
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。
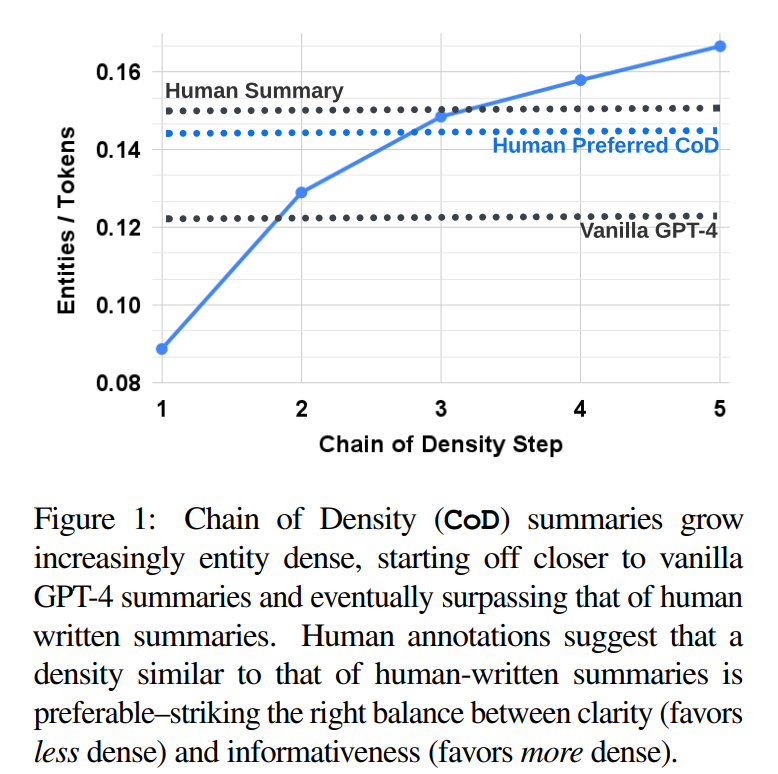
基于文本做文本摘要的时候,摘要所包含的信息密度是一个非常重要的问题。正常情况下我们希望文本摘要既能覆盖更多的重要信息,又要保持简洁和连贯。SalesforceAI与MIT等机构的研究人员联合发布了一个最新的Prompt技巧,称为密度链提示方法(Chain of Density Prompting),可以提取有信息含量的简洁摘要。

ChatGPT是属于生成式AI的一种应用。由于其强大的效果已经变成了当前最主流的一种AI方案。而构建生成式AI应用的一个重要方向是构建友好的web形态的demo让用户能快速体验。Gradio就是这样一种开源方案,也是当前最流行的一种快速构建AI Web应用的方案。昨天吴恩达的DeepLearningAI与HuggingFace共同推出了最新的一期短课程《Building Generative AI Applications with Gradio》,教大家如何使用Gradio快速构建生成式AI的应用。
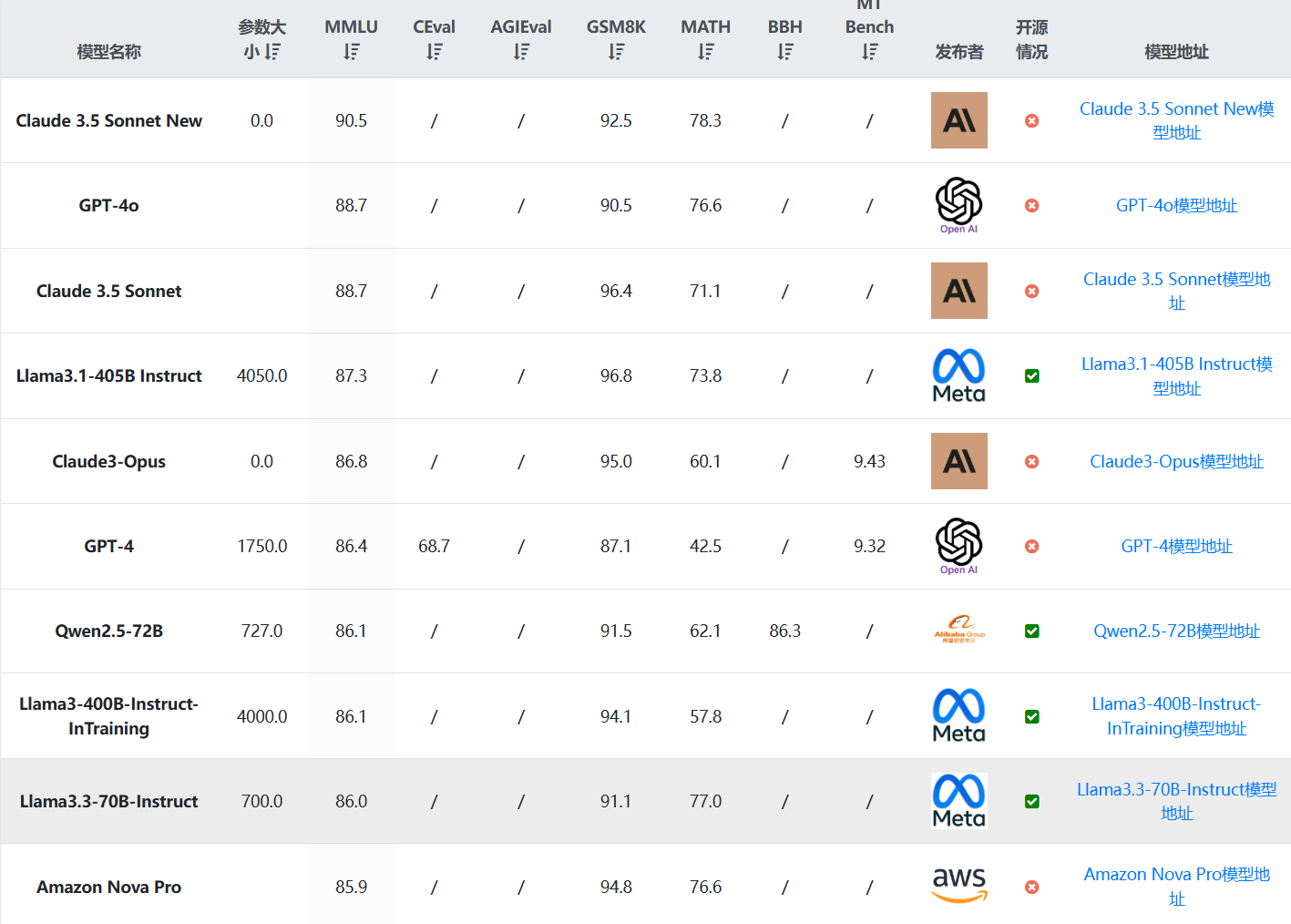
Llama系列大语言模型一直是开源领域的大模型标杆,Llama3系列大模型自从开源之后一直在不断更新。最早的Llama3模型于2024年4月开源,此后,几乎每个三个月都有一个新版本发布。就在昨天,Meta开源了最新的Llama3.3-70B模型,这是Llama3.3系列目前唯一开源的模型。尽管该模型的参数规模仅仅700亿,但是在多项评测基准上已经超过了4050亿参数规模的Llama3.1-405B,后者是Llama系列模型中参数规模最大的一个,也是业界开源模型中参数规模最高的模型之一。
几个小时前,OpenAI开启了今年密集的产品发布时间,本次发布会持续12天,直播12天。几个小时前,第一个发布的产品宣布,那就是OpenAI o1模型的正式版。同时也开启了一个全新的ChatGPT付费计划,即ChatGPT Pro,每个月200美元,可以不限量使用所有模型。本文详细介绍OpenAI o1模型。

就在几个小时前,阿里巴巴开源了最新的一个推理大模型,QwQ-32B,该模型拥有类似o1、DeepSeek R1模型那样的推理能力,但是参数仅325亿,以Apache 2.0开源协议开源,这意味着大家可以完全免费商用。
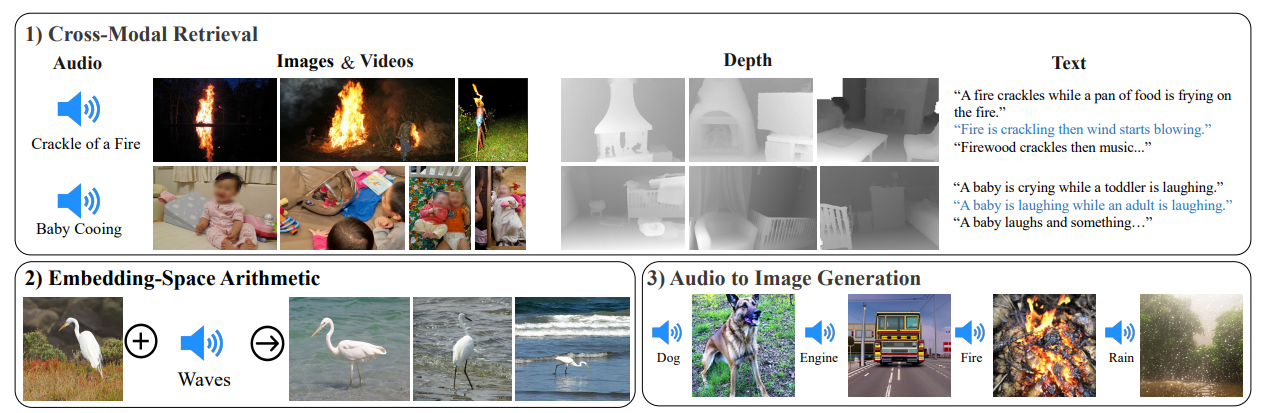
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。
2025年3月20日,OpenAI 推出了三款新模型——gpt-4o-transcribe、gpt-4o-mini-transcribe 和 gpt-4o-mini-tts——标志着自动语音识别 (ASR) 和文本转语音 (TTS) 领域的重要进步。这些模型基于 GPT-4o 架构,旨在为开发人员和用户提高准确性、自定义能力和可访问性,与 OpenAI 对于代理式 AI 系统的更广泛愿景一致。本文提供了对每个模型、其能力、定价、可用性和竞争环境的详细审查,确保技术和非技术受众都能全面理解。
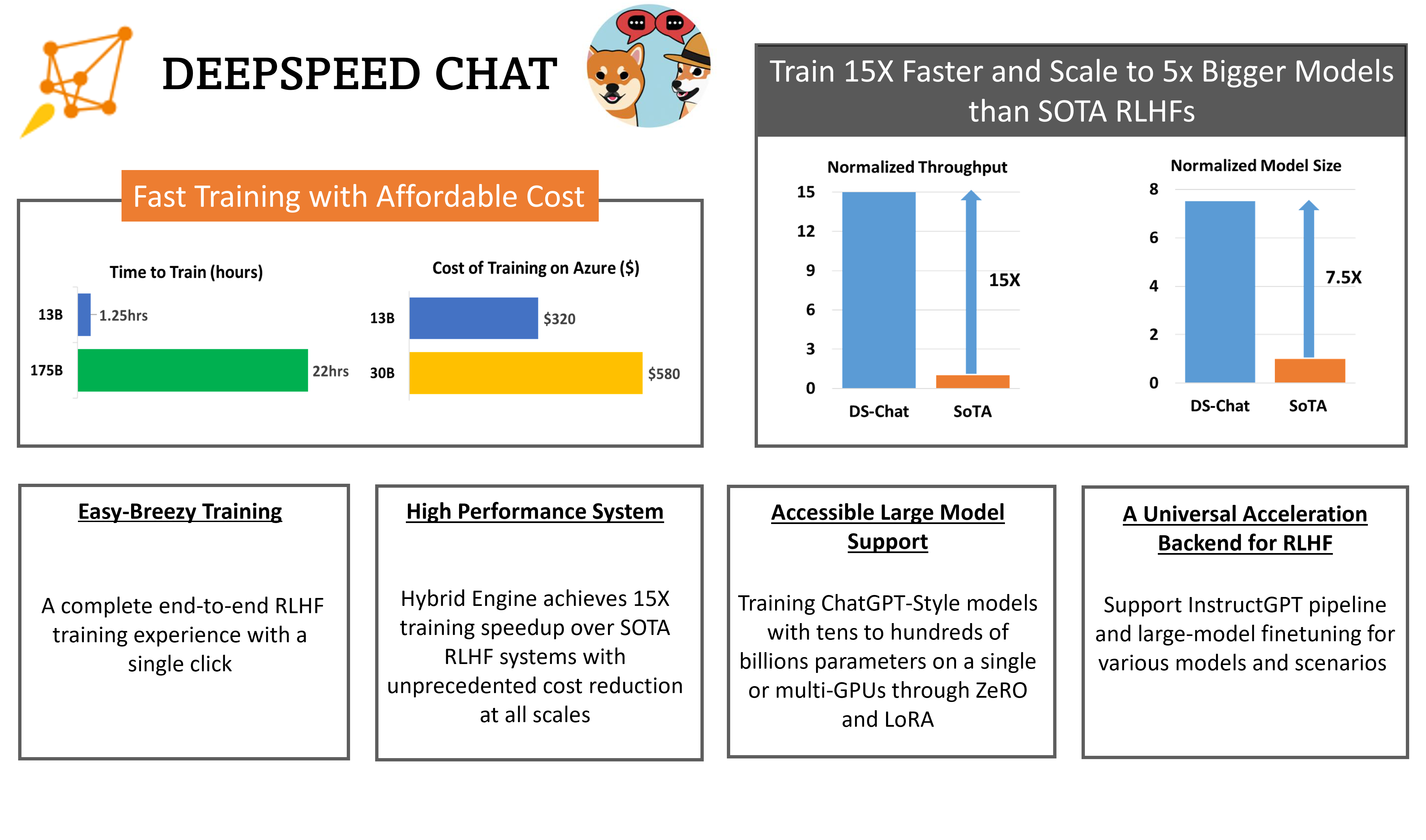
RLHF全称Reinforcement Learning from Human Feedback,是随着ChatGPT火爆之后而被大家所关注的技术。昨天,微软开源了业界第一个RLHF的pipeline框架,可以用来训练类似ChatGPT的模型。


随着大语言模型(LLM)的发展越来越快,我们需要更好的方法来评估它们到底有多“聪明”,特别是在处理复杂数学问题的时候。AIME 2025 就是这样一个工具,它专门用来测试当前 AI 在高等数学推理方面的真实水平。
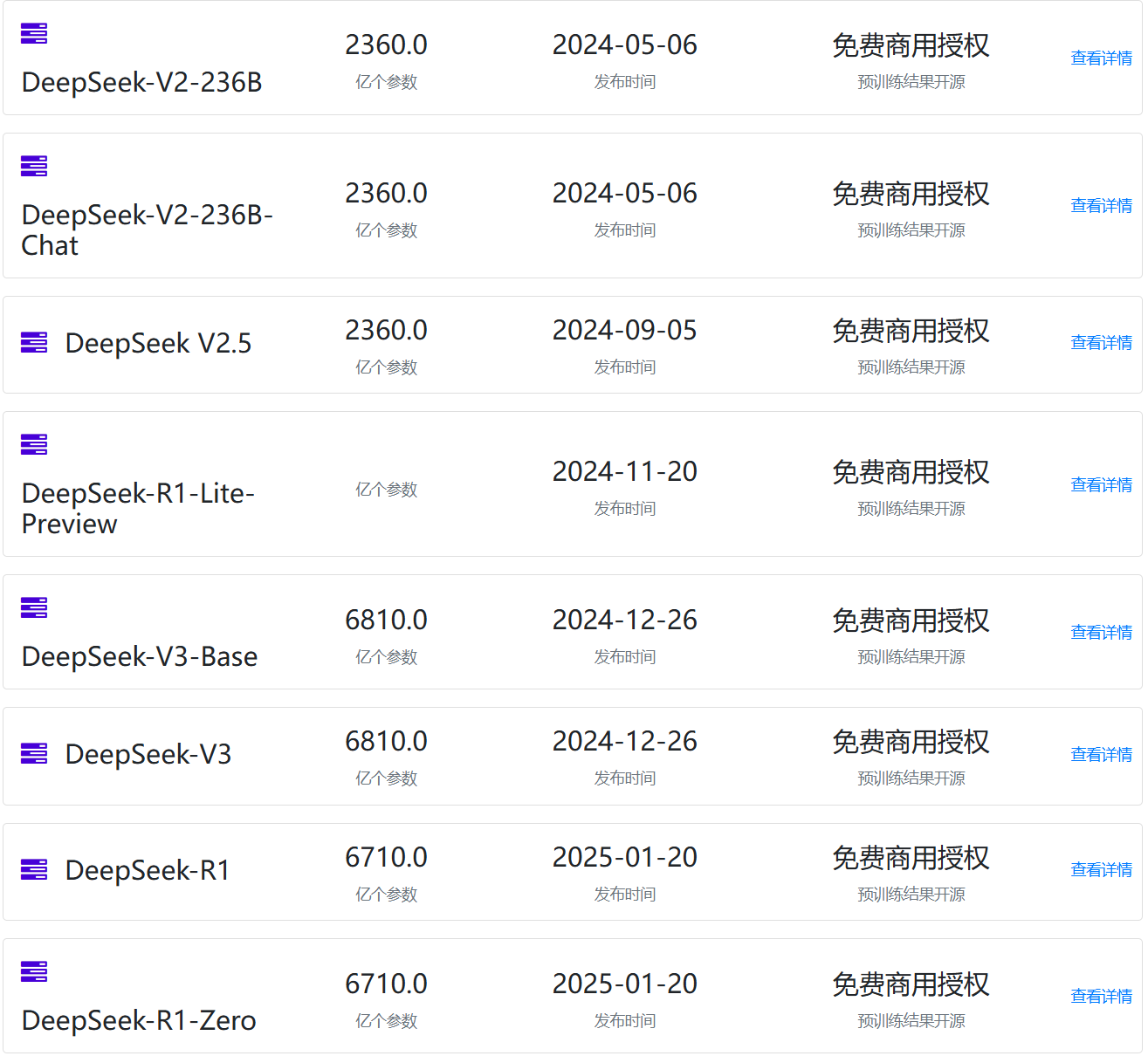
DeepSeekAI最近发布的几个模型,如DeepSeek V3、DeepSeek R1等引起了全球的广泛关注和讨论,特别是低成本训练出高质量模型之后,引起了很多的争论。引起了大家对OpenAI、英伟达等公司未来的质疑。然而,对于DeepSeekAI的模型为什么引起了如此广泛的关注,以及大家讨论的核心内容是什么,很多人并不是很清楚。本文基于著名的独立科技行业分析师Ben Thompson的总结,配合DataLearnerAI的分析,为大家总结DeepSeek引起的全球讨论。
今日推荐
OpenAI发布最新最强大的AI对话系统——GPT3.5微调的产物ChatGPT
重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口
在线广告的紧凑分配方案(Optimal Online Assignment with Forecasts)
截止目前中文领域最大参数量的大模型开源:上海人工智能实验室开源200亿参数的书生·浦语大模型(InternLM 20B系列),性能提升非常明显!
Python报Memory Error或者是numpy报ValueError: array is too big; `arr.size * arr.dtype.itemsize` 的解决方法