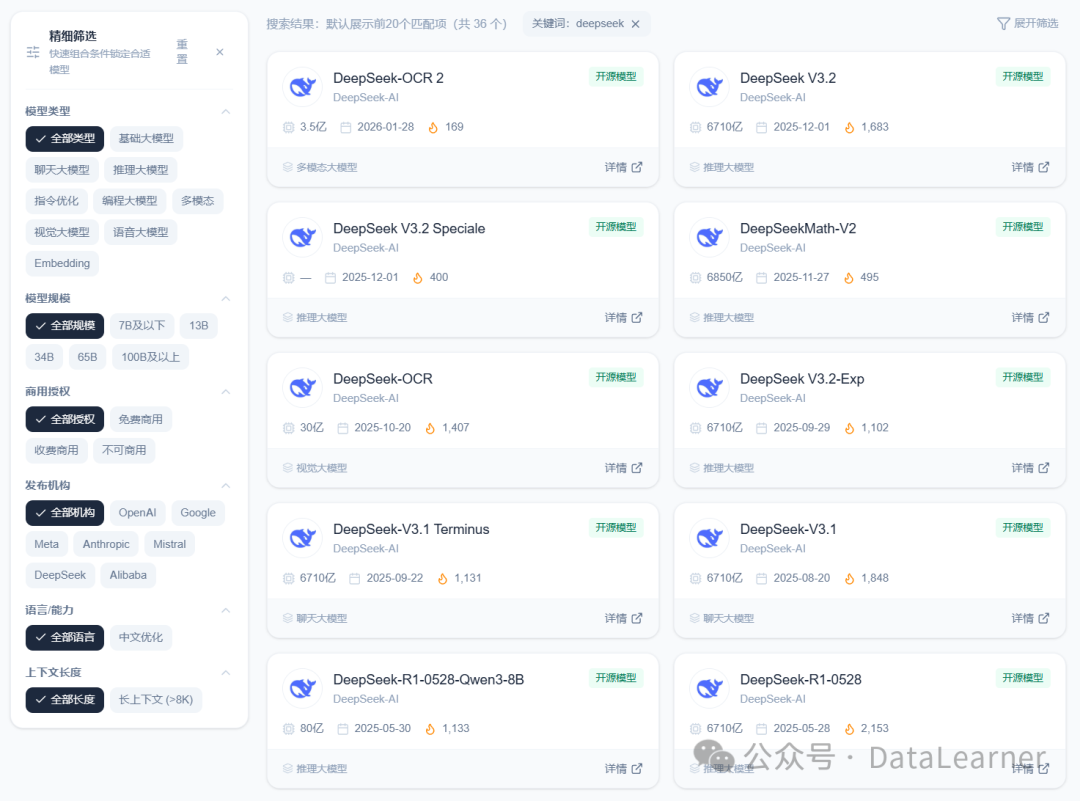
DeepSeek官网模型疑似更新为DeepSeek最新版,实测显示非此前的DeepSeek V3.2,最高支持100万tokens输入,以及知识截止日期为2025年5月,疑似全新模型
就在刚才,很多人发现DeepSeek官网已经更新了模型,虽然不确定是DeepSeek-V4,但是目前可以肯定,这不是之前公布的DeepSeek-V3.2而是一个全新的模型。为此,DataLearnerAI实测正式,这个模型的确并非此前的版本。
汇总「DeepSeek」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
就在刚才,很多人发现DeepSeek官网已经更新了模型,虽然不确定是DeepSeek-V4,但是目前可以肯定,这不是之前公布的DeepSeek-V3.2而是一个全新的模型。为此,DataLearnerAI实测正式,这个模型的确并非此前的版本。

几个小时前,DeepSeek 突然发布了两款全新的推理模型:DeepSeek V3.2 正式版与DeepSeek V3.2-Speciale。前者已经全面替换官方网页、App 与 API 成为新的默认模型;后者则以“临时研究 API”的方式开放,被定位为极限推理版本。

DeepSeek AI团队重磅推出DeepSeek-OCR,该模型不仅在文档提取上达到了行业领先水平,更通过创新的视觉压缩技术,将长上下文处理效率提升了 10 倍以上。根据测算,在A100-40G的一个GPU上,它每天可以将20万页的文档图像数据转为Markdown文本!

就在几个小时前,DeepSeekAI宣布官方的聊天模型从DeepSeek-V3升级到了DeepSeek-V3.1,上下文拓展至128K。虽然,官方目前没有给出这个模型的详细信息,DataLearnerAI已经搜集到很多信息供大家参考。
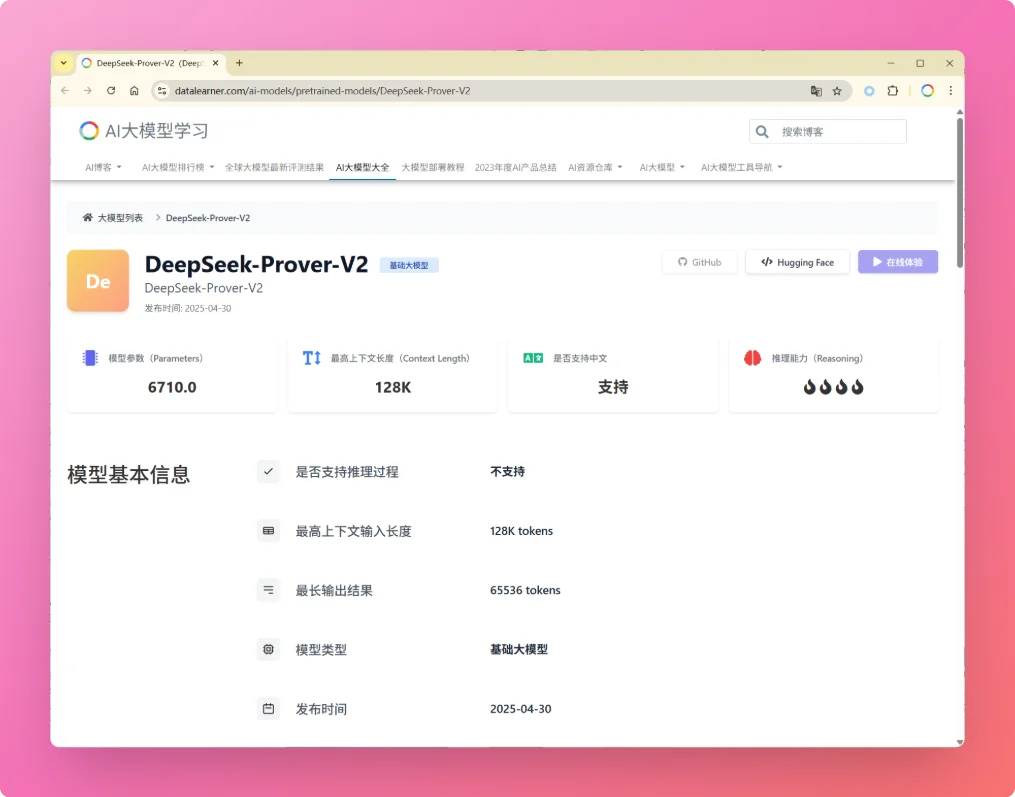
就在刚才,DeepSeek-AI发布了其新一代自动定理证明模型 **DeepSeek-Prover-V2**。尽管官方暂未公开详细报告,但从其前代模型 **DeepSeek-Prover-V1.5** 的技术细节,以及去年底发布的通用推理模型 DeepSeek-R1 的进展来看,V2 很可能在多个关键能力上取得了实质性提升。
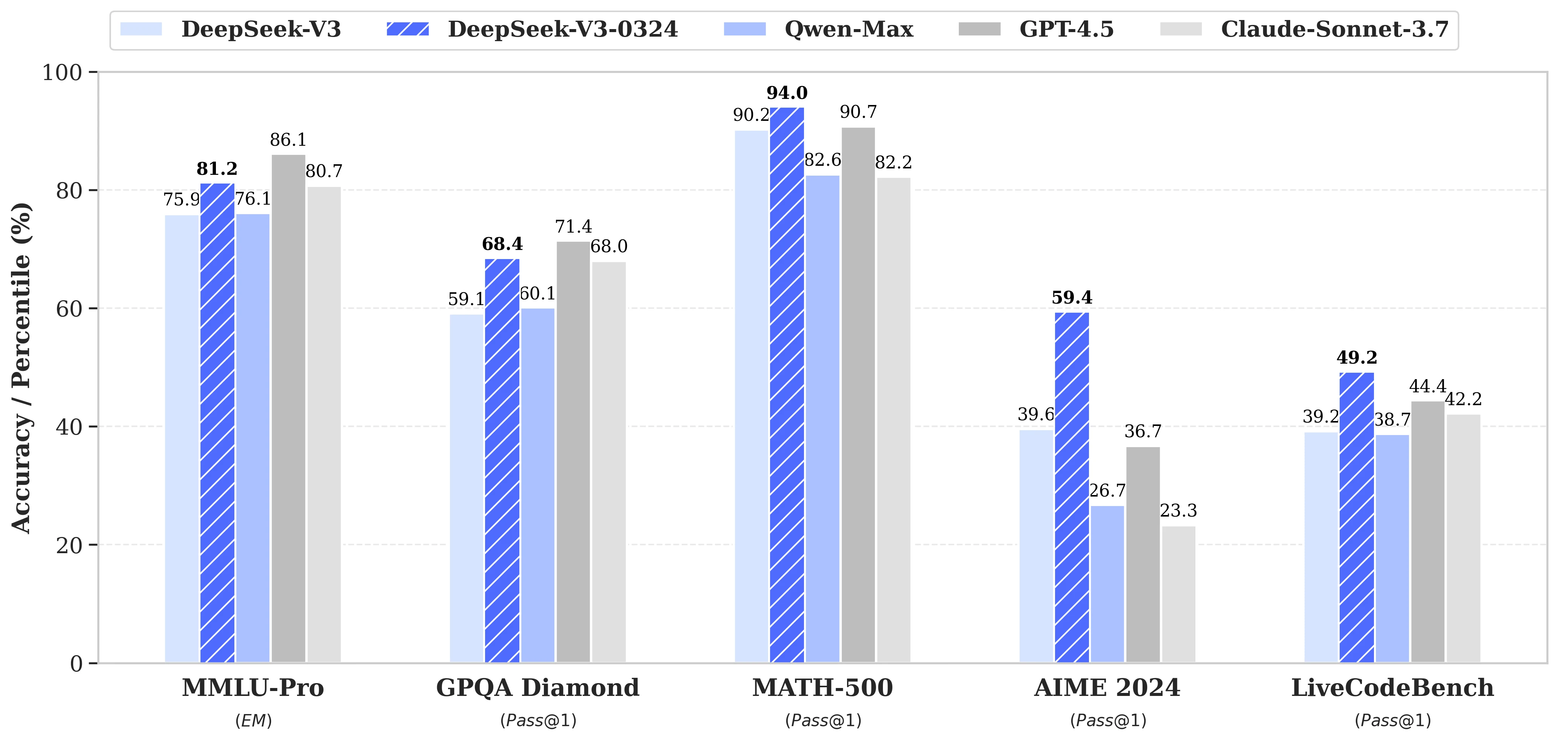
2025年3月25日,DeepSeekAI低调开源了DeepSeek-V3-0324大模型。作为DeepSeek-V3的重要升级版本,该模型在推理能力、中文写作、前端开发以及功能调用等多个关键领域实现了显著提升。在MMLU Pro等评测上,已经成为了非推理大模型中最强的模型,部分评测结果超过GPT-4.5模型。

随着DeepSeek R1和OpenAI的o1、o3等推理大模型的发布,我们当前可使用的大模型种类也变多了。但是,推理大模型和普通大模型之间并不是二选一的关系,在不同的问题上二者各有优势。为了让大家更清晰理解推理大模型和普通大模型的应用场景。OpenAI官方推出了一个推理大模型最佳实践指南。描述了二者的对比。本文将总结这份推理大模型最佳实践指南。

最近,随着DeepSeek R1的火爆,推理大模型也进入大众的视野。但是,相比较此前的GPT-4o,推理大模型的区别是什么?它适合什么样的任务?推理大模型是如何训练出来的?很多人并不了解。本文将详细解释推理大模型的核心内容。
DeepSeekAI最近发布的几个模型,如DeepSeek V3、DeepSeek R1等引起了全球的广泛关注和讨论,特别是低成本训练出高质量模型之后,引起了很多的争论。引起了大家对OpenAI、英伟达等公司未来的质疑。然而,对于DeepSeekAI的模型为什么引起了如此广泛的关注,以及大家讨论的核心内容是什么,很多人并不是很清楚。本文基于著名的独立科技行业分析师Ben Thompson的总结,配合DataLearnerAI的分析,为大家总结DeepSeek引起的全球讨论。
OpenAI的o1模型被认为是大模型领域中推理能力最强的代表之一,由于其强大的数学逻辑推理能力,被认为是大模型未来的进化方向。而就在2个月之后的11月快结束的时间里,幻方量化旗下人工智能企业DeepSeekAI发布了全新的DeepSeek-R1-Lite-Preview模型,号称是o1模型的有力挑战者。该模型利用了类似的o1的思维链思索过程,推理能力大幅增强。DataLearnerAI将在本文中对该模型进行介绍,并进行几个简单的对比结果测试。结果证明这个模型是非常优秀的!
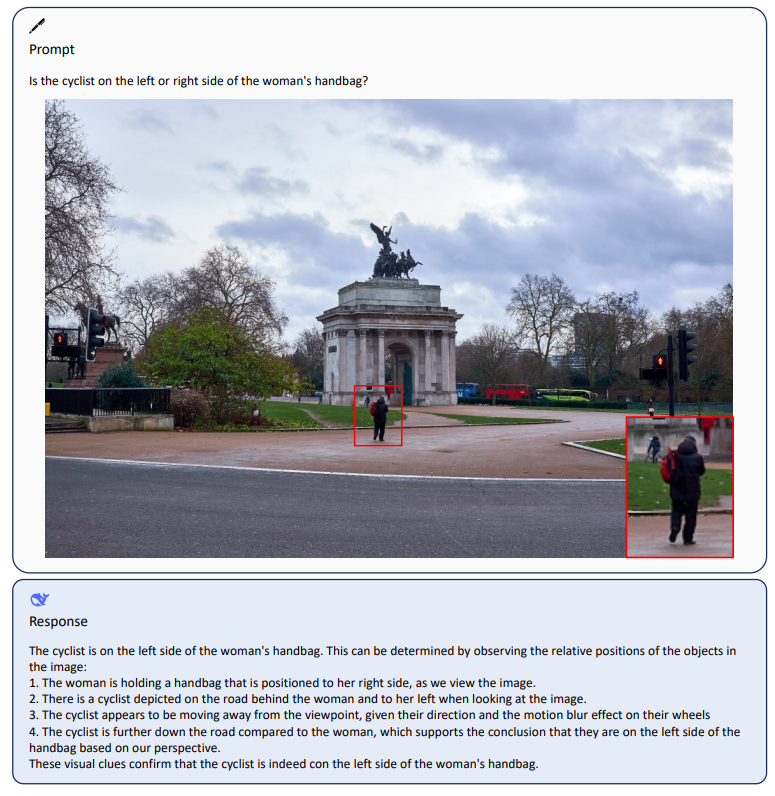
深度求索是著名量化机构幻方量化旗下的一家大模型初创企业,成立与2023年7月份。他们开源了很多大模型,其中编程大模型DeepSeek-Coder系列获得了非常多的好评。而在今天,DeepSeek-AI再次开源了全新的多模态大模型DeepSeek-VL系列,包含70亿和13亿两种不同规模的4个版本的模型。
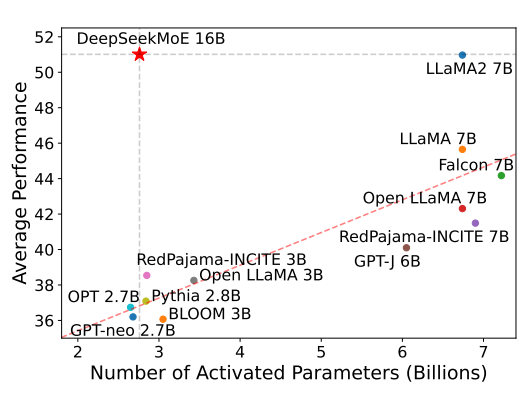
混合专家(Mixture of Experts)是大模型一种技术,这个技术将大模型划分为不同的子专家模型,每次推理只选择部分专家网络进行推理,在降低成本的同时保证模型的效果。此前Mistral开源的Mixtral-8×7B-MoE大模型被证明效果很好,推理速度很棒。而幻方量化旗下的DeepSeek刚刚开源了可能是国产第一个MoE技术的大模型,DeepSeek-MoE 16B。