元宇宙企业Roblox究竟是一家什么样的企业
美国有一家上市企业,叫做Roblox,号称是元宇宙龙头企业,被市场炒的火热。这家企业到底是什么样的业务,可以被认为是一家纯正的元宇宙企业。本文根据我收集的资料,为大家介绍一下。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
美国有一家上市企业,叫做Roblox,号称是元宇宙龙头企业,被市场炒的火热。这家企业到底是什么样的业务,可以被认为是一家纯正的元宇宙企业。本文根据我收集的资料,为大家介绍一下。

计算机视觉与自然语言处理是近几年人工智能领域进步最快以及应用最为成熟的两个方向。计算机视觉里面任务涉及面广,有很多细分领域,本文将对计算机视觉领域中比较常见的六种任务进行总结并同时展示以下相关任务的一些成绩。

交叉验证是一种用于估计机器学习模型性能的统计方法。它是一种评估统计分析结果如何推广到独立数据集的方法。简单来说,就是将数据集分成不同的部分,然后某些部分训练,某些部分测试,某些部分验证,这样可以最大程度避免过拟合以及测试模型在陌生数据集的性能。

文本生成的主要目的是基于报表和分析生成总结性的文字以辅助商业决策,也就是NLG(Natural Language Generation)。主要的方向包括:基于图表生成洞察报告、基于数据与图表支持问答系统等。本文介绍文字生成的方案提供商。

pandas是Python中一个非常重要的分析工具,在数据处理方面应用非常广泛。但是,也是因为pandas包含的操作很多,所以初学者很多时候也不能特别能理解这些操作。 为了让初学者能够充分理解pandas中的操作,Pandas Tutor将pandas的操作变成可视化的过程,让我们充分理解这个过程。

MLPerf™是MLCommons发布的一个用来测试AI相关软硬件性能的基准测试工具。2021年12月1日, Training v1.1的结果发布,这个结果不仅展示了最新的AI相关软硬件的进展,也有一个新的现象,就是AI训练正在超越摩尔定律。本文将简要解读一下相关数据。

现代软件企业中,SaaS服务提供商是最值得注意的企业。因为SaaS行业规模大利润高,也是最有前景的一类企业。但是,国内市场因为很多因素导致SaaS的规模和空间都比较低。本文梳理一下全球最大的10个SaaS服务提供商,供大家参考。

Pandas和NumPy是Python数据科学领域中最基础的两个库,他们都可以读取大量的数据并对数据做计算等处理。有很多的操作他们都能做。那么,这两个Python库在数据处理的性能上有什么差别呢?今天在Reddit上看到一个有意思的讨论和大家分享一下。
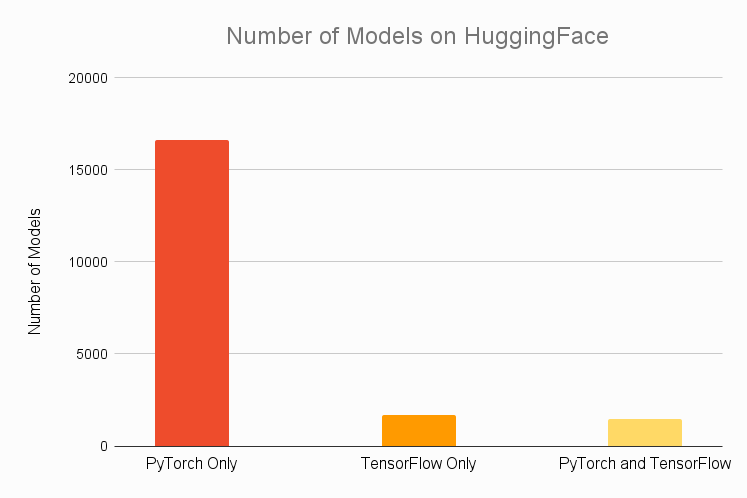
Tensorflow和PyTorch是深度学习最流行的两个框架,二者都有坚定的支持者。一般认为由于Google的支持,TensorFlow的社区支持比较好,在工业应用广泛。但是尽管有keras加持,但易用性方面依然被认为不如PyTorch。而后者最早由Facebook人工智能团队开发。由于其易用性,被认为在科学研究中有广泛使用。那么,最近几年二者发展如何,是否实际还如之前的观点一样,这里AssemblyAI的一个作者做了一些对比。
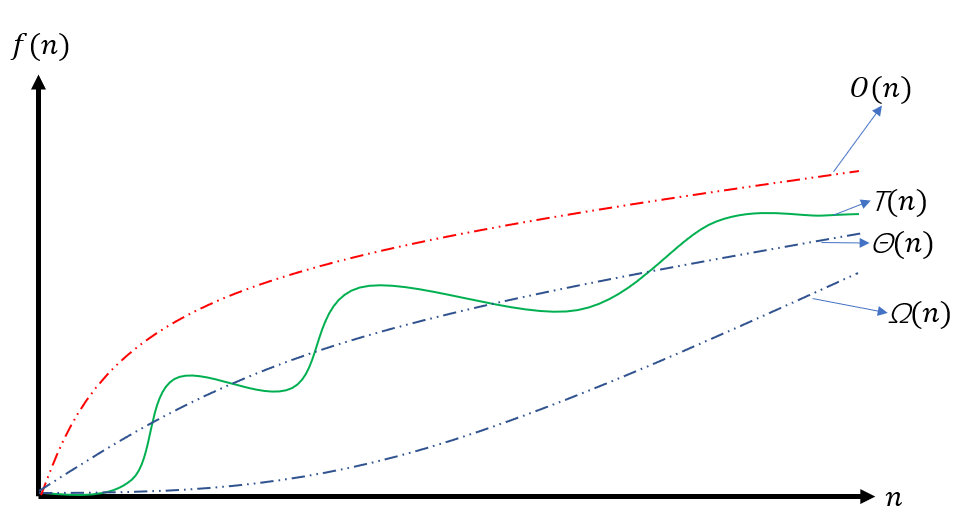
在程序设计和编程中,我们经常会看到关于时间复杂度的讨论。比如为什么A方法比B方法好?是因为A方法的时间复杂度低。那么,这里的时间复杂度如何去理解,又怎么计算呢?常见的O(n)的含义是什么?本文将简单的解释这个概念。

这几天逛reddit的时候发现了一个很有意思的讨论,有个童鞋说他在GitHub上提交代码的时候发现了提交文件被提示有一个红色警告的提示,鼠标移动上去会告诉你“No newline at end of file”(也就是文件末尾没有换行)。因此,他很奇怪,他不懂为什么GitHub要求文件的末尾必须有换行符。这个问题引起了很多的讨论。这里我也顺便记录共享一下。

去年5月份的时候,Python创始人Guido van Rossum在参加Language Summit时候说他希望Python3.11能在性能上获得巨大的提升,可以实现性能翻倍。目前看,似乎已经有了很大的希望!

OpenAI在3月15日发布了一个最新的GPT-3和Codex的版本,这个版本最大的能力就是可以在已有的文本上插入或者编辑新的内容。而不是续写已有的文本。这个能力最大的应用就是重写已有文本,或者用来重构代码。
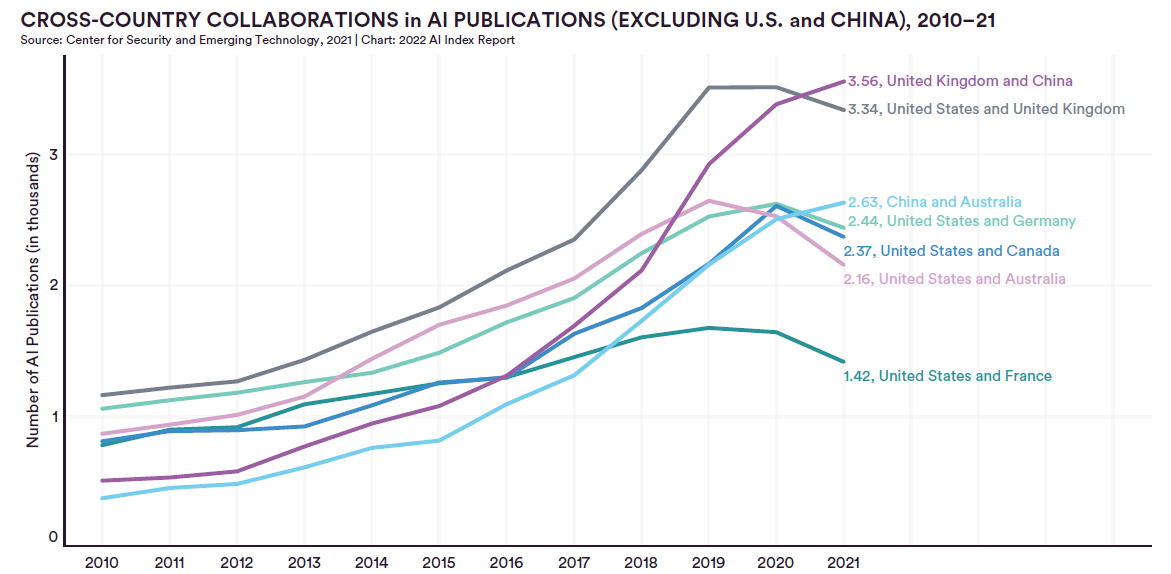
人工智能指数是斯坦福大学以人为本人工智能研究所(Stanford Institute for Human-Centered Artificial Intelligence (HAI))联合学术界、工业界的专家一起发布的人工智能相关的发展报告。2022年度AI指数报告在近几日发布。

前几天,北京智源人工智能研究院引入了一个名为WuDaoMM的大规模多模态语料库,总共包含超过6.5亿对图像-文本。具体来说,约有6亿对数据是从图像和标题呈现弱相关的多个网页中收集的,另外5000万对强相关的图像-文本是从一些高质量的图片网站中收集的。
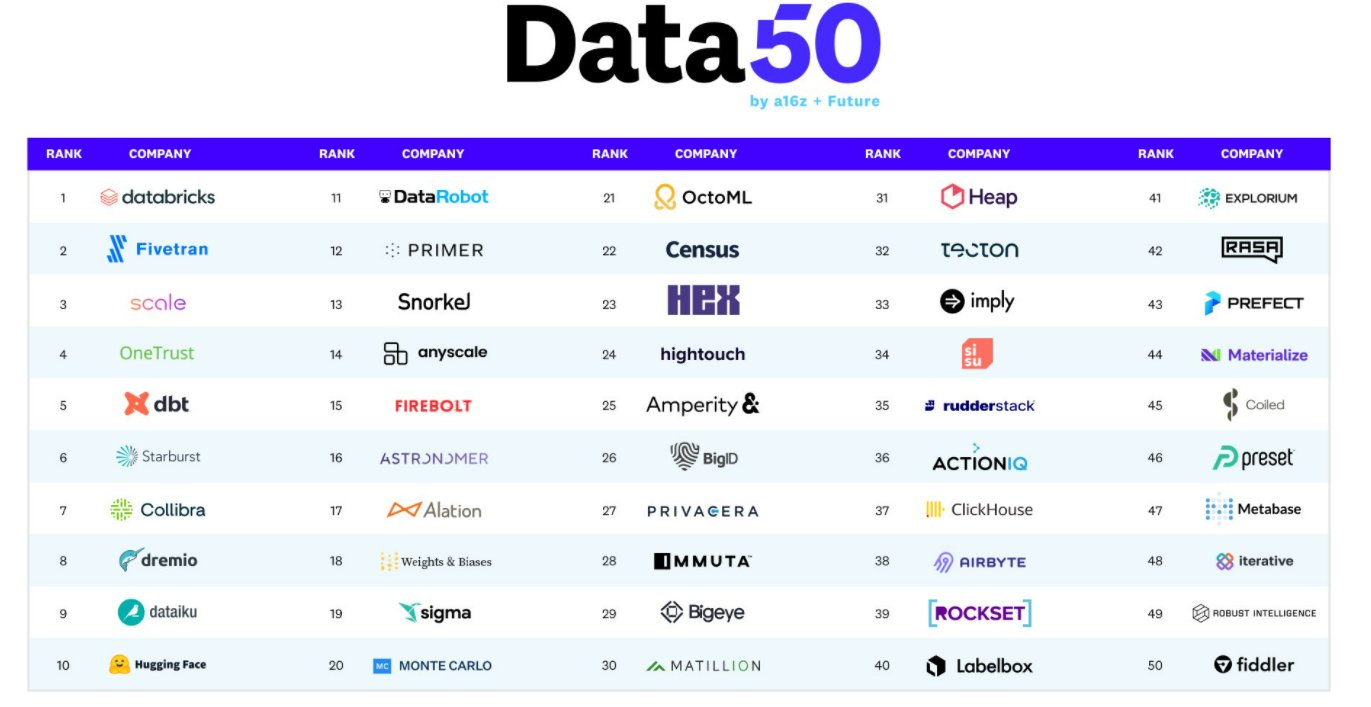
最近几年,数据的重要性在各个领域都获得了巨大的重视。因此,数据管理相关的业务也成为各项基础设施中增长最快的业务,目前的市场规模约700亿美元,占所有企业的基础设施支持约1/5。仅在2021年,数据处理相关的公司获得了数百亿的风险投资。为此,Future总结了2022年全球最大的50家数据创业企业。这里我们列举其中的最大的10个进行介绍。

CVPR2022的一篇论文带来了一个39亿参数的自回归图像模型公开了他们的代码和论文。
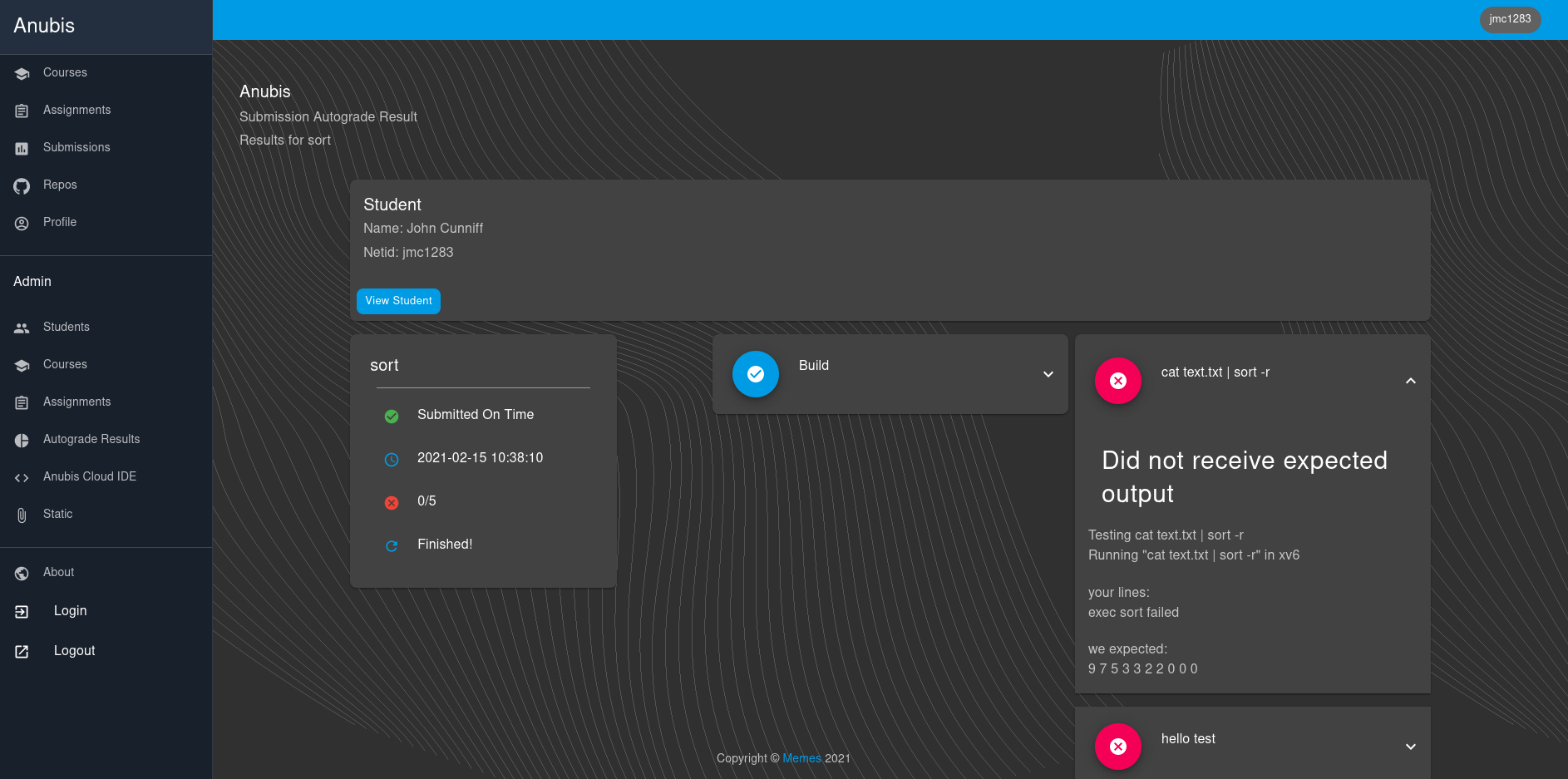
Anubis是一个分布式LMS(学习管理系统),由John Cunniff创建,专门为CS课程的自动化而设计。Anubis已经在纽约大学坦登分校使用并经过了几个学期的测试。这个系统的主要目的是自动为提交的作业评分,并提供了一个云IDE解决方案,以简化学生的体验。

大家都知道,编程的开发离不开互联网的支持,不管是编程的学习还是bug的修复,都需要社区和外部的支持。因此,我们全新开通了一个程序必备网站列表栏目,为大家提供一站式访问目录。也欢迎评论,大家可以说一下你们写代码时候喜欢用的网站,我们也会更新上去。在这里我们挑选几个必备网站简单介绍一下。

仅仅使用来自人类数据集的机器学习,在短短9个小时内,日本研究人员让一个机器人学会了如何拿起和剥开香蕉。
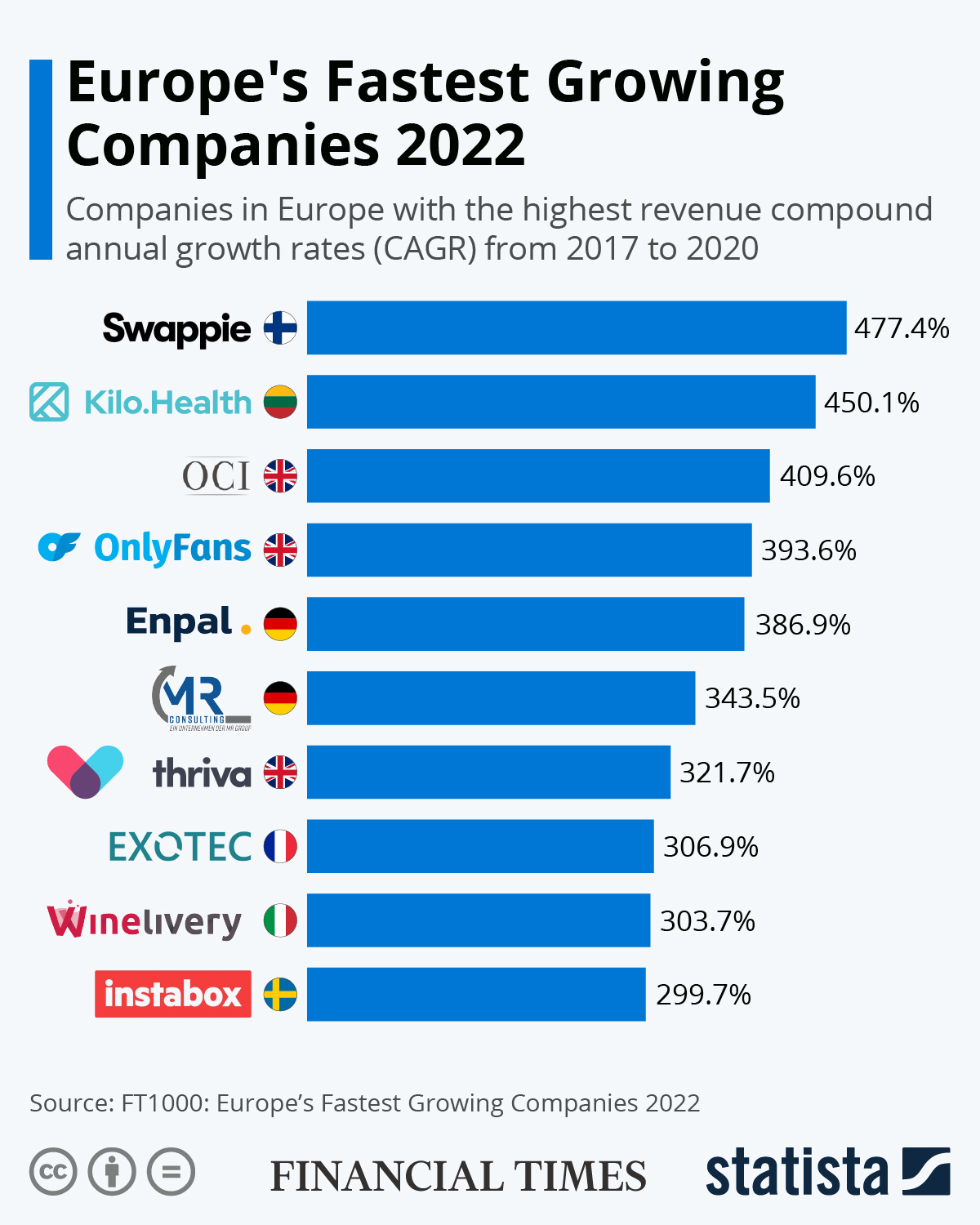
FT1000是金融时报评选的欧洲增长速度最快的前1000个公司,这个名单可以看出来过去几年欧洲哪些企业增长较快,它们在哪些行业经营等。2022年的榜单也刚刚发布,让我们一睹为快。

Firebolt开发了一个数据工程师的网页小游戏,带你体验数据分析的全流程。游戏里你扮演一个数据工程师,从数据收集开始,经历数据pipeline、数据入数据湖以及数据分析等,最终形成各种图表的结果。

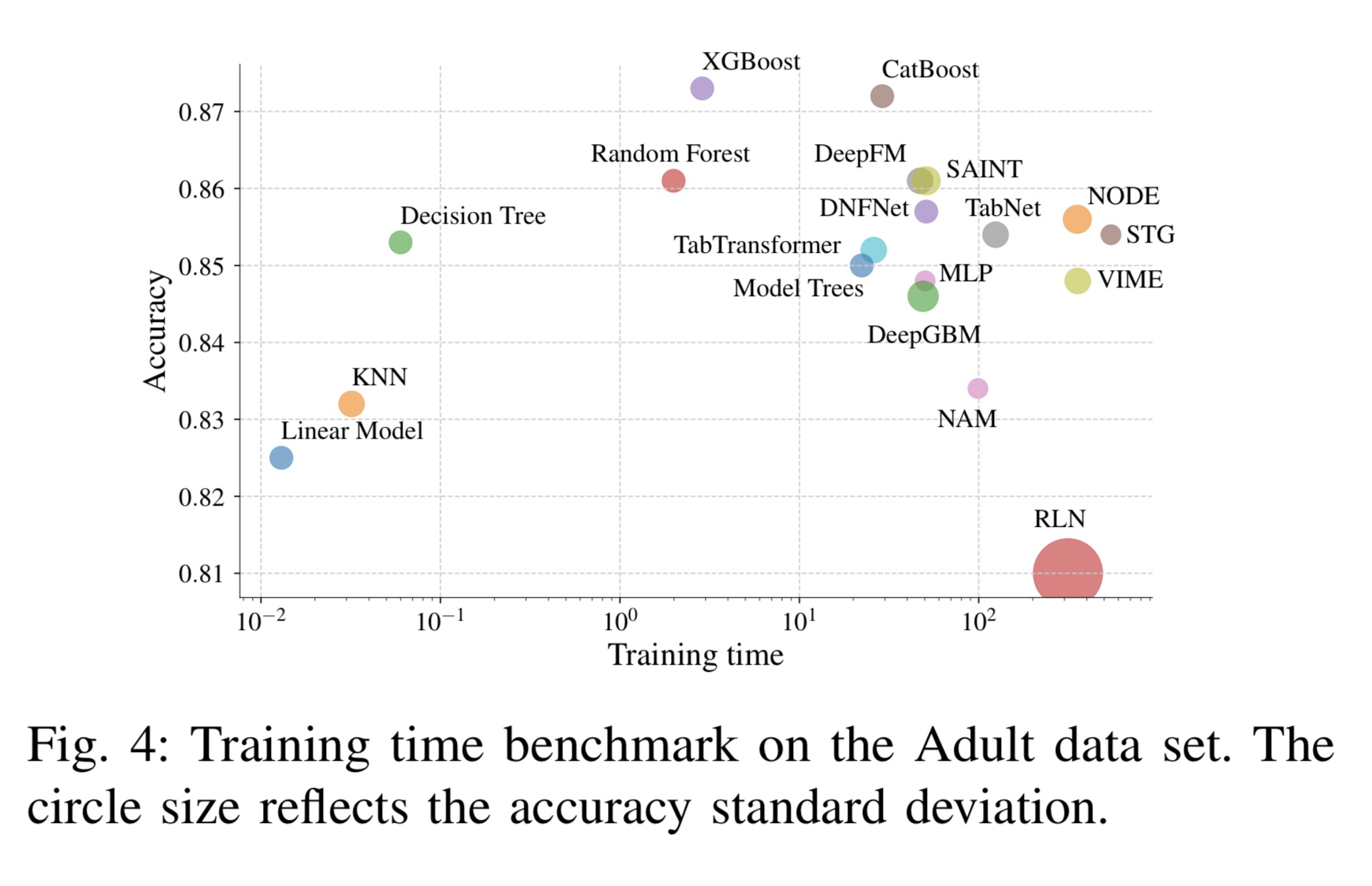
异质表格数据是最常用的数据形式,对于众多关键和计算要求高的应用来说是必不可少的。在同质数据集上,深度神经网络已多次显示出优异的性能,因此被广泛采用。然而,它们在表格数据建模(推理或生成)方面的应用仍然具有高度挑战性。