
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




MTEB是一个用于评估向量大模型向量化准确性的评测排行榜。它全称为Massive Text Embedding Benchmark,是一个旨在衡量文本嵌入模型在多种任务上表现的基准测试。

GPT-5 在指令遵循和推理能力上比前代更强,但也因此更“敏感”:如果规则里有冲突或表述过度强硬,模型往往会卡壳或输出异常。为此,OpenAI 发布了面向开发者的 《GPT-5 for Coding》技巧小抄,其中总结了使用 GPT-5 进行编程与代码生成时最实用的六条经验。这些技巧与普通的“写作提示工程”不同,它们专门针对软件开发场景:如何写规则、怎样控制推理强度、如何避免模型“想太多”,以及怎样利用 GPT-5 的新特性把它真正驯化成可靠的结对编程伙伴。本文对这六条技巧逐条进行解释总结。
Manus AI 是一款尖端的人工智能代理程序,于 2025 年 3 月 6 日正式发布,旨在跨多个领域自主执行复杂任务,弥合人类意图与可操作结果之间的差距。它由 Butterfly Effect 开发,该公司在中国(北京和武汉)以及新加坡(BUTTERFLY EFFECT PTE. LTD.)设有运营机构。以下内容基于截至 2025 年 7 月 5 日的最新信息,涵盖其产品功能、关键技术特点及用户反馈。
随着大型语言模型(LLM)能力的飞速发展,如何科学、准确地评估其性能,特别是深度的逻辑推理和代码生成能力,已成为人工智能领域的一大挑战。传统的评测基准在面对日益强大的模型时,逐渐暴露出数据污染、难度不足、无法有效评估真实推理能力等问题。在这一背景下,一个旨在检验模型竞赛级编程水平的评测基准——Codeforces应运而生,为我们提供了一个更严苛、更接近人类程序员真实水平的竞技场。
随着大型语言模型(LLM)的飞速发展,如何准确、全面地评估它们的能力成为了一个日益重要的课题。在众多评测基准中,Simple Bench 以其独特的定位脱颖而出,它专注于检验模型在日常人类推理方面的能力,而在这些方面,当前最先进的模型往往还不如普通人。本文将详细介绍 Simple Bench 评测基准,探讨其出现的背景、设计理念、评测流程以及当前主流模型的表现。
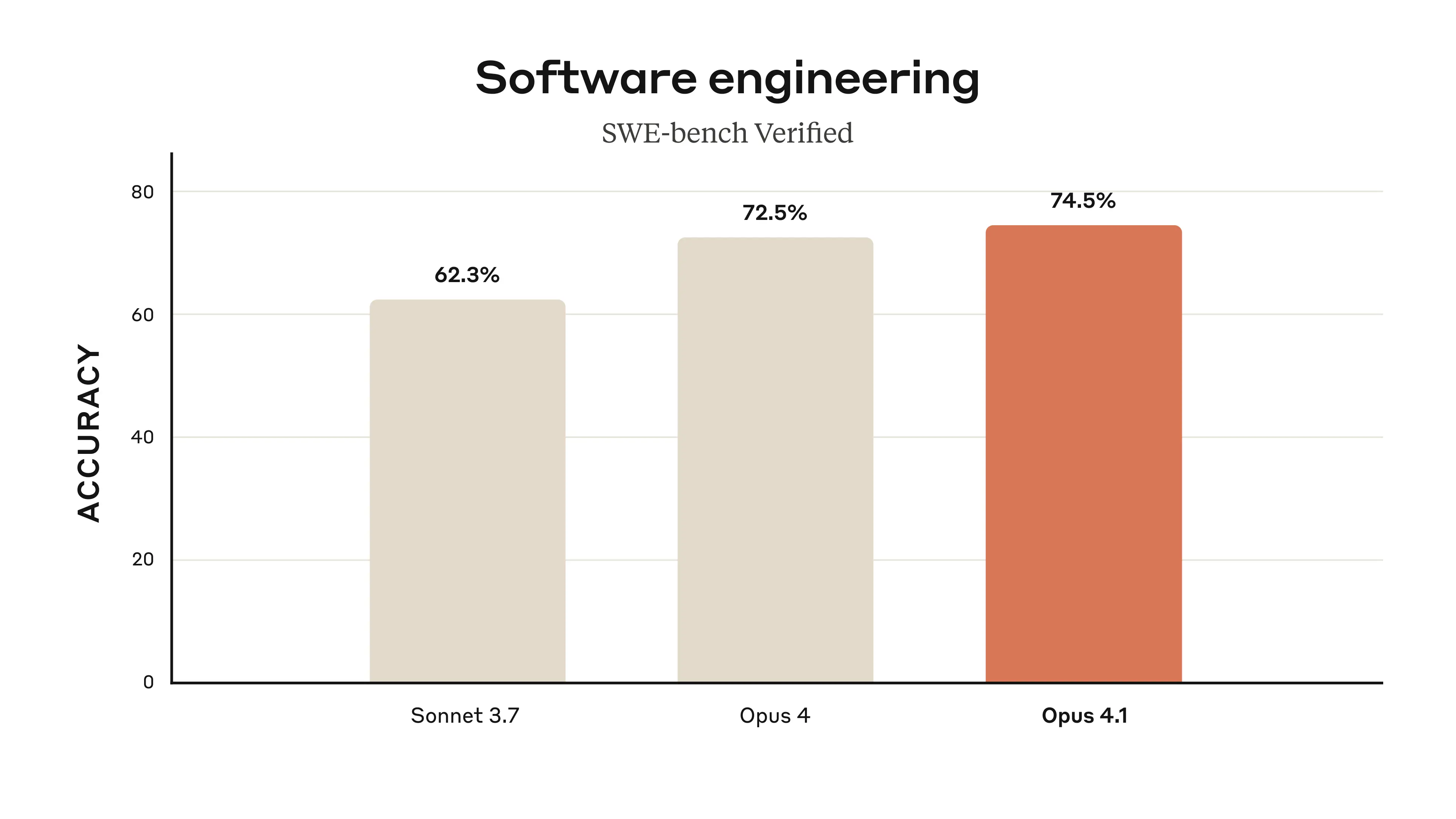
Anthropic 在 Opus 4 发布不到三个月后推出 Claude Opus 4.1,宣称“可直接替换”旧版模型。更新聚焦真实世界编码、长链路代理(agentic)任务和细粒度推理,同时保持相同 API 名称结构和计费档位,方便现有应用平滑迁移。
随着多模态大语言模型(MLLM)在各个领域的应用日益广泛,一个核心问题浮出水面:我们如何信赖它们生成内容的准确性?当模型需要结合图像和文本进行问答时,其回答是否基于事实,还是仅仅是“看似合理”的幻觉?为了应对这一挑战,一个名为SimpleVQA的新型评测基准应运而生,旨在为多模态模型的事实性能力提供一个清晰、可量化的度量衡。
谷歌开源了其Gemma 3模型系列的新成员——Gemma 3 270M。该模型的设计理念并非追求通用性和大规模,而是专注于为定义明确的特定任务提供一个高效、紧凑的解决方案。其核心价值在于通过微调(fine-tuning)来执行专门化任务。
在衡量大语言模型(LLM)智能水平的众多方法中,除了常见的常识推理、专业领域测评外,还有一个正在兴起且极具挑战性的方向——算法问题求解。在这一领域,几乎没有哪项比赛能比 国际信息学奥林匹克(International Olympiad in Informatics,简称 IOI) 更具权威性与含金量。