预训练大模型时代必备技能——Prompt Tuning简介
通过调整提示文本,可以使语言模型更好地理解任务的要求和上下文,从而提高其在特定任务上的表现。Prompt tuning是使大型语言模型更加智能和高效的关键步骤之一。只有通过精心设计和优化提示文本,我们才能充分发挥大型语言模型的潜力,并使其更好地服务于人类的需求。因此,Prompt engineering,这一种新的工程能力也开始变得重要。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
通过调整提示文本,可以使语言模型更好地理解任务的要求和上下文,从而提高其在特定任务上的表现。Prompt tuning是使大型语言模型更加智能和高效的关键步骤之一。只有通过精心设计和优化提示文本,我们才能充分发挥大型语言模型的潜力,并使其更好地服务于人类的需求。因此,Prompt engineering,这一种新的工程能力也开始变得重要。
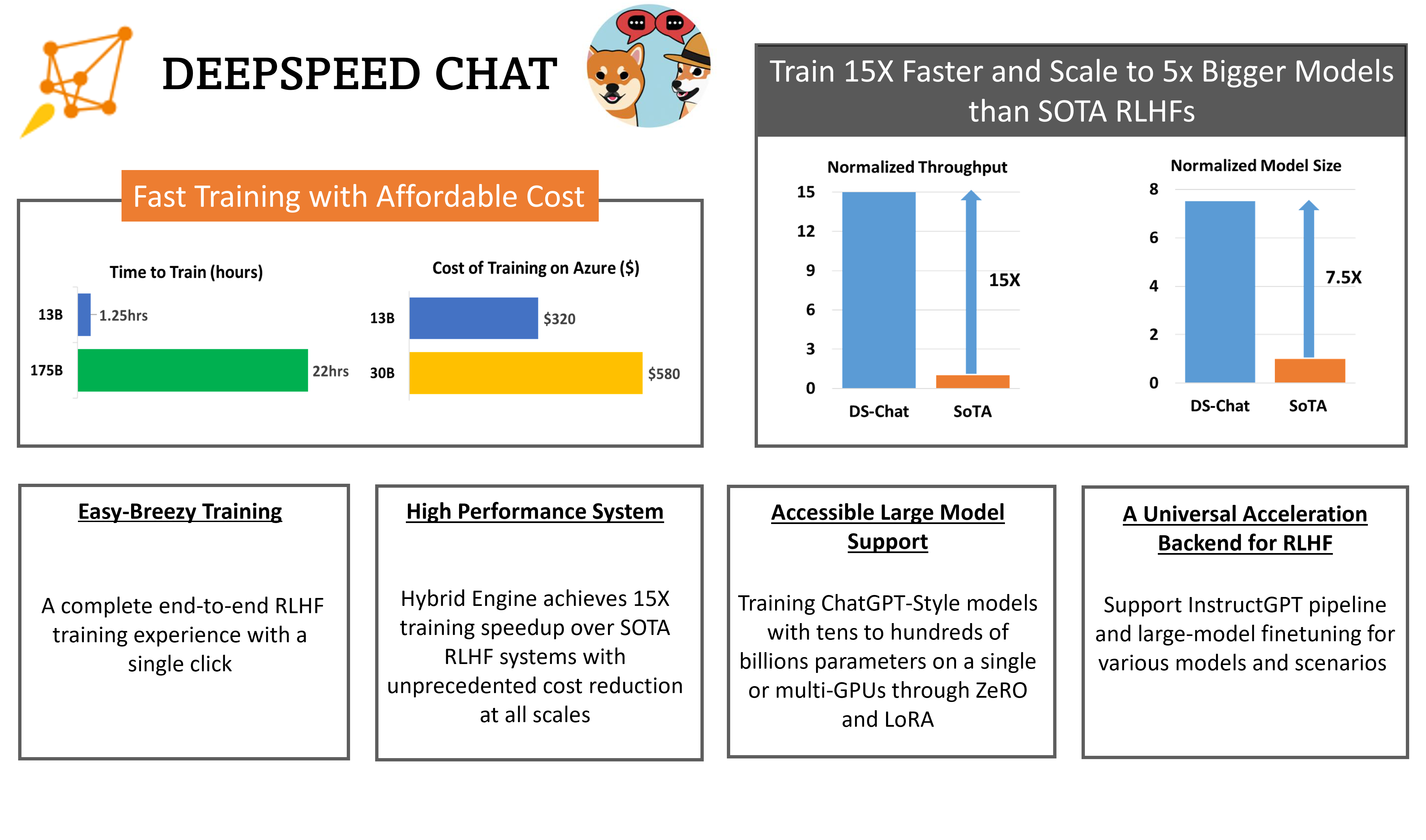
RLHF全称Reinforcement Learning from Human Feedback,是随着ChatGPT火爆之后而被大家所关注的技术。昨天,微软开源了业界第一个RLHF的pipeline框架,可以用来训练类似ChatGPT的模型。

随着预训练大模型技术的发展,基于prompt方式对模型进行微调获得模型输出已经是一种非常普遍的大模型使用方法。但是,对于同一个问题,使用不同的prompt也会获得不同的结果。为了获得更好的模型输出,对prompt进行调整,学习prompt工程技巧是一种必备的技能。
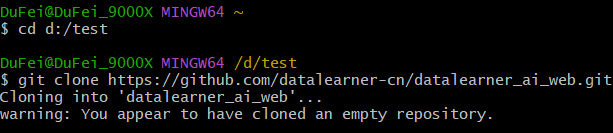
介绍如何使用git下载远程、更新远程项目到本地,提交本地更改到远程
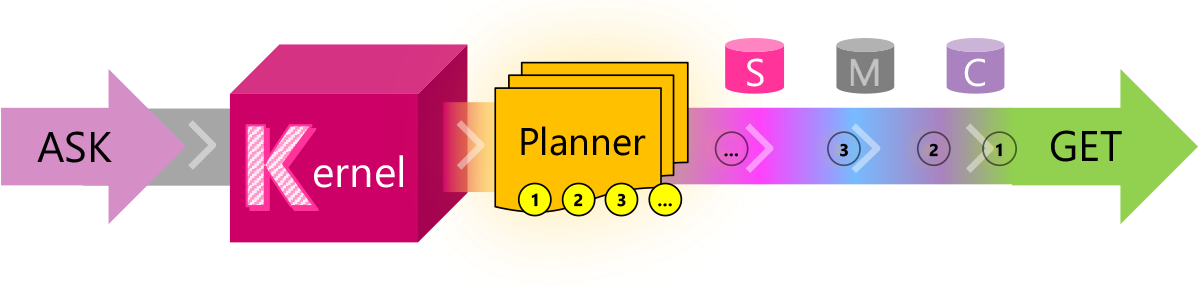
目前的LLM有很多限制,有很多问题并不能很好的解决,例如文本输入长度有限、无法记住很早之前的信息等。而这些问题目前也都缺少合适的解决方案。它们所依赖的技术:如任务规划、提示模板、向量化内存等需要的是编程的智慧。Semantic Kernel就是微软在这个背景下推出的一个结合LLM与传统编程技术的编程框架。

这是OpenAI官方的cookebook最新更新的一篇技术博客,里面说明了为什么我们需要使用embeddings-based的搜索技术来完成问答任务。
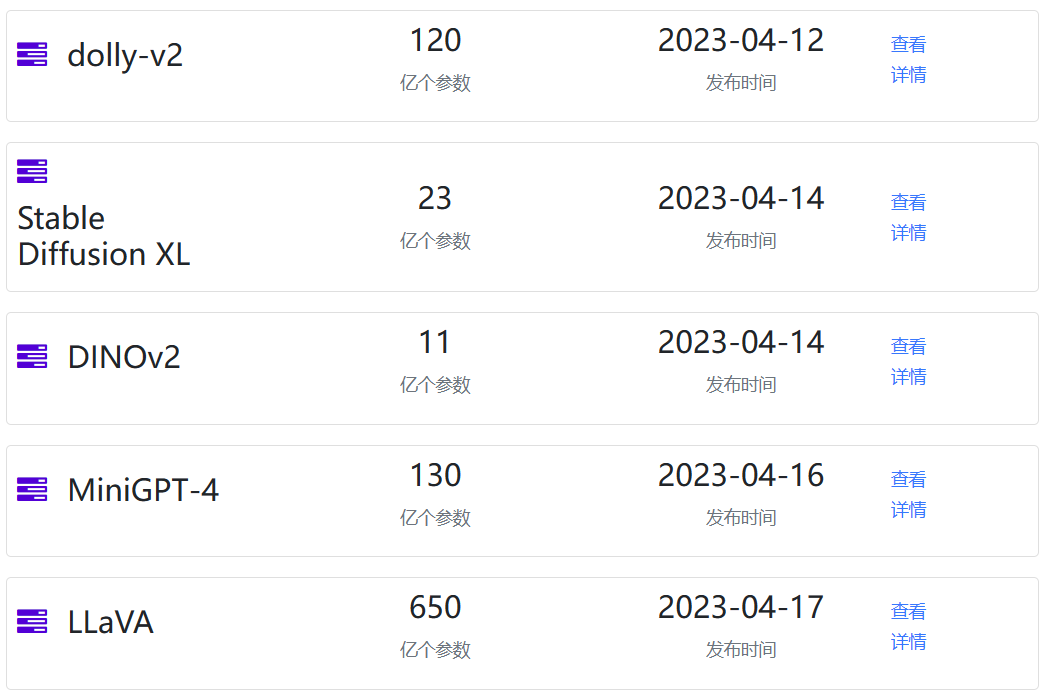
AI模型的发展速度令人惊讶,几乎每天都会有新的模型发布。而2023年4月中旬也有很多新的模型发布,我们挑出几个重点给大家介绍一下。
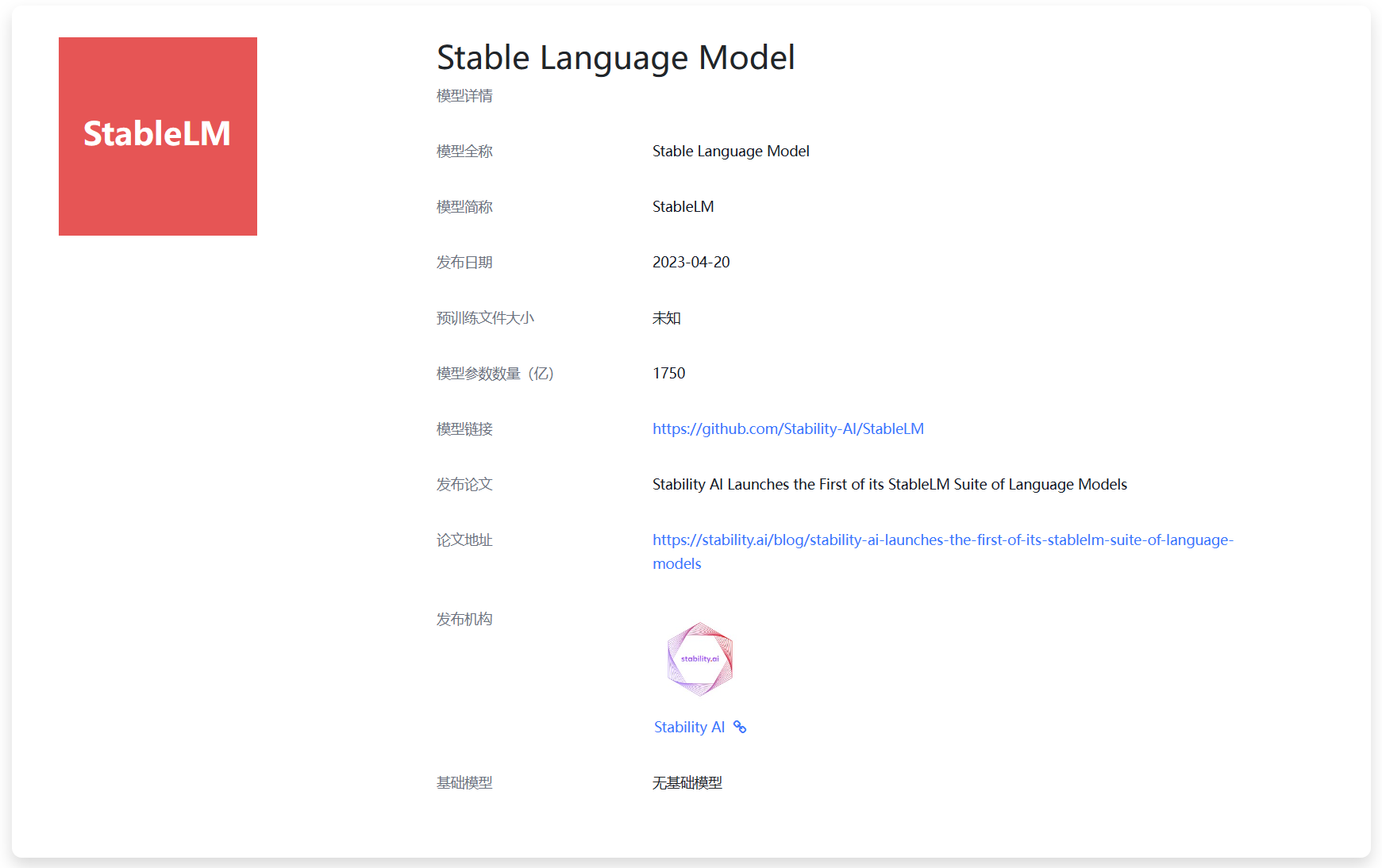
今天,Stability宣布开源StableLM计划,这是一个正在开发过程的大语言模型,但是它是开源可商用的模型。本文将对该模型做简单的介绍!

本文是Replit工程师发表的训练自己的大语言模型的过程的经验和步骤总结。Replit是一家IDE提供商,它们训练LLM的主要目的是解决编程过程的问题。Replit在训练自己的大语言模型时候使用了Databricks、Hugging Face和MosaicML等提供的技术栈。这篇文章提供的都是一线的实际经验,适合ML/AI架构师以及算法工程师学习。
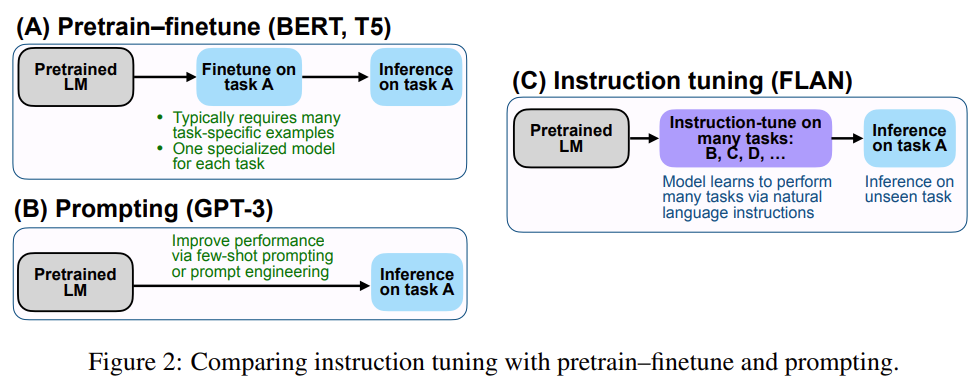
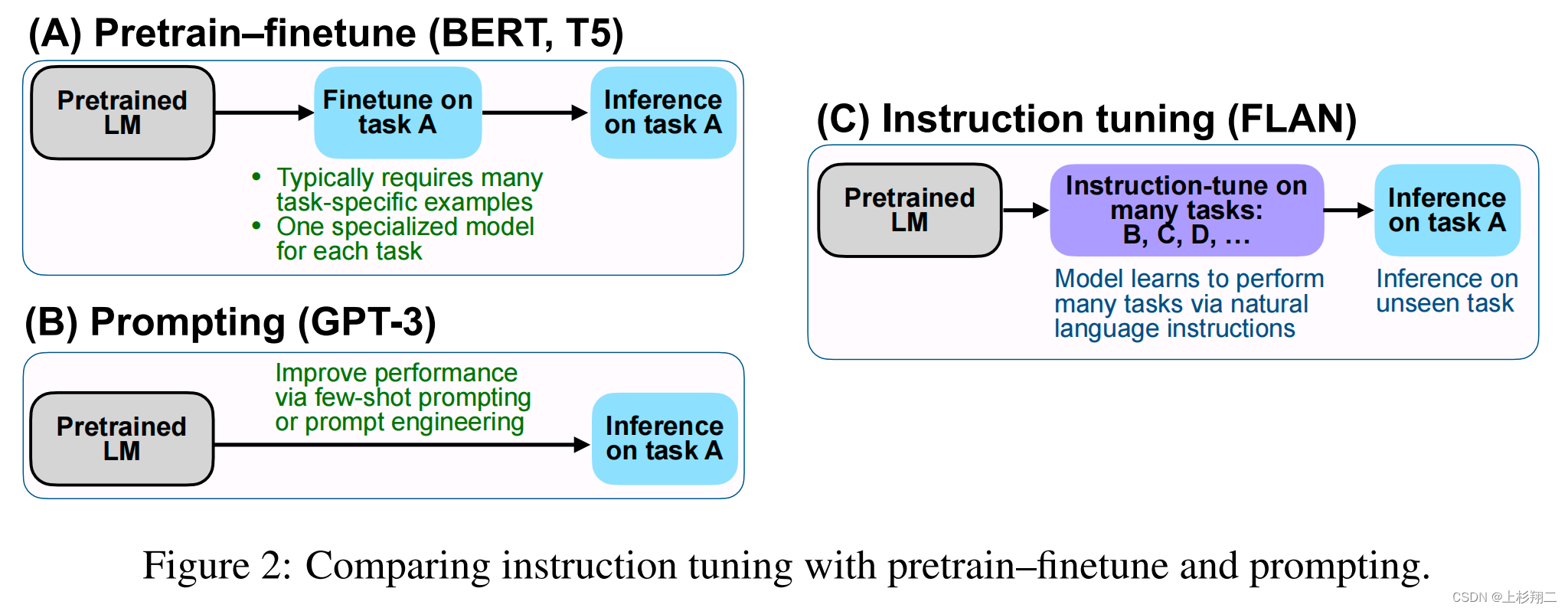
Prompt-Tuning、Instruction-Tuning和Chain-of-Thought是近几年十分流行的大模型训练技术,本文主要介绍这三种技术及其差别。
随着ChatGPT的火爆,Prompts概念开始被大家所熟知。早期类似如BERT模型的微调都是通过有监督学习的方式进行。但是随着模型越来越大,冻结大部分参数,根据下游任务做微调对模型的影响越来越小。大家开始发现,让下游任务适应预训练模型的训练结果有更好的性能。而ChatGPT的火爆让大家知道,虽然ChatGPT的能力很强,但是需要很好的提问方式才能让它为你所服务。
万众瞩目的GPT-4即将来临!3月9日晚上在德国举办的一个AI会议。微软德国的员工参与了讨论,在介绍微软云的AI能力的时候,微软德国CTO Andreas Braun透露了GPT-4将在下周发布。
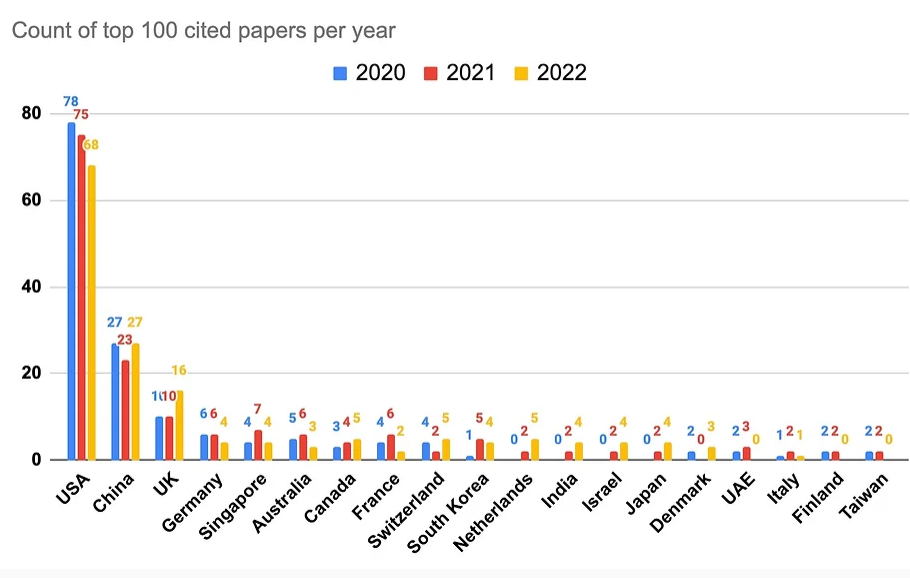
尽管AI领域在工业界发展迅速,企业研究机构在拼命的开发相关的产品以推动各自业务的发展。但是他们也在科研领域不断贡献大量的AI论文。Zeta Alpha的一篇博客分析了2022年发表的被引用最多的100篇AI论文,给大家提供一个洞察思路。
本表是Zeta Alpha收集的2022年AI领域被引次数最多的论文列表。
自从2019年OpenAI开始商业化以来,OpenAI的成果越来越封闭,而商业化的进程越来越快。GPT系列的发展正好印证了这个路径。GPT最初的版本包含了论文、代码和预训练结果。GPT-2刚开始也认为可能会造成不好的伤害而在论文官宣了大半年之后才公布了完整模型。到GPT-3的时候也就给了官方介绍博客和论文,模型则是彻底闭源且开始商业化。而今天OpenAI直接官方博客宣布GPT-3.5商业化,连论文都没有了!
近几年人工智能的发展已经让大家感受到AI算法不再是实验室的小玩具,它对社会和生活的影响已经在逐步显现。仅几年的AI模型如ChatGPT、DALL·E2、StableDiffusion等都是生成式模型,即基于无标注数据训练的可以根据输入观测数据的模型。而生成式AI平台可能是未来最重要的一种平台能力。本文是由Matt Bornstein, Guido Appenzeller, and Martin Casado等人发布的介绍当前生成式AI平台的相关企业。
最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。
今天微软宣布,新版本的Bing将全线接入ChatGPT,试图领先谷歌一步。这篇博客将总结一下带了ChatGPT的新版本Bing将有哪些新功能!
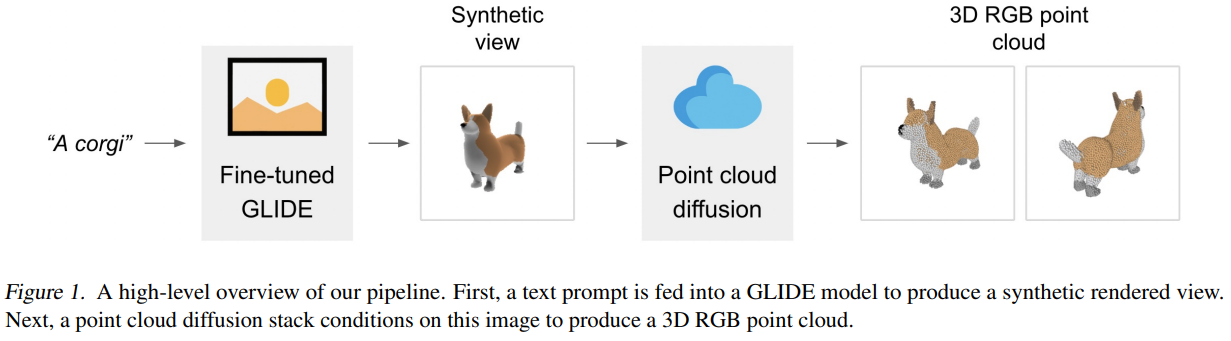
三维物体的生成(3D)其实是AR/VR领域一个非常重要的技术。但是,受限于算力和现有模型的限制,三维物体的生成相比较图像生成来说效率太低。目前,最好的图像生成模型在几秒钟就可以根据文字生成图像结果,但是3D物体的生成通常需要多个GPU小时才可以生成一个对象。为此,OpenAI在今天开源了一个速度极快的3D物体生成模型——Point-E,需要注意的是,这是今年来OpenAI罕见的源代码和预训练结果都开源的一个模型。
嵌入(Embedding)是深度学习方法处理自然语言文本最重要的方式之一。它将人类的自然语言和文本转换成一个浮点型的向量。向量之间的距离代表了它们的关系。今天,OpenAI宣布了他们的Embedding新模型——text-embedding-ada-002。官方宣称这是目前OpenAI最强的嵌入模型,可以将任意文本转换成一个向量,且效果好于目前所有OpenAI的模型。
OpenAI在其官方GitHub上公开了一个最新的开源Python库:tiktoken,这个库主要是用力做字节对编码的。相比较HuggingFace的tokenizer,其速度提升了好几倍。
字节对编码(Byte Pair Encoder,BPE),又叫digram coding,是一种在自然语言处理领域经常使用的数据压缩算法。在GPT系列模型中都有用到。主要是将数据中最常连续出现的字节(bytes)替换成数据中没有出现的字节的方法。该算法首先由Philip Gage在1994年提出。在这篇博客中我们将简单介绍一下这个方法。

Visual Studio Code简称VS Code,是由微软开发的跨平台免费开源的源代码编辑器。相比较Eclipse、PyCharm等软件,它很轻量,并不太像一个完整的IDE(Integrated Development Environment,集成开发环境)。但是,由于其轻量、快速、第三方扩展生态强大等原因,在2015年推出之后就迅速发展成为最受欢迎的开发环境。2019年的Stack Overflow的开发者调查中名列第一,使用占比月50.7%。

OpenAI是全球最著名的人工智能研究机构,发布了许多著名的人工智能技术和成果,如大语言模型GPT系列、文本生成图片预训练模型DALL·E系列、语音识别模型Whisper系列等。由于这些模型在各自领域都有相当惊艳的表现,引起了全世界广泛的关注。