
阿里开源2个全新多模态理解大模型Qwen3-VL-4B和8B:主流评测结果超Gemini 2.5 Flash Lite、GPT-5 Nano,面向多模态Agent和机器人应用打造
就在刚才,阿里云Qwen团队推出了两个多模态理解大模型Qwen3-VL-4B和Qwen3-VL-8B,本次发布的模型是较小参数规模的模型,可以用于消费级硬件(手机/PC)等,且都是稠密架构。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
就在刚才,阿里云Qwen团队推出了两个多模态理解大模型Qwen3-VL-4B和Qwen3-VL-8B,本次发布的模型是较小参数规模的模型,可以用于消费级硬件(手机/PC)等,且都是稠密架构。

为了解决大模型的Agent操作依赖交互和人工处理这个问题,普林斯顿大学与 Sierra Research 的研究团队在 2025 年 6 月提出了 τ²-Bench(Tau-Squared Benchmark),并发布了论文《τ²-Bench: Evaluating Conversational Agents in a Dual-Control Environment》。 它是对早期 τ-Bench 的扩展版本,旨在建立一种标准化方法,评估智能体在与用户共同作用于环境时的表现。

就在昨天,2025年10月7日,Google DeepMind 正式发布其最新模型——Gemini 2.5 Computer Use。该模型基于 Gemini 2.5 Pro 的视觉理解与推理能力,新增了“界面交互(UI 控制)”能力,能够在浏览器或移动端界面上像人类那样点击、输入、滚动、选择控件等操作。

Sora2 的发布再次引爆了视频生成领域。你可能已经看到过一些令人惊叹的演示视频,但当你自己上手时,生成的作品可能并不尽如人意。问题出在哪里?很可能就在你的提示词(Prompt)上。

就在今日,OpenAI正式推出了 Sora 2 ——其旗舰级视频与音频生成模型。相比2024年2月发布的初代 Sora,本次升级带来了断层级的真实感与显著增强的可控性。它不仅能更好地遵循物理规律生成视频,还首次实现了同步对话与环境音效的生成,并通过全新 iOS 应用“Sora”开放给公众使用。

就在刚才,Anthropic 正式推出了 Claude Sonnet 4.5——全球最强的编码模型。这款新模型不仅在软件开发能力上实现了断层领先,更在构建复杂 AI 代理、计算机操控以及数学推理等多个维度展现出革命性突破。

智谱AI于2025年7月发布了Zread。这款产品能够利用其大模型能力,结合类似Deep Research的Agent技术,对GitHub项目进行深度解读和问答。其价值在于将强大的模型能力通过优秀的工程化设计,变成了一个真正“好用”的工具。它解决的正是那种“代码就在那里,但我就是看不懂”的尴尬,这种体验是单纯聊天机器人无法替代的。

今日,QwenTeam 正式发布了全新一代多模态视觉语言模型 —— Qwen3-VL 系列。这是 Qwen 家族迄今为止最强大的视觉语言模型,在视觉感知、跨模态推理、长上下文理解、空间推理和智能代理交互等多个维度全面提升。旗舰开源模型 Qwen3-VL-235B-A22B 已经上线,并提供 Instruct 和 Thinking 两个版本,前者在视觉感知上全面对标并超过 Gemini 2.5 Pro,后者则在多模态推理基准上创下新纪录,成为开源阵营的最强视觉理解大模型。

几个小时前,阿里一次更新了3个大模型,分别是开源的全模态大模型Qwen3-Omni、开源的图像编辑大模型Qwen3-Image-Edit和不开源的语音识别大模型Qwen3-TTS。本次发布的3个模型均为多模态大模型,可以说阿里的大模型真的是全面开花,节奏很快!

xAI 正式发布 Grok 4 Fast —— 一款以 极致性价比与前沿性能 为核心卖点的新一代推理模型。相比前代产品,它不仅在推理准确率上几乎与旗舰模型Grok 4等持平,还凭借 40%更高的推理效率 和 高达98%的成本降低,将高质量智能推理真正带入大众用户和企业应用场景。

继阿里刚发布Qwen3-ASR模型之后,Qwen团队又在社区提交了全新的Qwen3-Next代码。这意味着阿里即将开源Qwen3家族的新成员。这个模型最大的特点是架构变化很大,与此前Qwen系列很不一样。

阿里发布了全新的语音识别大模型Qwen3-ASR-Flash,该模型是Qwen3系列模型中首个语音识别大模型,中英文语音识别错误率低于GPT-4o-transcribe和Gemini 2.5 Pro。不过,该模型目前仅通过API提供,不开源!
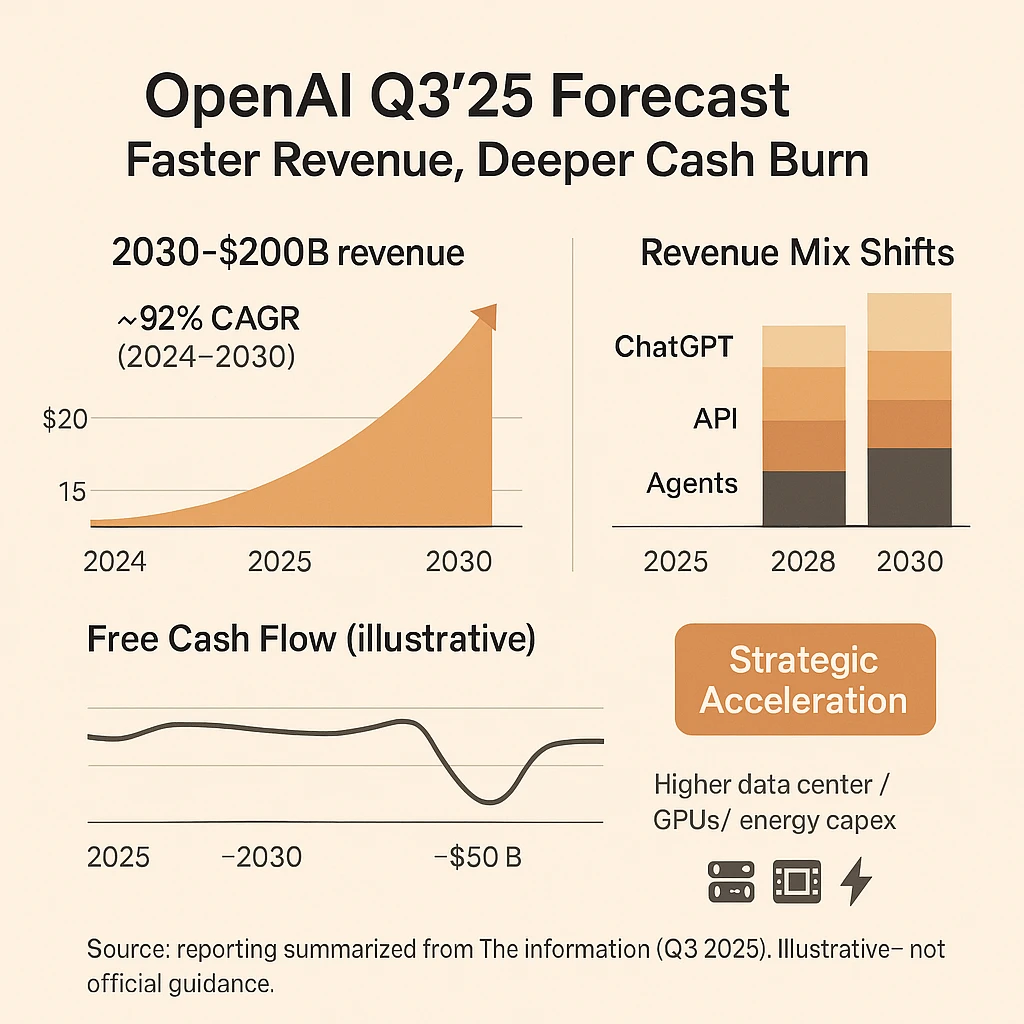
根据TheInformaiton的披露,近期OpenAI更新了他们最新财务预测(截至2025年第三季度)。这份收入预测展示了当前OpenAI的收入情况,并描绘了一幅引人注目的未来图景。与2025年第一季度OpenAI自己的预测相比,新数据不仅上调了收入预期,也揭示了公司因基础设施投入而面临的巨大现金消耗压力。本文将简单解读一下这份数据,包括OpenAI的收入情况,不同产品占比,如ChatGPT的比重等。
EmbeddingGemma 是基于 Gemma 3 架构打造的全新开源多语言向量模型,专为移动端/本地离线应用而生。它以约 308M 参数的紧凑体量,在 RAG、语义搜索、分类、聚类等任务上提供高质量表征,同时将隐私与可用性拉满:无需联网即可在本地生成向量。

今日,Moonshot AI正式发布了最新旗舰模型 Kimi K2-Instruct-0905。这是一款基于混合专家架构(MoE)的前沿大语言模型,总参数规模达到 1万亿,激活参数为 320亿,不仅在编码智能上实现了断层式提升,更凭借 256K超长上下文 成为当前同类产品中的佼佼者。官方称其在公共基准和真实智能体任务上的表现均有显著突破,已对标并超越部分国际顶尖模型。

尽管人工智能语言模型的能力日益强大,但它们依然面临一个棘手的问题:“幻觉”(Hallucination)。所谓幻觉,指的是模型自信地生成一个事实上错误的答案。OpenAI 的最新研究论文指出,这一现象的根源在于标准的训练和评估方式实际上在鼓励模型“猜测”而非“承认不确定性”。

就在几个小时前,OpenAI 发布了全新的 GPT Realtime 大模型。这是一个 Speech-to-Speech(S2S)模型,能通过单个模型与 API完成从音频输入到音频输出的全流程,显著降低交互延迟并充分保留语音细节。 GPT Realtime 以“端到端语音理解—推理—合成”为核心路径,解决了传统“识别—推理—合成”多阶段带来的延迟与风格割裂问题。

就在刚才,Google宣布发布最新的图像生成和编辑大模型Gemini 2.5 Flash Image Preview。该模型就是最近火爆网络的Nana Banana背后真正的模型。该模型在图片生成和编辑方面目前是断层领先,效果非常好。

近年来,AI 编码助手与 Agent 框架层出不穷,从 Github Copilot 到 Cursor,再到各种基于 LangChain 的多代理方案。然而,真正让开发者普遍感受到“顺手”与“愉快”的,却是 Claude Code(简称 CC)。它的特别之处,并不在于引入了复杂的新架构,而恰恰在于其极简而精心打磨的设计选择。 Claude模型本身的强大毋庸置疑,但是即使是相同的模型,Claude Code体验也比其它的Agent似乎体验更好。本文基于2025年8月21日vivek公开发布的一篇英文博客,

最近,一个代号 “Nano Banana” 的神秘图像生成与编辑大模型突然在社交网络上掀起风暴。与之前所有模型截然不同,它似乎拥有「记忆面孔」的魔法:无论角度、光影如何变化,人物的面容始终一致;它还能读懂照片里的故事,精准捕捉场景氛围,并服从多步骤、高复杂度的指令。然而,它像幽灵一样没有身世——没有官方文档,没有作者署名,甚至没有一行技术白皮书。极致的神秘感与惊人的效果形成巨大反差,像磁铁般吸住了整个社区的目光:它究竟出自谁手?能力边界到底在哪儿? 本文会介绍一下这个模型当前已知的信息,以及如何使用。

就在几个小时前,DeepSeekAI宣布官方的聊天模型从DeepSeek-V3升级到了DeepSeek-V3.1,上下文拓展至128K。虽然,官方目前没有给出这个模型的详细信息,DataLearnerAI已经搜集到很多信息供大家参考。
Aider 是一个在终端里进行结对编程的开源工具。为评估不同大模型在“按照指令对代码进行实际可落地的编辑”上的能力,Aider 提出并维护了公开基准与排行榜,用于比较模型在无人工干预下完成代码修改任务的可靠性与成功率。该评测已被多家模型提供方在技术说明中引用,用作代码编辑与指令遵循能力的对照指标。

GPT-5 在指令遵循和推理能力上比前代更强,但也因此更“敏感”:如果规则里有冲突或表述过度强硬,模型往往会卡壳或输出异常。为此,OpenAI 发布了面向开发者的 《GPT-5 for Coding》技巧小抄,其中总结了使用 GPT-5 进行编程与代码生成时最实用的六条经验。这些技巧与普通的“写作提示工程”不同,它们专门针对软件开发场景:如何写规则、怎样控制推理强度、如何避免模型“想太多”,以及怎样利用 GPT-5 的新特性把它真正驯化成可靠的结对编程伙伴。本文对这六条技巧逐条进行解释总结。
谷歌开源了其Gemma 3模型系列的新成员——Gemma 3 270M。该模型的设计理念并非追求通用性和大规模,而是专注于为定义明确的特定任务提供一个高效、紧凑的解决方案。其核心价值在于通过微调(fine-tuning)来执行专门化任务。