
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



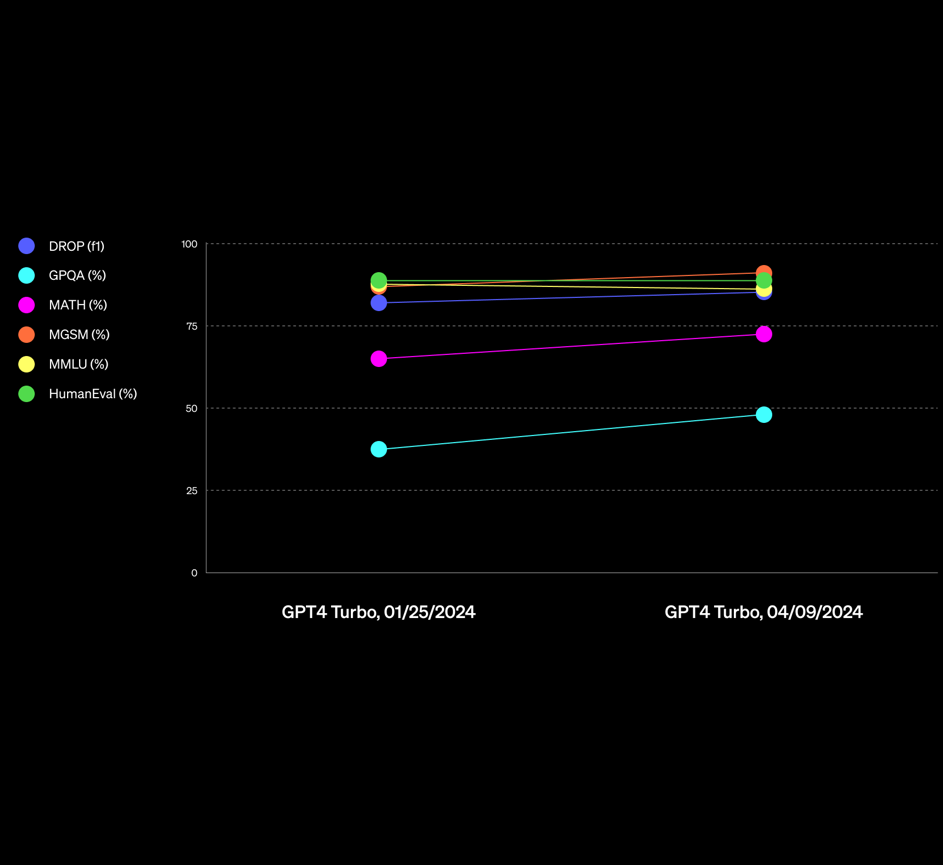
OpenAI的GPT-4一直是全球最强的大语言模型。但是在最近的一系列新模型对比中,已经有一些模型在某些领域被认为已经接近或者超过GPT-4了。而在前几天,OpenAI更新了一个新版本的GPT-4,是GPT-4-Turbo-2024-04-09,官方说该版本的GPT在推理和数学能力上有明显提升,而实测结果也很不错。在基准测试评测中,最高有19%的提升幅度!在GPT-4这样强的模型上有这样的提升幅度,十分不错!

今天BusinessInsider发布了一个消息,说根据最新的消息,OpenAI目前还在训练GPT-5,但是有一些企业客户最近已经获得了该最新模型及其对ChatGPT工具的相关增强功能的演示。
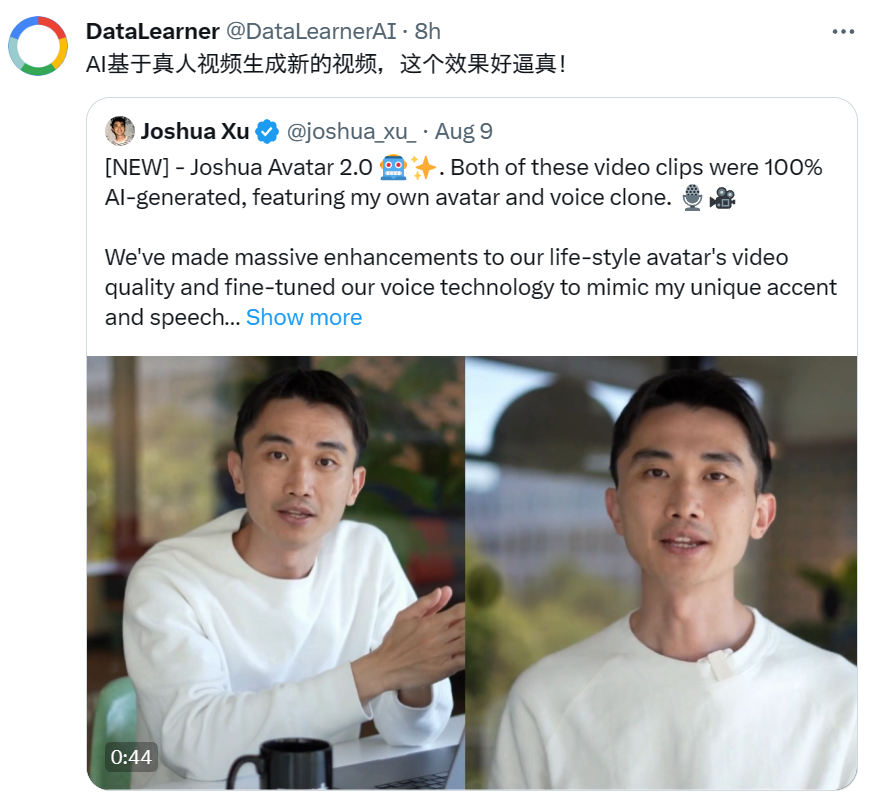
电影《流浪地球2》里面一个非常重要的情节就是数字生命计划。将人类的意识上传到计算机之后,可以通过AI技术让人类以数字化的形式在计算机中存活。而今天HeyGen官方宣布的即将推出的真人视频生成技术,可以根据真人的照片生成非常逼真的数字人视频,其动作、表情、声音等全部由AI技术生成,而几乎无法分辨是真人拍摄的视频还是AI生成的视频。
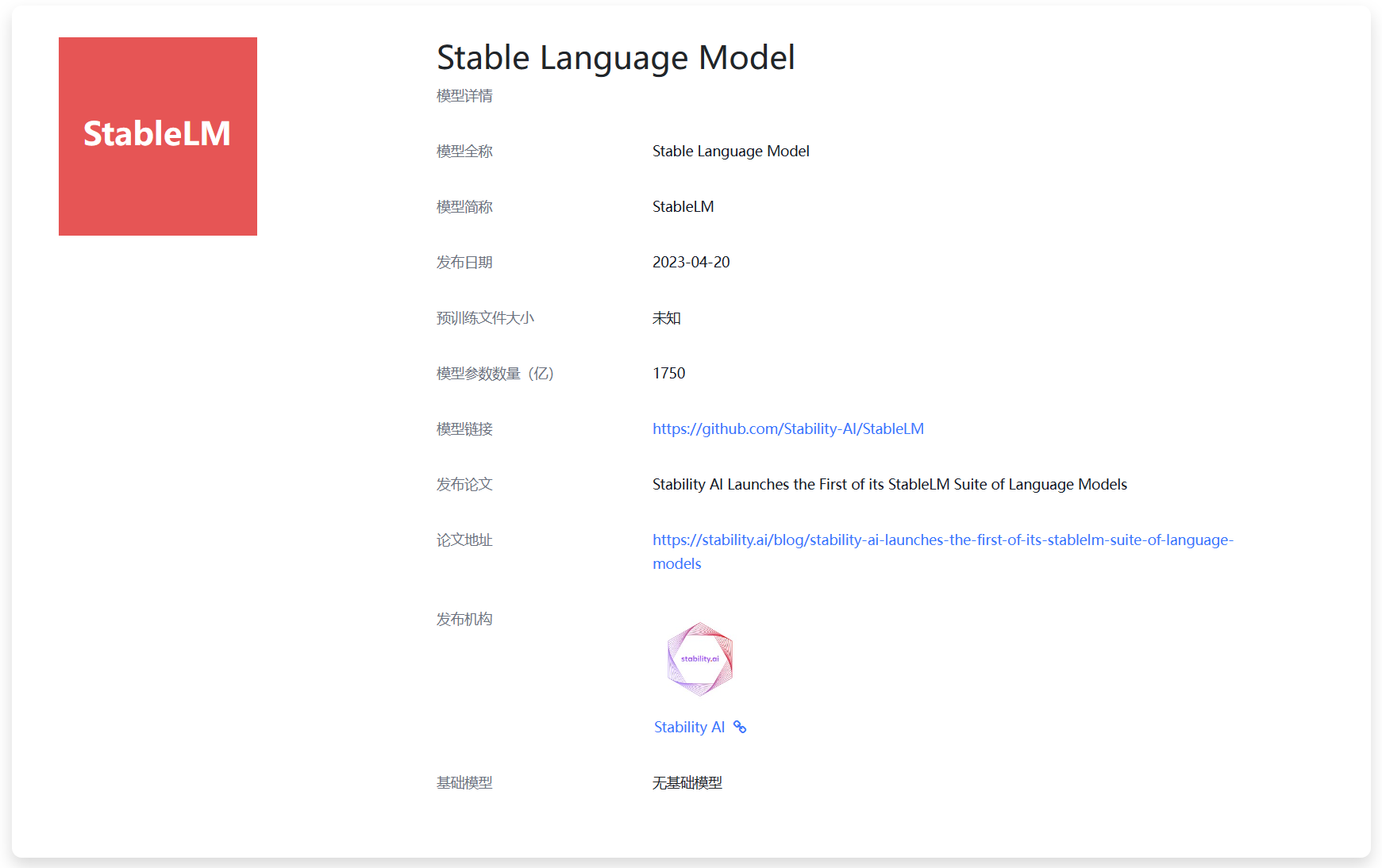
今天,Stability宣布开源StableLM计划,这是一个正在开发过程的大语言模型,但是它是开源可商用的模型。本文将对该模型做简单的介绍!

大模型的进展非常快,但是如何在移动端部署和使用依然是一个非常大的挑战。今天,CerebrasAI联合Opentensor一起开源了一个30亿参数规模的模型BTLM-3B-8K,官方宣称其性能接近70亿参数规模的大模型,但是运行的资源却很低,最低量化版本只需要不到4GB显存即可。
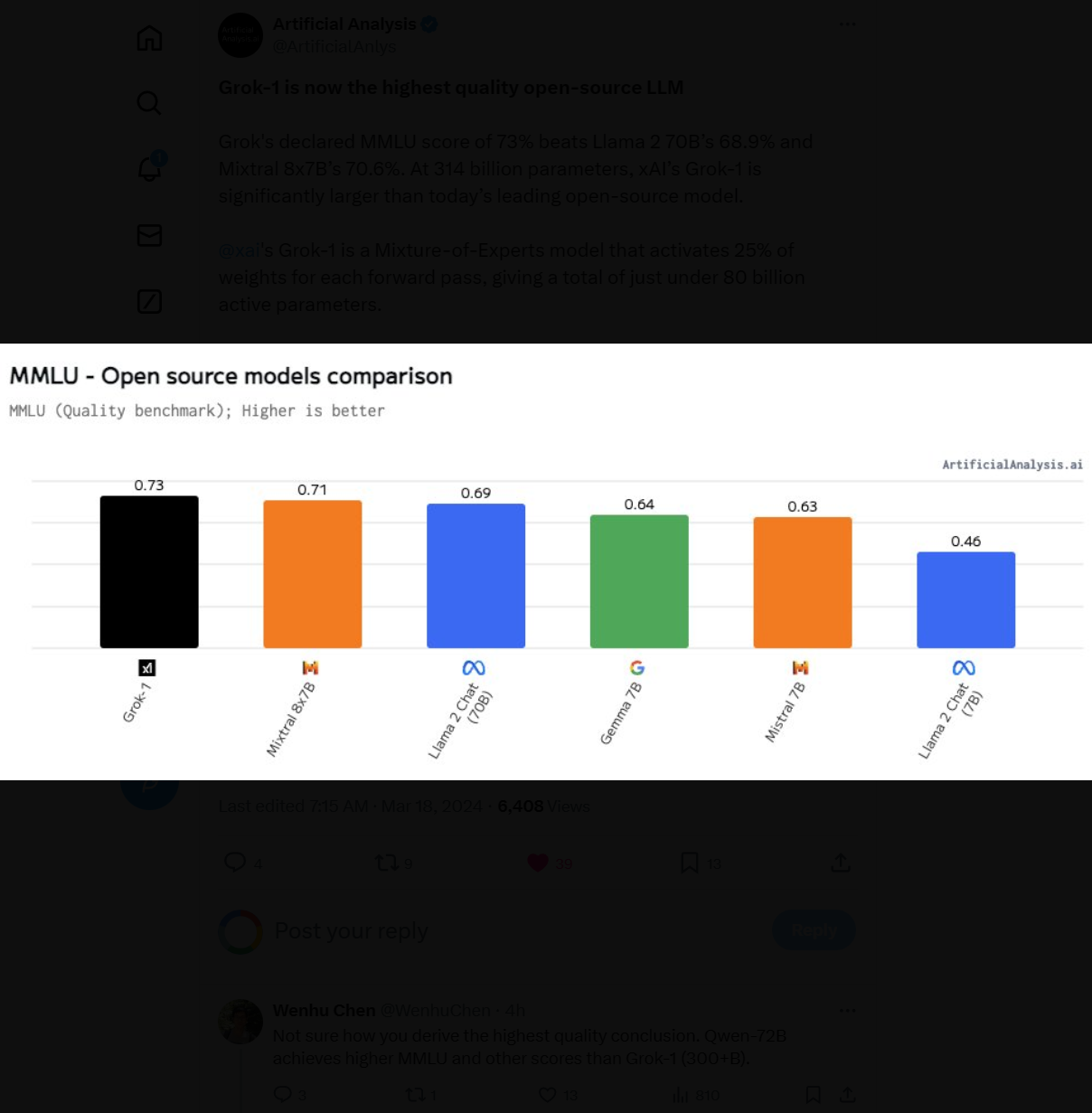
此前,马斯克在推特上宣布要开源旗下大模型公司开发的Grok-1大语言模型。一周后的现在,这个模型Grok-1正式宣布以Apache2.0开源协议开源,本文将针对Grok-1的技术部分进行介绍。
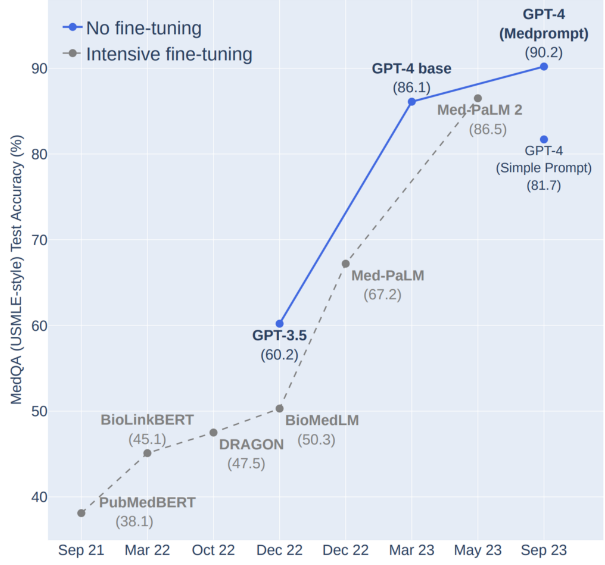
在GPT-4这种超大基座模型发布之后,一个非常活跃的方向是专有模型的发展。即一个普遍的观点认为,基座大模型虽然有很好的通用基础知识,但是对于专有的领域如医学、金融领域等,缺少专门的语料训练,因此可能表现并不那么好。如果我们使用专有数据训练一个领域大模型可能是一种非常好的思路,也是一种非常理想的商业策略。但是,微软最新的一个研究表明,通用基座大模型如果使用恰当的prompt,也许并不比专有模型差!同时,他们还提出了一个非常新颖的动态prompt生成策略,结合了领域数据,非常值得大家参考。

研究生级别的 **Google 防查找问答基准测试**(即Graduate-Level Google-Proof Q&A Benchmark,简称 GPQA)是大型语言模型(LLM)面临的最具挑战性的评估之一。GPQA 旨在推动人工智能能力的极限,提供一个严格的测试平台,不仅评估模型的事实记忆能力,还考察其在专业科学领域的深度推理和理解能力。本篇博文将客观介绍 GPQA,涵盖它的起源、目的、组成部分,以及领先的大型语言模型在这个高要求基准测试中的表现。

彭博社今天发布了一份研究论文,详细介绍了BloombergGPT的开发,这是一个新的大规模生成式人工智能(AI)模型。这个大型语言模型(LLM)经过专门的金融数据训练,支持金融业内的多种自然语言处理(NLP)任务。
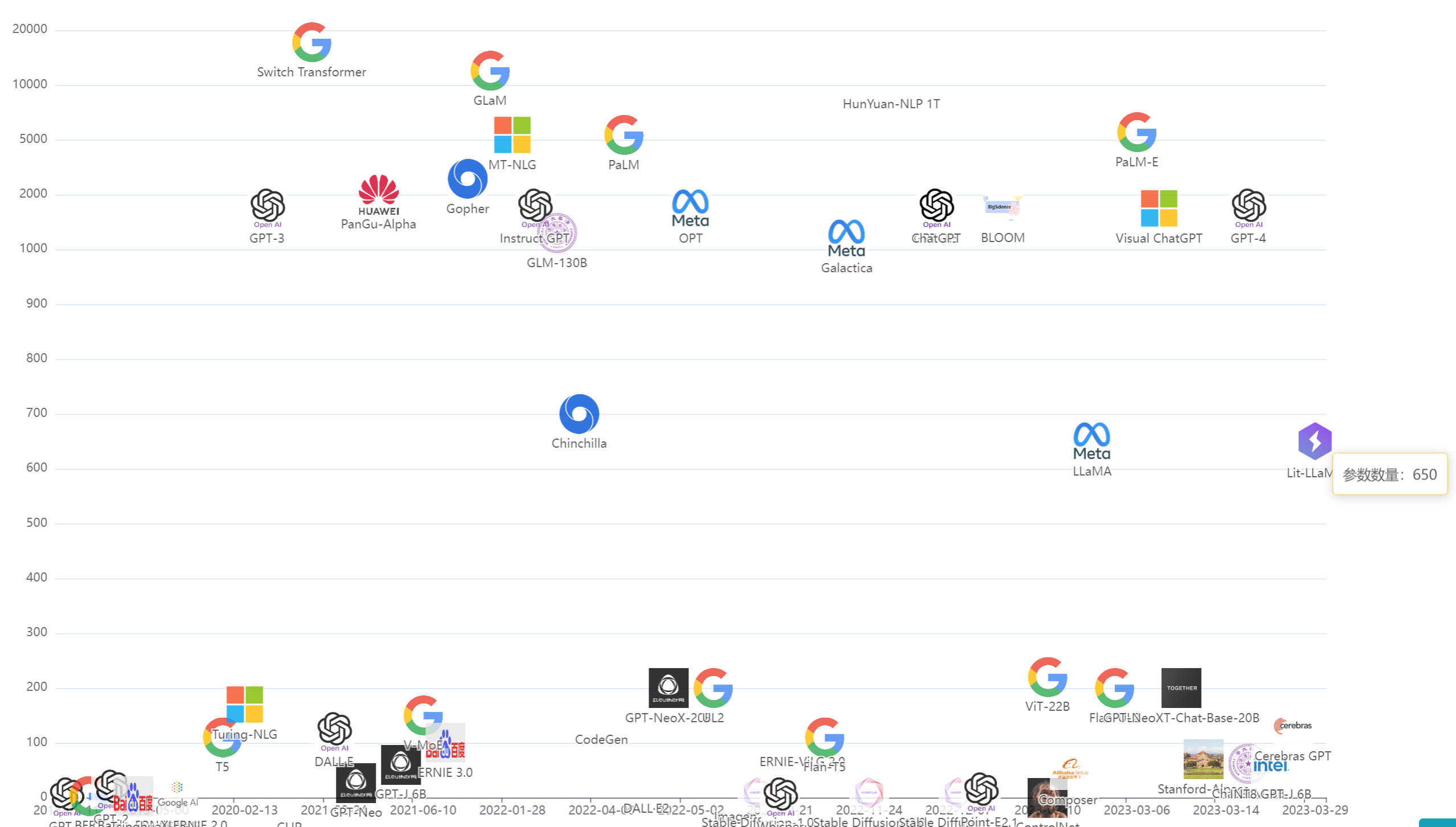
斯坦福大学发布的基础大模型追踪图谱Ecosystem Graphs,用图谱的方式给大家呈现了模型之间的联系,让人非常清楚明白追踪不同模型之间的关系。


Gemini是谷歌发布的一系列大模型的名称,是谷歌前期大模型Bard产品的替代品。从Gemini 1.0发布开始,每一次发布都获得了不错的反响。今天,Google发布了最新一代的Gemini 2.0模型,首个产品是其参数规模较小的Gemini 2.0 Flash,它的推理速度是Gemini 1.5 Pro的2倍,但是各项评测结果上的表现却超过了Gemini 1.5 Pro。该模型完全免费提供给大家使用。
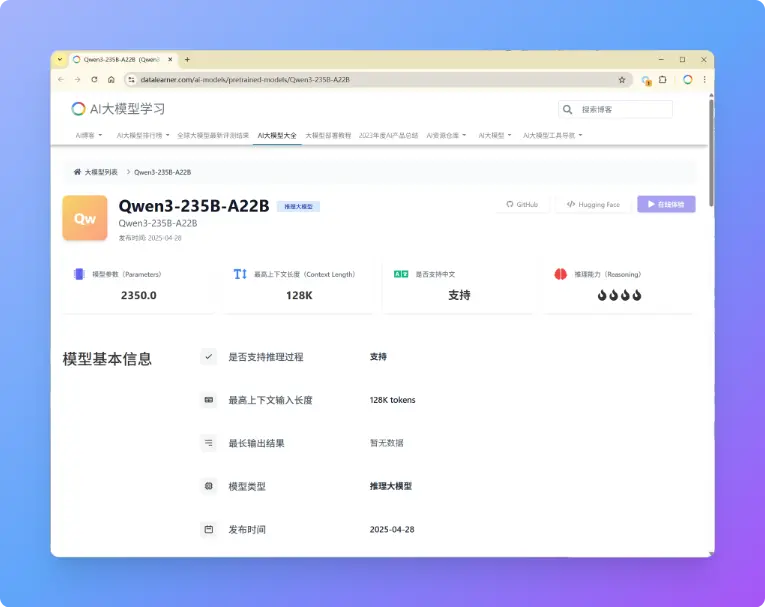
阿里巴巴刚刚开源了第三代千问大模型,Qwen3系列包含了8个不同参数规模的大模型,最大达到2350亿参数规模,最小仅6亿参数规模。本次发布的Qwen3系列是推理大模型和常规的大模型混合版本,即Qwen3可以根据输入问题的情况自动选择是否进行推理。
今日推荐
智谱AI与清华大学联合发布第三代基座大语言模型ChatGLM3:6B版本的ChatGLM3能力大幅增强,依然免费商用授权!
SWE-Lancer:OpenAI发布的一个全新大模型评测基准,用来测试大模型解决真实世界软件工程的能力
阿里开源推理大模型QwQ-32B-Preview:开源领域对OpenAI o1模型奋起直追,能力接近o1-mini,超过GPT-4o!
强大的对象分割开源算法!Meta AI开源Segment Anything: Working(SAM)预训练大模型!
KerasCV——一个新的简单易用的计算机视觉(CV)算法库
马斯克旗下xAI发布Grok-1.5,相比较开源的Grok-1,各项性能大幅提升,接近GPT-4!
支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3