
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~





在Java中,自增是一种非常常见的操作,在自增中,有两种写法,一种是前缀自增(++i),一种是后缀自增(i++)。这里主要简单介绍两种自增的差别。
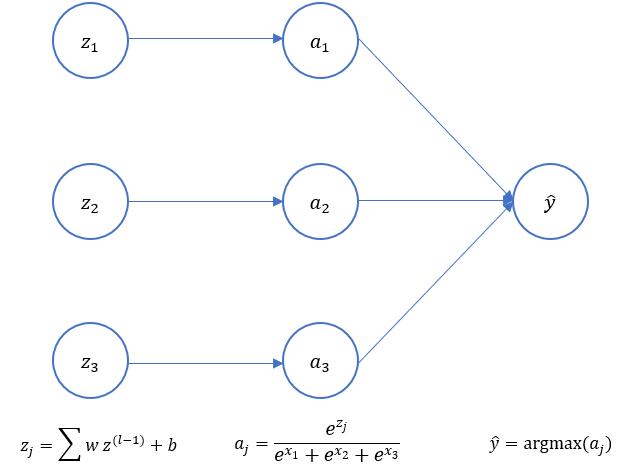
softmax作为多标签分类中最常用的激活函数,常常作为最后一层存在,并经常和交叉熵损失函数一起搭配使用。这里描述如何推导交叉熵损失函数的推导问题。
Batch Normalization是深度学习中最重要的技巧之一。是由Sergey Ioffe和Christian Szeged创建的。Batch Normalization使超参数的搜索更加快速便捷,也使得神经网络鲁棒性更好。本篇博客将简要介绍相关概念和原理。
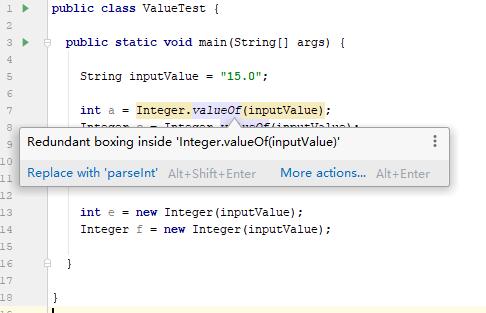
在Java的类型转换中,我们经常会使用valueOf或者parseInt(parseFloat/parseDouble等)来转换。这二者有什么区别呢?这里简要介绍一下。

随着深度学习的火热,对计算机算力的要求越来越高。从2012年AlexNet以来,人们越来越多开始使用GPU加速深度学习的计算。 然而,一些传统的机器学习方法对GPU的利用却很少,这浪费了很多的资源和探索的可能。在这里,我们介绍一个非常优秀的项目——RAPIDS,这是一个致力于将GPU加速带给传统算法的项目,并且提供了与Pandas和scikit-learn一致的用法和体验,非常值得大家尝试。

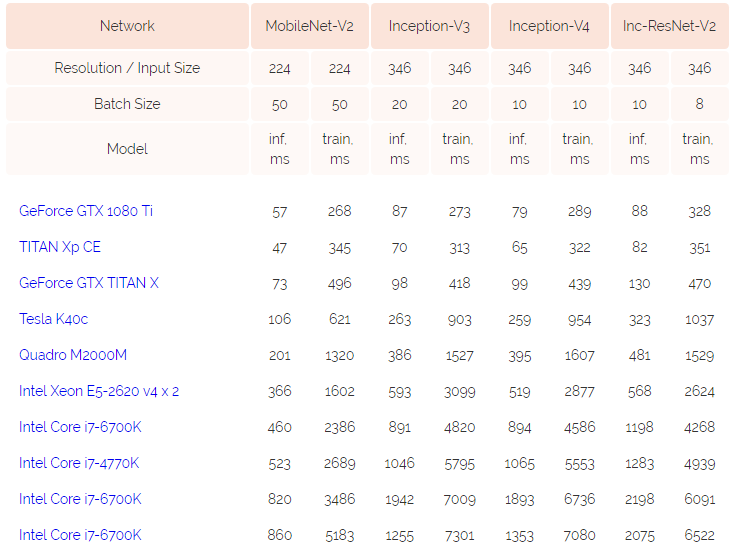
在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,可以提高模型效果。
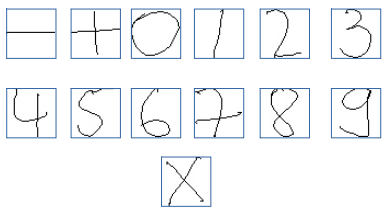
本文是发在Medium上的一篇博客:《Handwritten Equation Solver using Convolutional Neural Network》。本文是原文的翻译。这篇文章主要教大家如何使用keras训练手写字符的识别,并保存训练好的模型到本地,以及未来如何调用保存到模型来预测。

Tensorflow中tf.data.Dataset是最常用的数据集类,我们也使用这个类做转换数据、迭代数据等操作。本篇博客将简要描述这个类的使用方法。
今日推荐
Anthropic发布Claude3.5-Sonnet模型,超过Claude3系列所有模型的能力,并且支持多模态!
xAI发布Grok Imagine功能,一条文本命令即可生成图片和最长达15秒的视频,也可以基于现有照片生成视频,免费用户也可以使用~
微软发布第四代Phi系列大模型,140亿参数的Phi-4 14B模型数学推理方面评测结果超过GPT 4o,复杂推理能力大幅增强
2022年9月份最火的10个AI研究——基于GitHub的Star数量排序
吴恩达再开新课程!如何基于大语言模型实现更强大的语义搜索课程!
阿里巴巴开源国内最大参数规模大语言模型——高达720亿参数规模的Qwen-72B发布!还有一个可以在手机上运行的18亿参数的Qwen-1.8B
Kimi K2为什么开源?基于Kimi团队成员内容解释Kimi K2模型背后的决策思路与技术细节:继承于DeepSeek V3架构,只为追求模型智能的上限
检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结
Google开源多模态大模型Gemma3n的正式版:重新定义端侧AI的多模态能力,10B(100亿)参数以下最强多模态大模型,一个月前的预览版正式转正