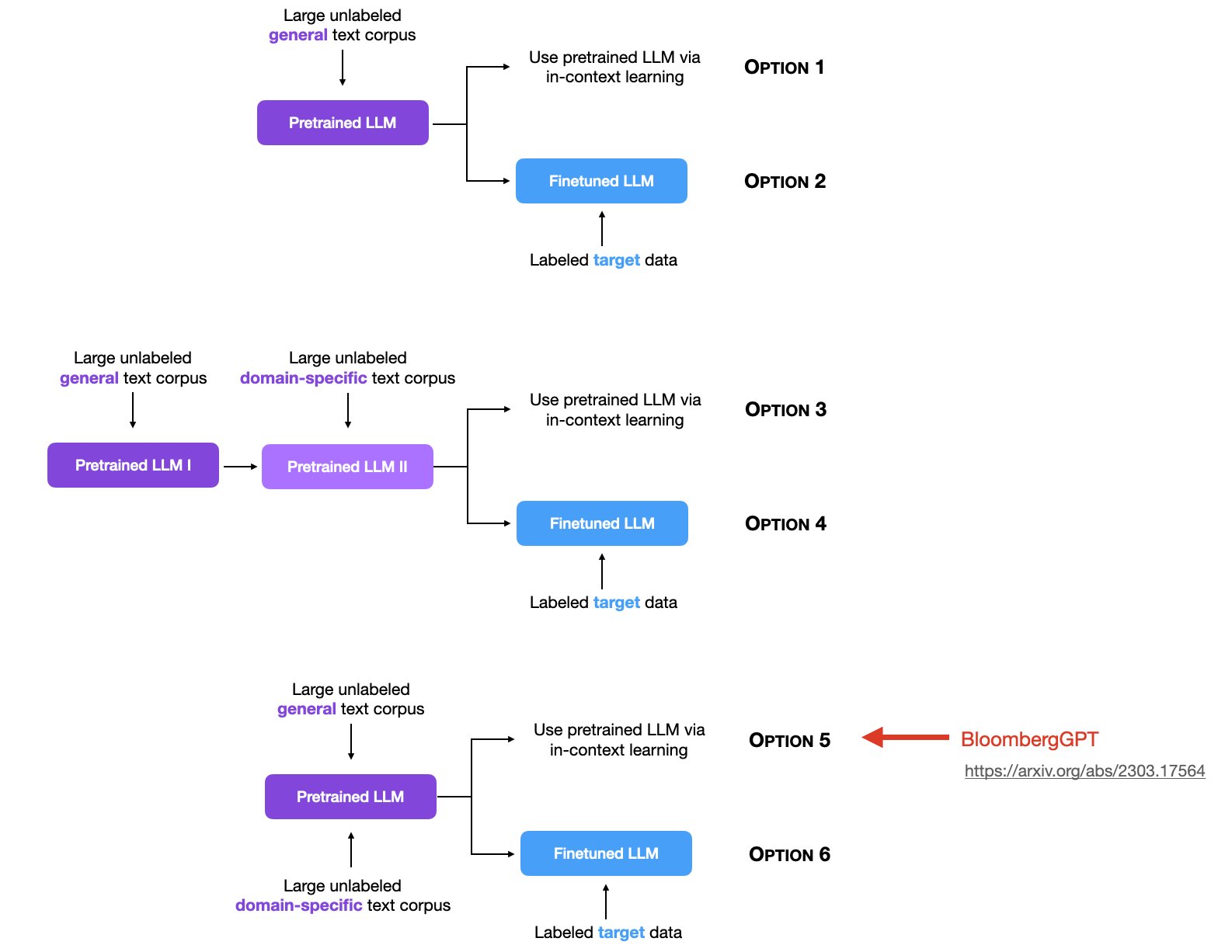
6种大模型的使用方式总结,使用领域数据集持续做无监督预训练可能是一个好选择
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的简介,也贡献了许多有价值的内容。在最新的一期统计中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于使用领域数据集做无监督预训练是目前讨论较少,但十分重要的一个方向。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的简介,也贡献了许多有价值的内容。在最新的一期统计中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于使用领域数据集做无监督预训练是目前讨论较少,但十分重要的一个方向。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。

随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前领先的预训练模型使用的数据集细节往往不公开,开源数据的匮乏制约着研究社区的进一步发展。特别是大规模中文数据集十分缺乏,对中文大模型以及业界模型的中文支持都有很大的影响。此次,上海人工智能实验室发布的这个数据集包含了丰富的中文,对于大模型的中文能力提升十分有价值。

Allen Institute for AI简称AI2,是2014年成立的一个非营利性研究组织,其创办者是之前的微软联合创始人Paul G. Allen。目前该组织主导了几个非常大的项目,希望借助AI来推动科学、医学等领域的进步。此前也开源过大模型OLMo等。这次是该组织第一份发布AI数据集相关的项目,名称位Dolma,是一个包含了3万亿tokens的数据集,目前第一版本仅仅包含英文。

开源大语言模型的发展非常迅速,其强大的能力也吸引了很多人的尝试与体验。尽管预训练大语言模型的使用并不复杂,但是,因为其对GPU资源的消耗很大,导致很多人并不能很好地运行加载模型,也做了很多浪费时间的工作。其中一个比较的的问题就是很多人并不知道自己的显卡支持多大参数规模的模型运行。本文将针对这个问题做一个非常简单的介绍和估算。

SAM全称是Segment Anything Model,由MetaAI最新发布的一个图像分割领域的预训练模型。该模型十分强大,并且有类似GPT那种基于Prompt的工作能力,在图像分割任务上展示了强大的能力!此外,该模型从数据集到训练代码和预训练结果完全开源!真Open的AI!

Whisper是由Open AI训练并开源的语音识别模型,它在英语语音识别方面接近人类水平的鲁棒性和准确性。该模型于2022年9月21日发布之后引起了广大的关注。由于模型的准确性太过惊人,大家已经认为可以直接用于视频的配音制作了。而今天有人发现Whisper的GitHub上有了一个新的提交记录,显示Whisper V2版本即将来临。
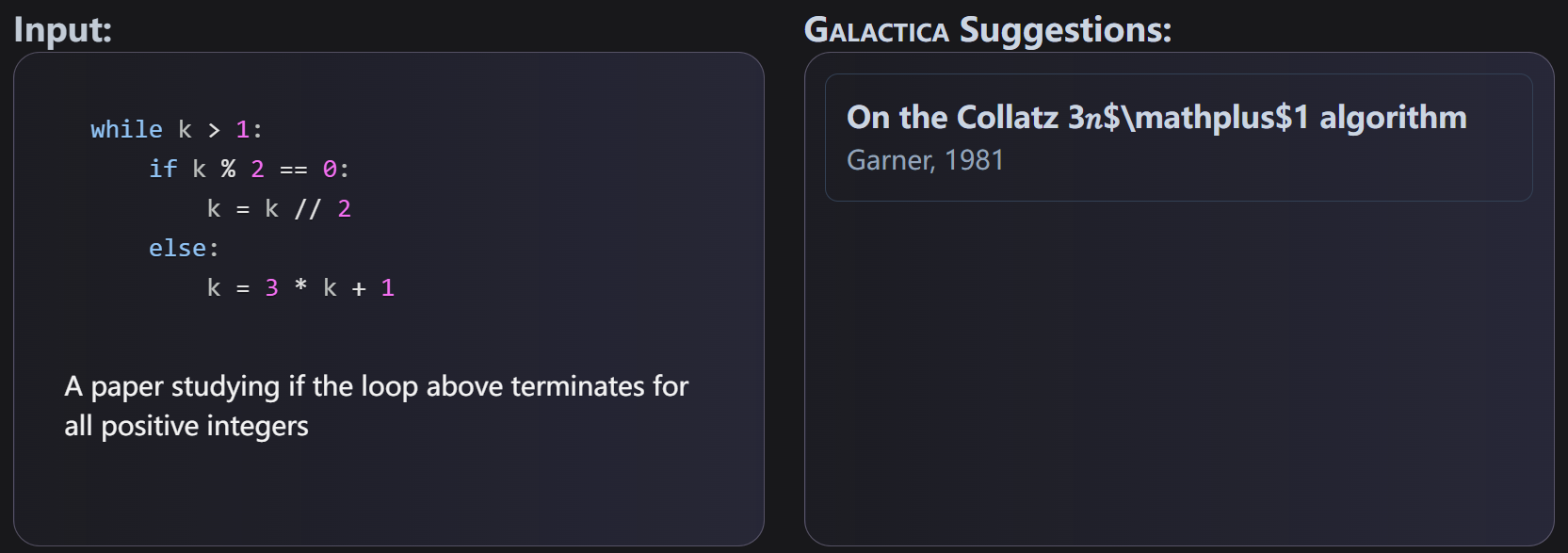
自然语言处理预训练大模型在最近几年十分流行,如OpenAI的GPT-3模型,在很多领域都取得了十分优异的性能。谷歌的PaLM也在很多自然语言处理模型中获得了很好的效果。而昨天,PapersWithCode发布了一个学术论文处理领域预训练大模型GALACTICA。功能十分强大,是科研人员的好福利!
近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。

随着NLP预训练模型的发展,大语言模型在各个领域的作用也越来越大。几个月前,GitHub基于OpenAI的GPT-3训练的Copilot效果十分惊艳,可惜现在已经开始收费。而最近,清华大学也发布了一个代码补全神器——CodeGeeX。
大规模的text-to-image模型没有公开预训练结果,OpenAI的意思就是我这玩意太厉害,随便放出来可能会被你们做坏事,而谷歌训练这个应该就是为了云服务挣钱,所以都没有公开可用的版本供大家玩耍。虽然业界有基于论文的实现,但是训练模型需要耗费大量的资源,没有开放的预训练结果,我们普通个人也很难玩起来。但是,大神Sahar提供了一个免费使用开源实现的text-to-image预训练模型的方式。
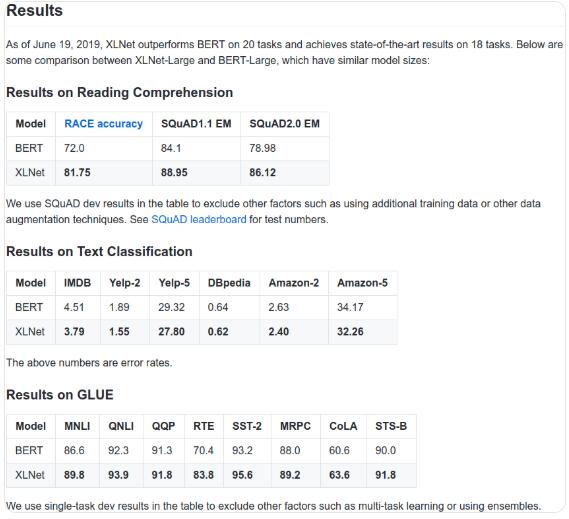
前几天刚刚发布的XLNet彻底火了,原因是它在20多项任务中超越了BERT。这是一个非常让人惊讶的结果。之前我们也说过,在斯坦福问答系统中,XLNet也取得了目前单模型第一的成绩(总排名第四,前三个模型都是集成模型)。
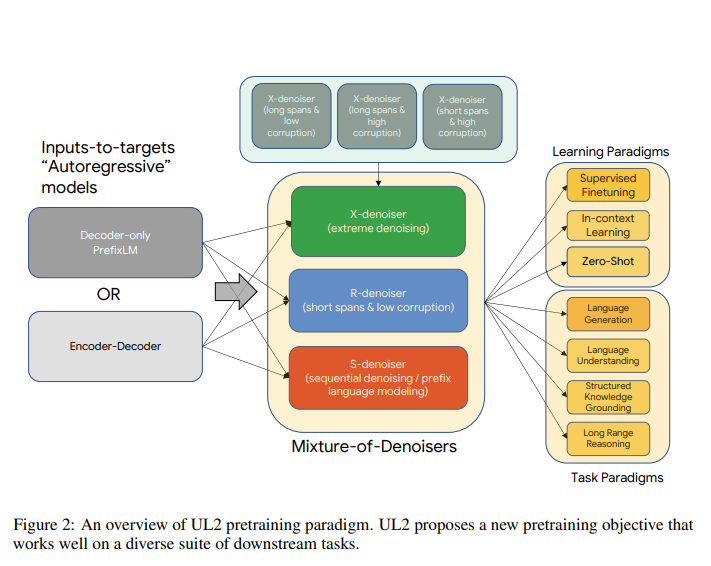
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。 而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。

使用预训练模型处理NLP任务是目前深度学习中一个非常火热的领域。本文总结了8个顶级的预训练模型,并提供了每个模型相关的资源(包括官方文档、Github代码和别人已经基于这些模型预训练好的模型等)。