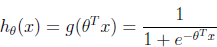
分类和Logistic回归
监督学习中的分类问题和Logistic回归常常被用于推荐问题中关于BPR的研究,但是为什么一定要用Logistic函数来建模和优化呢?本篇博客将带你揭晓奥秘~
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
监督学习中的分类问题和Logistic回归常常被用于推荐问题中关于BPR的研究,但是为什么一定要用Logistic函数来建模和优化呢?本篇博客将带你揭晓奥秘~

最近,随着DeepSeek R1的火爆,推理大模型也进入大众的视野。但是,相比较此前的GPT-4o,推理大模型的区别是什么?它适合什么样的任务?推理大模型是如何训练出来的?很多人并不了解。本文将详细解释推理大模型的核心内容。

OpenAI最新发布了GPT-3.5-Turbo-Instruct,这是一款强大的指令遵循大模型。尽管官方没有发布官方博客介绍,但我们将在本文中详细探讨这一模型的特点以及其在人工智能领域的价值。

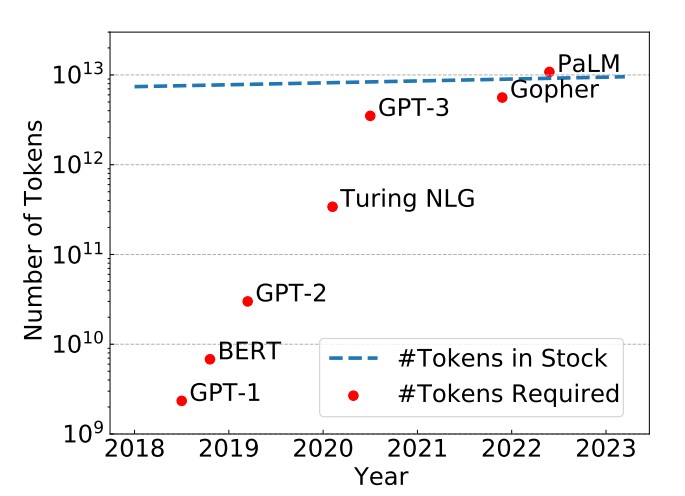
epoch是一个重要的深度学习概念,它指的是模型训练过程中完成的一次全体训练样本的全部训练迭代。然而,在LLM时代,很多模型的epoch只有1次或者几次。这似乎与我们之前理解的模型训练充分有不一致。那么,为什么这些大语言模型的epoch次数都很少。如果我们自己训练大语言模型,那么epoch次数设置为1是否足够,我们是否需要更多的训练?
昨天,吴恩达宣布与OpenAI联合推出了一个新的面向开发者的ChatGPT的Prompt课程。课程主要教授大家如何使用Prompt做ChatGPT的应用开发、使用ChatGPT的新方法、建立自己的个性化的Chatbot,以及最重要的,基于OpenAI的API来练习Prompt工程技巧!
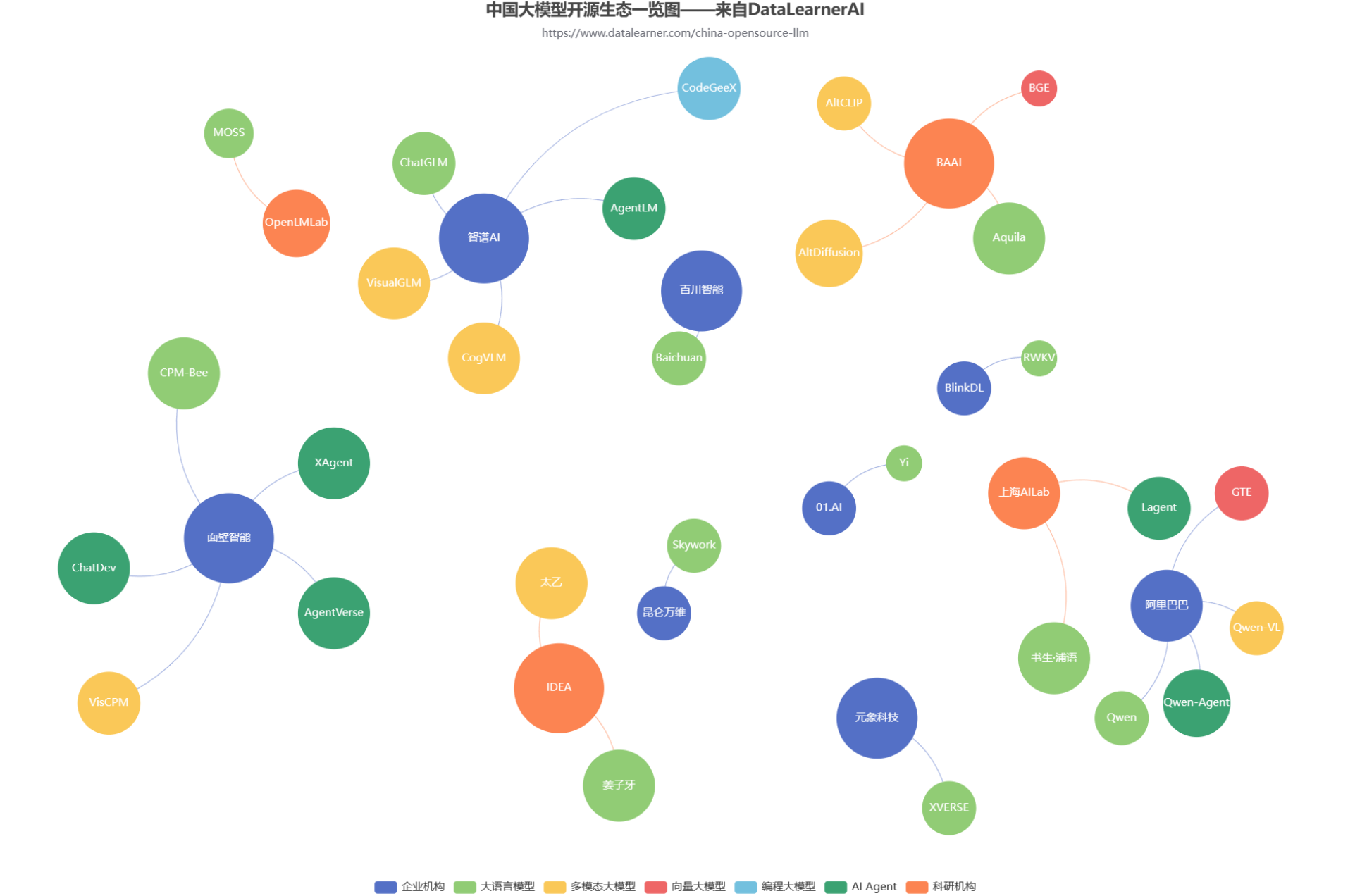
随着GPT的一路爆火,国内大模型的开源生态也开始火热。各大商业机构和科研组织都在不断发布自己的大模型产品和成果。但是,众多的大模型产品眼花缭乱。为了方便大家追踪国产开源大模型的发展情况,DataLearnerAI发布了中国国产大模型生态系统全景统计(地址:https://www.datalearner.com/china-opensource-llm ),本文也将根据这个统计结果简单分析当前国产开源大模型的生态发展情况。
Dask的集群启动创建也很简单,有好几种方式,最简单的是采用官方提供dask-scheduler和dask-worker命令行方式。本文描述如何使用命令行方法建立Dask集群。
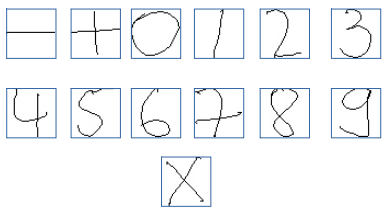
本文是发在Medium上的一篇博客:《Handwritten Equation Solver using Convolutional Neural Network》。本文是原文的翻译。这篇文章主要教大家如何使用keras训练手写字符的识别,并保存训练好的模型到本地,以及未来如何调用保存到模型来预测。

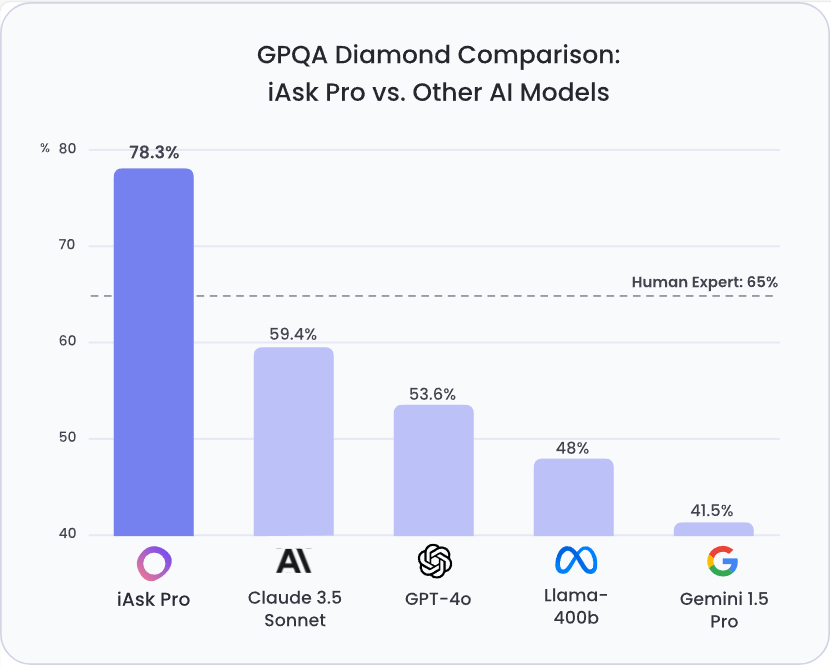
通用人工智能(AGI)的进步需要可靠的评估基准。GPQA (Grade-Level Problems in Question Answering) Diamond 基准旨在衡量模型在需要深度推理和领域专业知识问题上的能力。该基准由纽约大学、CohereAI 及 Anthropic 的研究人员联合发布,其相关论文可在 arXiv 上查阅 (https://arxiv.org/pdf/2311.12022 )。GPQA Diamond是GPQA系列中最高质量的评测数据,包含198条结果。


德国的一位博士生开源了一个使用LoRA(Low Rank Adaptation)技术和PEFT(Parameter Efficient Fine Tuning)方法对Whisper模型进行高效微调的项目。可以让大家在消费级显卡(显存8GB)上对OpenAI开源的WhisperV2模型进行微调!
这篇博客主要翻译自Gregor Heinrich的技术博客Parameter estimation for text analysis,介绍极大似然估计、极大后验估计和贝叶斯参数估计的原理和案例

AI Playground最近的LLaMA2、Stable Diffusion XL等模型的进展也让大家看到了最新最强大的模型的能力。但是,对于大多数人来说,这些模型的使用依然具有较高的门槛,除了硬件资源消耗大,本身的部署也不容易。而支撑这些模型的一个重要的硬件因素就是英伟达的显卡。显卡已经超越一般理财,变得越来越贵。因此,基于大模型的免费服务成本也很高,而今天,英伟达官方的NGC网站推出了新的几款可以免费使用的大模型,包括聊天大模型LLaMA2、文本生成图片大模型Stable Diffusion等,基于

马尔可夫链(Markov Chain)是由马尔可夫性质推导出来的一种重要的概率模型。马尔科夫链是一种离散时间的随机过程,作为现实世界的统计模型,有很多应用。在热力学、统计力学、排队理论、金融领域等都有重要的应用价值。 作为一种离散时间的随机过程,与其对应的模型是马尔可夫过程(Markov Process),这是一种连续时间随机过程的模型。本节将主要介绍马尔科夫链。
Sequence-to-Sequence model
MySQL支持对文本进行全文检索,全文检索可以类似搜索引擎的功能,相比较模糊匹配更加灵活高效且更快。MySQL5.7之后也支持对中文的全文检索,这里描述如何启用MySQL的中文全文检索。
百川智能是前搜狗创始人王小川创立的一个大模型创业公司,主要的目标是提供大模型底座来提供各种服务。虽然成立很晚(在2023年4月份成立),但是三个月后便发布开源了Baichuan系列开源模型,并上架了Baichun-53B的大模型聊天服务。这些模型受到了广泛的关注和很高的平均。而2个月后,百川智能再次开源第二代baichuan系列大模型,其能力提升明显。