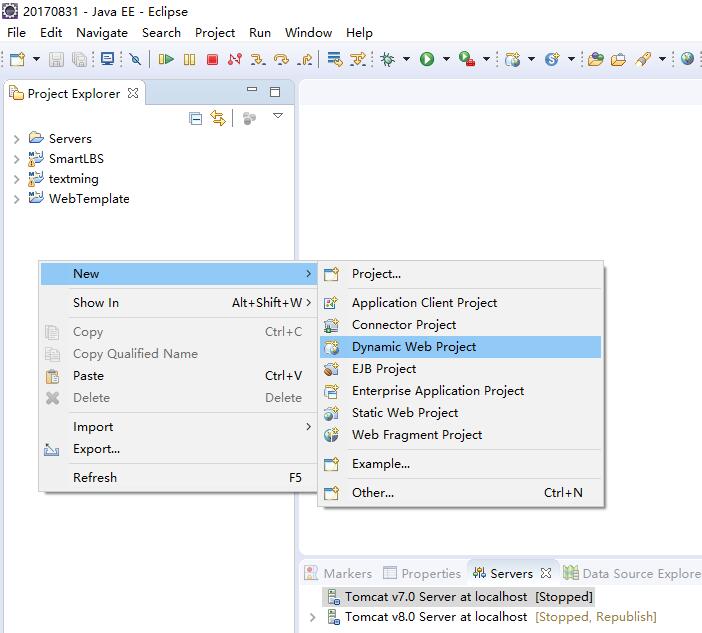
使用SpringMVC创建Web工程并使用SpringSecurity进行权限控制的详细配置方法
使用SpringMVC框架搭建Web项目工程是目前非常流行的web项目创建方式。同时Spring Security也为我们提供了登录验证和权限控制等内容。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
使用SpringMVC框架搭建Web项目工程是目前非常流行的web项目创建方式。同时Spring Security也为我们提供了登录验证和权限控制等内容。
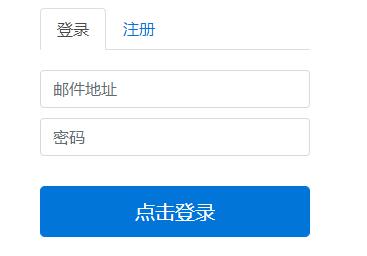
Spring Security可以帮助我们进行页面的权限控制和登录验证,在这篇博客中,我们将简要描述如何使用Spring Security进行登录验证。

在Android开发中,我们经常会遇到很多问题,这里记录了一些常见的问题及其解决方法

本文简要介绍了SCI/SCI-E/SSCI的区别以及相关期刊验证查询方法

数据科学项目为我们提供了很好的机会提升我们的技能和知识。这篇博客提供了17个数据科学的项目,都是可以免费获取的项目,大家可以通过这些诶项目学习数据科学相关知识。
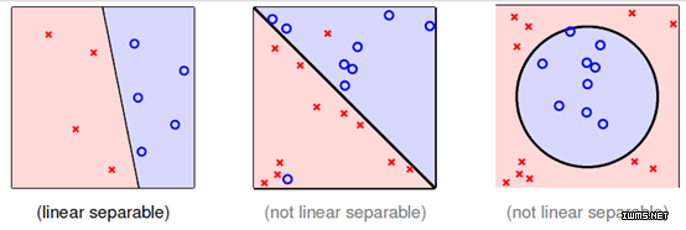
在机器学习或者深度学习中,正则项是我们经常遇到的概念。它对提高模型的准确性和泛化能力非常重要。本文详细描述了正则项的来源以及与其他概念的相关关系。
腾讯AI Lab去年四月成立,今年是首次参加ICML,共计四篇文章被录取,位居国内企业前列。此次团队由机器学习和大数据领域的专家、腾讯AI Lab主任张潼博士带领到场交流学习,张潼博士还担任了本届ICML领域主席。在本次130人的主席团队中,华人不超过10位,内地仅有腾讯AI Lab、清华大学和微软研究院三家机构。
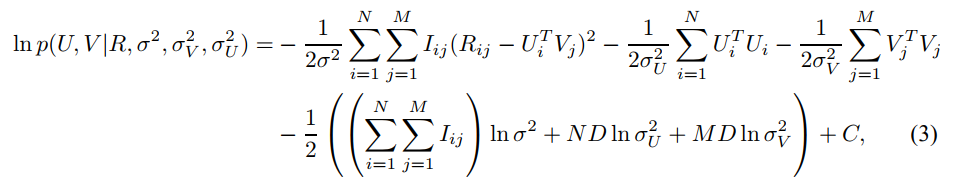
本篇博客详细说明了概率矩阵分解(Probabilistic Matrix Factorization,PMF)的推导过程
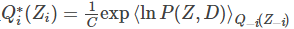
变分贝叶斯是一类用于贝叶斯估计和机器学习领域中近似计算复杂(intractable)积分的技术。它主要应用于复杂的统计模型中,这种模型一般包括三类变量:观测变量(observed variables, data),未知参数(parameters)和潜变量(latent variables)。
Wishart分布在多元高斯的贝叶斯推断中非常重要。它通常作为正态分布的协方差矩阵的逆矩阵的共轭先验存在。这篇博客将详细讲述Wishart分布及其作用。
多元正态(高斯)分布分布是我们最常用的分布之一,这篇博客的主要内容来自Will Penny的文章的翻译。主要讲述关于多元正态分布的贝叶斯推导
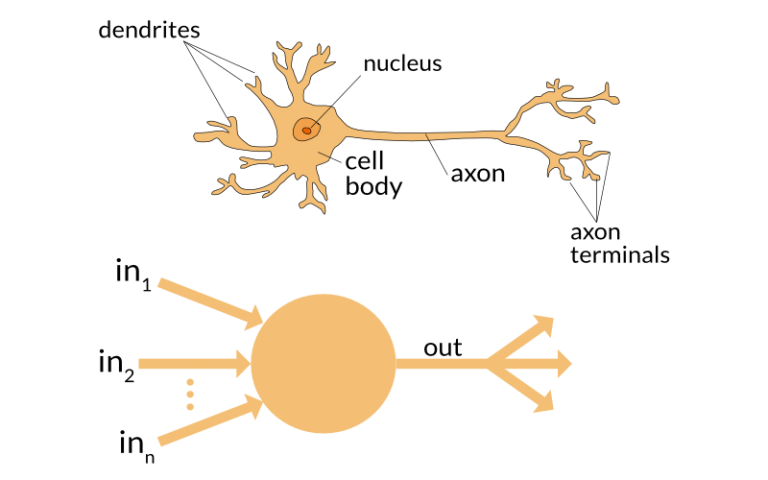
这篇博客是来自Analytics Vidhya的一篇文章。写的很不错。
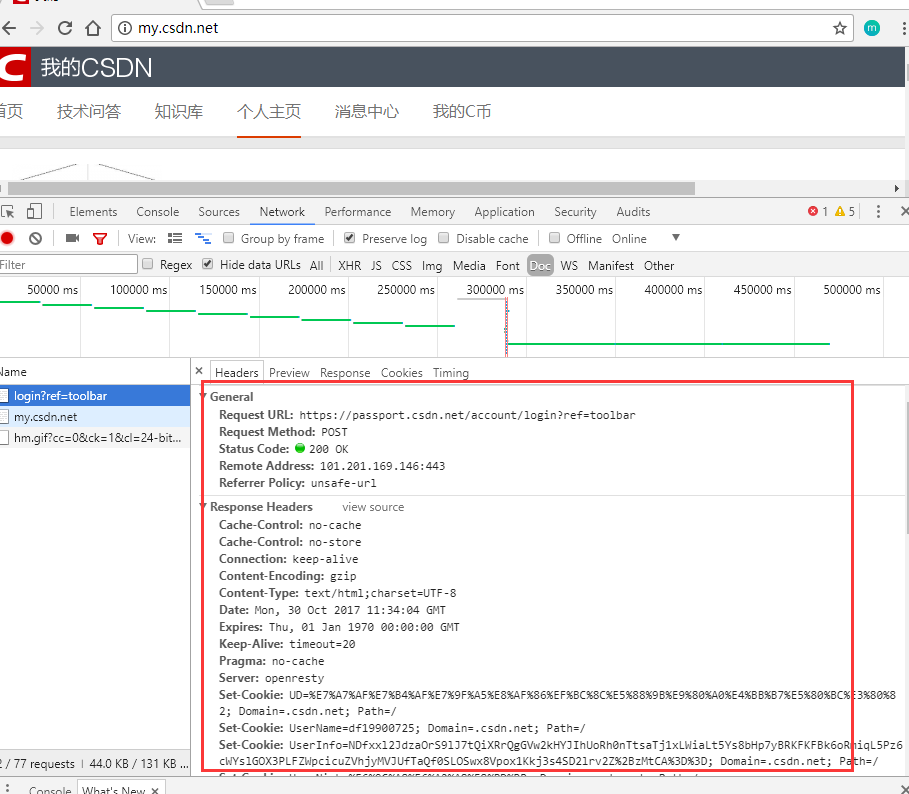
网络爬虫需要解决的一个重要的问题就是要针对某些需要用户名和密码访问的页面可以模拟用户自动登录。在这一篇博客中我们将介绍如何使用Chrome浏览器自带的抓包工具分析页面并模拟用户自动登录
这篇博客主要介绍了文本预处理的一般步骤以及常见的自然语言处理任务简介。

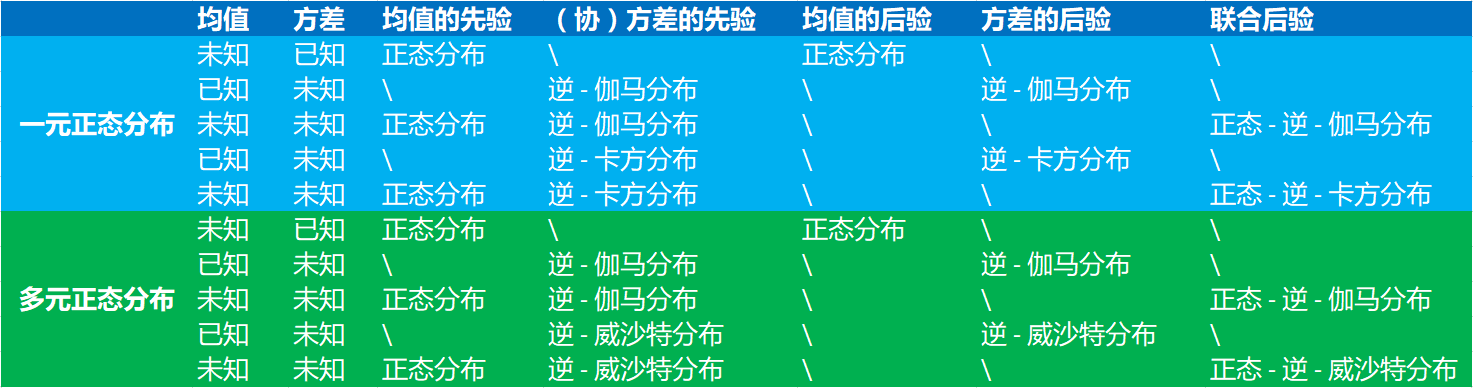
高斯分布是最常见的分布,也是数据挖掘和人工智能中相关统计学习方法所涉及到的最重要的分布之一。使用贝叶斯理论进行统计推断是目前最流行的推断方式。
抽取样本方差的分布可以帮助我们生成很多其他分布的样本,例如生成一元高斯分布的样本就是可以通过方差分布来产生。这篇博客将描述如何抽取样本方差的分布。
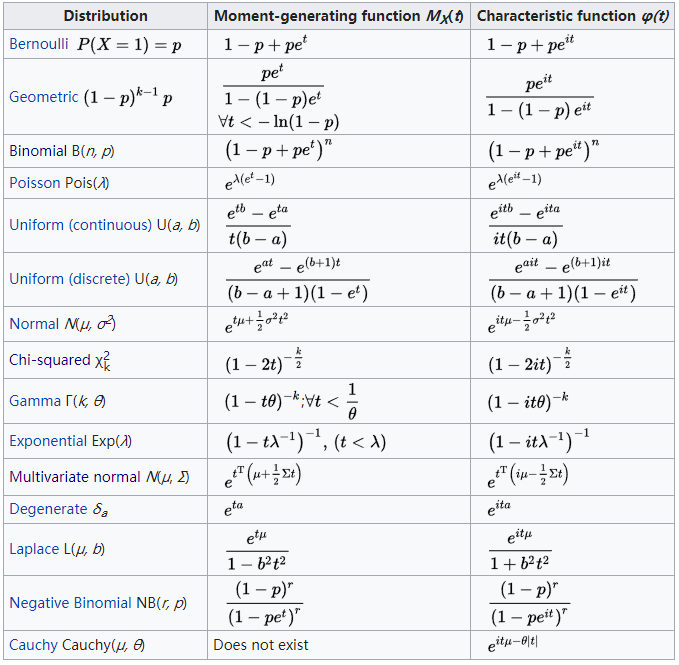
在统计学中,矩母函数是一个关于随机变量的实值函数,它可以替代密度函数来描述分布。也就是说,出了概率密度函数外,我们也可以通过矩母函数来描述分布。
eclipse创建导入项目的时候经常会发生各种错误。本篇博客将讲述常见的错误及其解决方案。
在回归模型中加入交互项是一种非常常见的处理方式。它可以极大的拓展回归模型对变量之间的依赖的解释。本篇博客将简要介绍这个交互项。
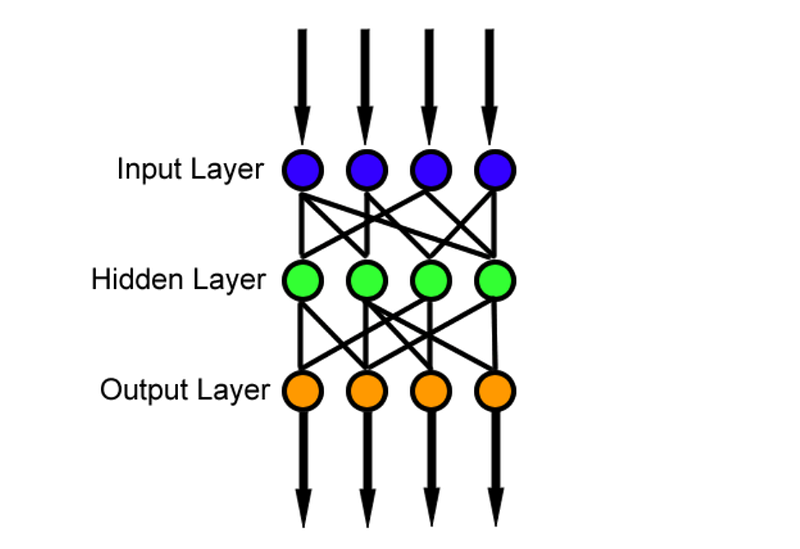
深度学习是计算机领域中目前非常火的话题,不仅在学术界有很多论文,在业界也有很多实际运用。本篇博客主要介绍了三种基本的深度学习的架构,并对深度学习的原理作了简单的描述。本篇文章翻译自Medium上一篇入门介绍。
在进行编程操作的时候,我们常常会遇到很多与编程无关的项目管理工作,如下载依赖、编译源码、单元测试、项目部署等操作。一般的,小型项目我们可以手动实现这些操作,然而大型项目这些工作则相对复杂。构建工具是帮助我们实现一系列项目管理、测试和部署操作的工具。本文将对Java构建工具做简单介绍。
使用SVN进行项目的版本管理是非常流行的操作,这篇博客将描述Eclipse安装SVN的方法。
SVN是Subversion的简称,是一个开放源代码的版本控制系统,相较于RCS、CVS,它采用了分支管理系统,它的设计目标就是取代CVS。互联网上很多版本控制服务已从CVS迁移到Subversion。说得简单一点SVN就是用于多个人共同开发同一个项目,共用资源的目的。