
Sequence-to-Sequence model
Sequence-to-Sequence model
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Sequence-to-Sequence model
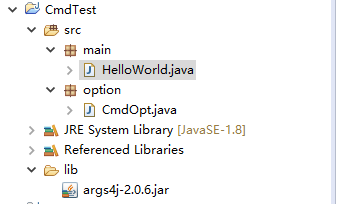
使用eclipse打包java工程并导出java包
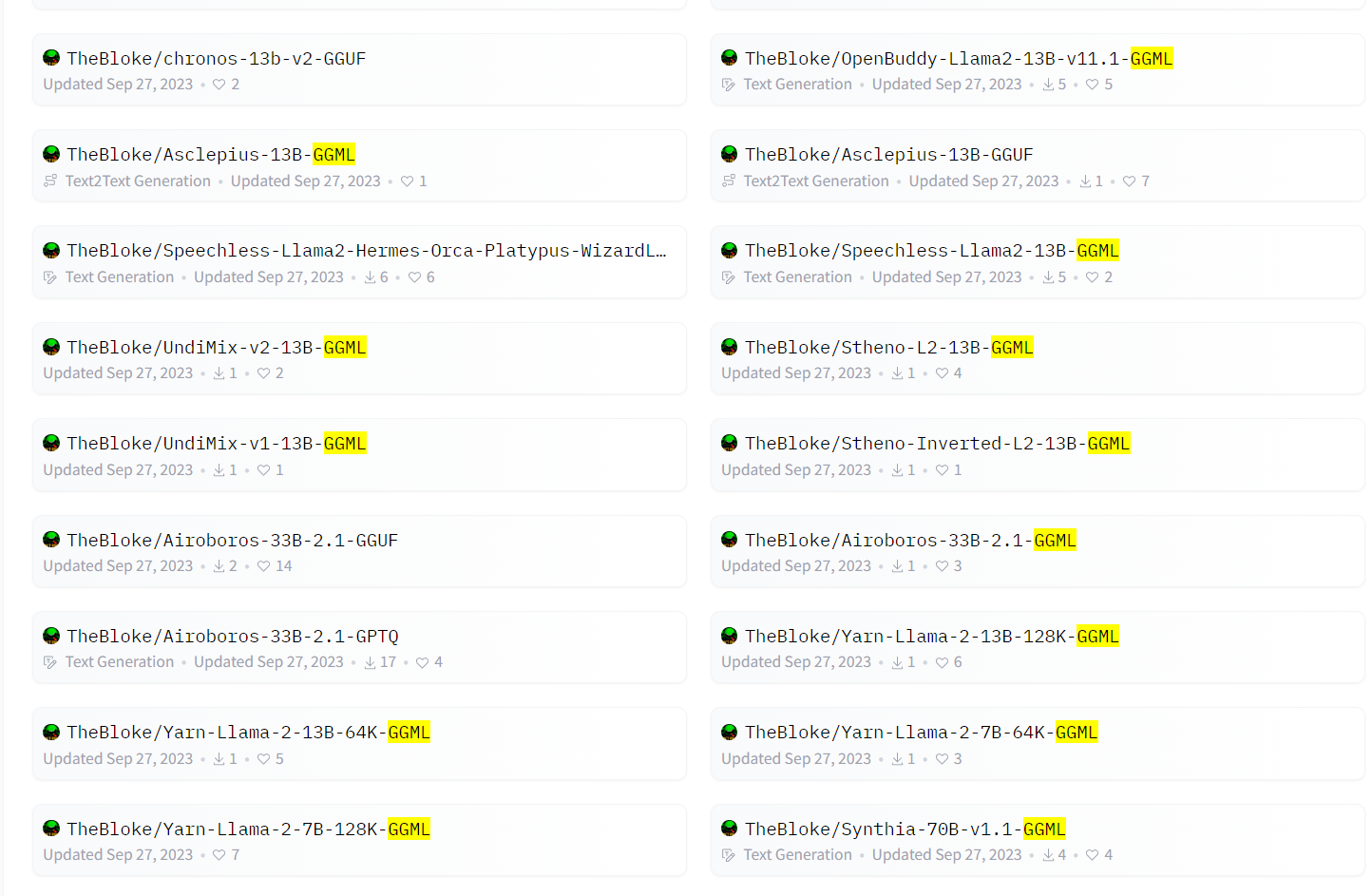
GGML是在大模型领域常见的一种文件格式。HuggingFace上著名的开发者Tom Jobbins经常发布带有GGML名称字样的大模型。通常是模型名+GGML后缀,那么这个名字的模型是什么?GGML格式的文件名的大模型是什么样的大模型格式?如何使用?本文将简单介绍。
Dask的集群启动创建也很简单,有好几种方式,最简单的是采用官方提供dask-scheduler和dask-worker命令行方式。本文描述如何使用命令行方法建立Dask集群。
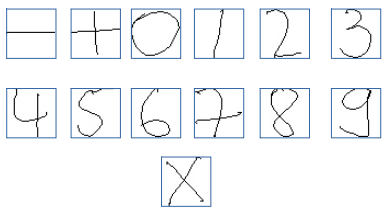
本文是发在Medium上的一篇博客:《Handwritten Equation Solver using Convolutional Neural Network》。本文是原文的翻译。这篇文章主要教大家如何使用keras训练手写字符的识别,并保存训练好的模型到本地,以及未来如何调用保存到模型来预测。

网络爬虫中Json数据的解析
昨天,吴恩达宣布与OpenAI联合推出了一个新的面向开发者的ChatGPT的Prompt课程。课程主要教授大家如何使用Prompt做ChatGPT的应用开发、使用ChatGPT的新方法、建立自己的个性化的Chatbot,以及最重要的,基于OpenAI的API来练习Prompt工程技巧!

OpenAI最新发布了GPT-3.5-Turbo-Instruct,这是一款强大的指令遵循大模型。尽管官方没有发布官方博客介绍,但我们将在本文中详细探讨这一模型的特点以及其在人工智能领域的价值。
美国有一家上市企业,叫做Roblox,号称是元宇宙龙头企业,被市场炒的火热。这家企业到底是什么样的业务,可以被认为是一家纯正的元宇宙企业。本文根据我收集的资料,为大家介绍一下。
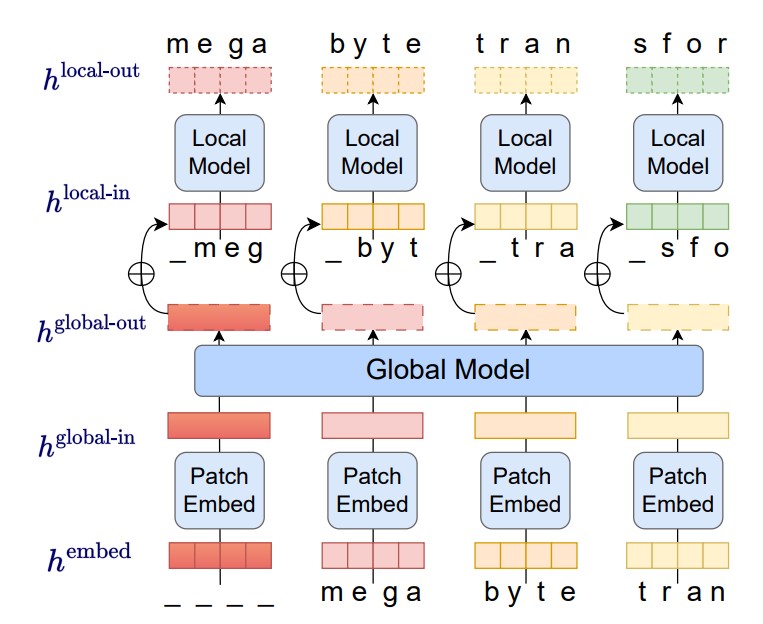
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!

NVIDIA在2024年GPU技术大会(NVIDIA GPU Technology Conference,GTC)发布了全新的算力芯片和服务,即基于最新的Blackwell架构的算力芯片B200和GB200服务器。但是,大多数人对于NVIDIA芯片的升级只有数字的变化,本文将针对NVIDIA的GPU算力芯片做简单的介绍,并说明NVIDIA B200以及GB200的升级的地方。
Embedding模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多LLM应用必不可少的部分。但是,现实中开源的Emebdding模型却很少。最近,北京智源人工智能研究院(BAAI)开源了BGE系列Embedding模型,不仅在MTEB排行榜中登顶冠军,还是免费商用授权的大模型,支持中文,应该可以满足相当多人的需要。
在前面的博客中,我们已经对`Dask`做了一点简单的介绍了,在这篇博客中我们来对比一下`Dask`的`DataFrame`在不同条件下的运算性能,主要是连接操作的性能(merge)。

在编程的世界中,有不同层次的语言(language),这些语言有时候也称代码(code)。本文将简单介绍编程语言(Programming Language)、汇编语言(Assembly Language, ASM)、机器语言(Machine Language/Code)的区别。

AI Agent被很多人认为是未来大模型的发展方向。此前,OpenAI安全团队负责人人Lilian Weng也发布了一篇详细介绍AI自动代理机器人的博客,引起了很多人的关注。7月份发布的MetaGPT是一个全新的AI Agent项目,它基于GPT-4提供了专注于软件开发的自动代理框架,几乎可以理解为配备了产品经历、系统设计师、程序员的一个小团队,可以基于原始的需求直接生成最后的代码项目。本文主要介绍一下这个项目,并分析一下背后的实现方式。

大语言模型(Large Language Model,LLM)已经在很多领域都产生了巨大的影响。但是其中最为大家所期待的功能之一就是基于idea生成PPT、Word文档等。此前微软Office Copilot已经吸引了很多人的关注,但目前依然没有开放。而今天DataLearnerAI发现了一个类似的产品,来自洛杉矶初创企业Gamma的产品目前已经支持基于文本生成PPT、Word和网页应用了,本文带大家简单体验一下这个产品。

Qwen系列是阿里巴巴开源的一系列大语言模型。在此前的开源中,阿里巴巴共开源了3个系列的大模型,分别是70亿参数规模和140亿参数规模的Qwen-7B和Qwen-14B,还有一个是多模态大模型Qwen-VL。而此次阿里巴巴开源了720亿参数规模的Qwen-72b,是目前国内最大参数规模的开源大语言模型,应该也是全球范围内首次有和Llama2-70b同等规模的大语言模型开源。
机器学习是实现人工智能最重要的方法之一,包括深度学习等都属于机器学习中的一种方法。因此,机器学习的应用被认为是实现人工智能应用的重要途径。人工智能的应用目标是使用计算机(机器)来代替或者辅助人工来完成某项任务。机器学习在解决业务问题的应用需要谨慎考虑。本文提供一些步骤可以参考。
123123

今天,OpenAI官方宣布GPT接口新增一个能力:即支持以更加精确的JSON视图格式返回大模型的结果。比去年的单纯的让GPT输出JSON更加强大,它可以确保模型生成的输出能够完全匹配开发者提供的JSON模式。这种能力是在官方的API接口中增加了`return_format={"type":"json_schema","json_schema": {...}}`参数实现的。但是仅支持最新的模型版本,但这可能是未来的趋势!
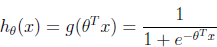
监督学习中的分类问题和Logistic回归常常被用于推荐问题中关于BPR的研究,但是为什么一定要用Logistic函数来建模和优化呢?本篇博客将带你揭晓奥秘~
Hadoop(一)-HDFS