
大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处!
大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。

大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~
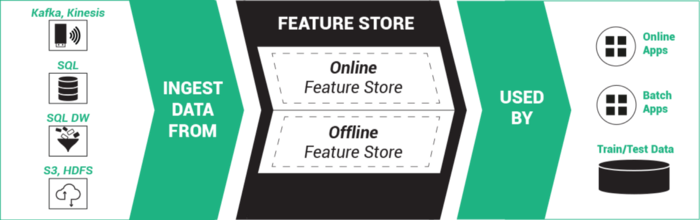
在2020年的亚马逊reInvent发布会上,亚马逊正式发布了一项新的服务,即Amazon SageMaker Feature Store,中文简介是适用于机器学习特征的完全托管的存储库。 Feature Store是这两年兴起的另一个关于人工智能系统的基础设施,应该也是未来几年最重要的人工智能基础设施之一。本文将介绍一下Feature Store是什么以及为什么很多企业开始推广这个东西。
R的数据库连接、操作
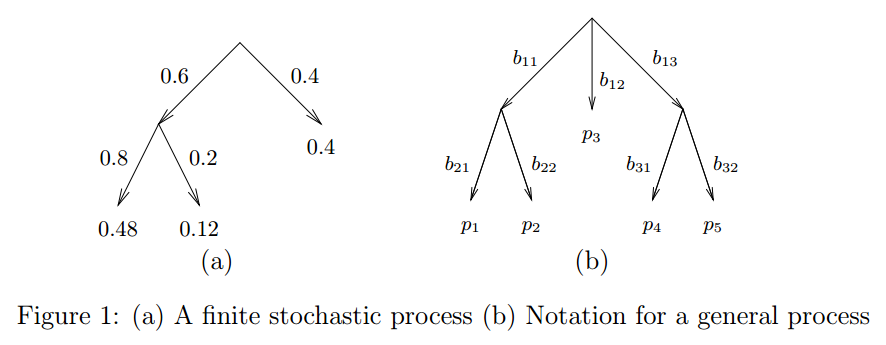
狄利克雷分布作为多项式分布的先验大家应该比较熟悉了。这里介绍另外一种Dirichlet树结构的分布,也可以作为多项式分布的先验,但却更加灵活

TF-IDF的java实现(权重排序显示)

OpenAI在2023年8月份发布了GPT-3.5的微调接口,并表示会在2023年秋天开放16K的gpt-3.5-turbo-16k模型和GPT-4的微调(参考:[重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口](https://www.datalearner.com/blog/1051692752268726 "重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口"))。然而,微调并不是一个简单的问题,如何对大模型微调以及如果微调出现问题

关注深度学习或者NLP的童鞋应该都知道openAI的GPT-3模型,这是一个非常厉害的模型,在很多任务上都取得了极其出色的成绩。然而,OpenAI的有限开放政策让这个模型的应用被限定在很窄的范围内。甚至由于大陆不在OpenAI的API开放国家,大家几乎都无法使用和体验。而五一假期期间,FaceBook的研究人员Susan Zhang等人发布了一个开源的大预言模型,其参数规模1750亿,与GPT-3几乎一样。

交叉验证是一种用于估计机器学习模型性能的统计方法。它是一种评估统计分析结果如何推广到独立数据集的方法。简单来说,就是将数据集分成不同的部分,然后某些部分训练,某些部分测试,某些部分验证,这样可以最大程度避免过拟合以及测试模型在陌生数据集的性能。

GLM4是智谱AI发布的第四代基座大语言模型,全称General Language Model,最早由清华大学KEG小组再2021年发布。这个基座模型也是著名的开源国产大模型ChatGLM系列的基座模型。本次发布的第四代GLM4的能力相比此前的基座模型提升了60%,已经与世界最强模型Gemini Ultra和GPT-4接近!
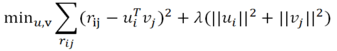
推荐中,有研究explict feedback,有研究implict feedback,今天就来谈谈这两种基本模型是怎么建的?其实,都是套路~
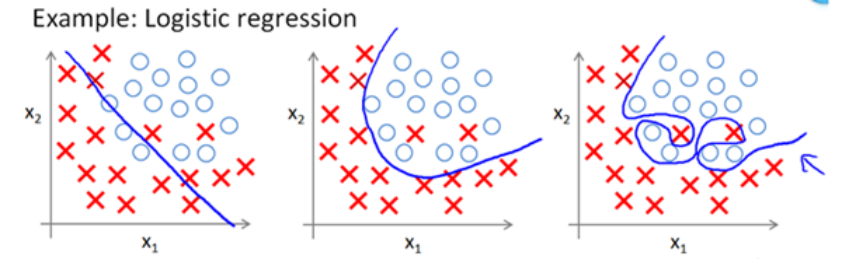
在我们给推荐问题建模时,神秘的正则化项L0、L1、L2的选择对模型很重要。为什么要加正则化?正则化有哪几种形式?到底该选择哪种正则化来建模呢?正则化项与推荐问题的关系?

SCI期刊可能是国内科研活动中与期刊最相关的话题内容。类似的,包括SCIE、SSCI和EI期刊也是常见的话题。本文将对这几个名词进行解释,并着重说明SCIE是否属于SCI、以及SCI和EI、SSCI的区别。
运行本地dask集群的时候出错Task exception was never retrieved的解决方法
如何使用python绘制简单的散点图
中文停用词表和英文停用词表
使用Eclipse进行Web系统开发是一种非常流行的方式。本文将讲述如何从零开始搭建Eclipse的Web开发环境。
在自然语言数据预处理阶段,为了提取更有用的信息,对数据必须进行相应处理。本文重点介绍对于高频词与低频词的处理。
在Android开发中,我们经常会遇到很多问题,这里记录了一些常见的问题及其解决方法
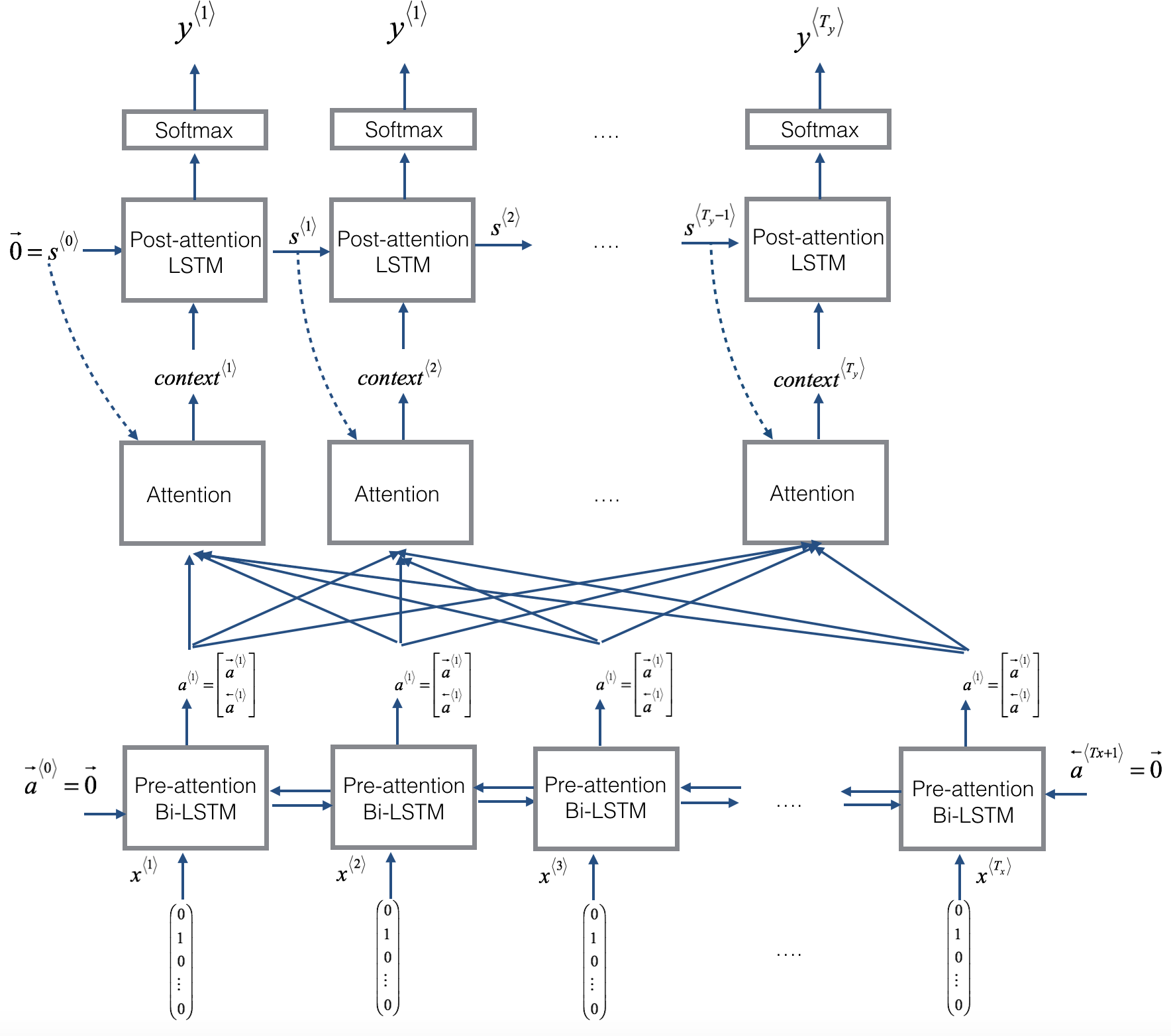
Encoder-Decoder的深度学习架构是目前非常流行的神经网络架构,在许多的任务上都取得了很好的成绩。在之前的博客中,我们也详细介绍了该架构(参见深度学习之Encoder-Decoder架构)。本篇博客将详细讲述Attention机制。

大语言模型中一个非常重要的内容就是关于代码的支持。通常,基于代码数据训练的模型不仅在代码补全方面有着更好地支持,也可能是大语言模型逻辑能力的部分来源。本文将总结目前业界专门针对代码补全(生成)方面而做的8个大模型。
Scrapy网络爬虫实战[保存为Json文件及存储到mysql数据库]
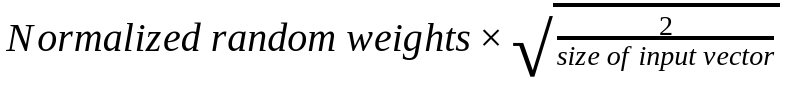
深度学习的初始化非常重要,这篇博客主要描述两种初始化方法:一个是Kaiming初始化,一个是LSUV方法。文中对比了不同初始化的效果,并将每一种初始化得到的激活函数的输出都展示出来以查看每种初始化对层的输出的影响。当然,作者最后也发现如果使用了BatchNorm的话,不同的初始化方法结果差不多。说明使用BN可以使得初始化不那么敏感了。
ChatGLM-6B是国产开源大模型领域最强大的的大语言模型。因其优秀的效果和较低的资源占用在国内引起了很多的关注。2023年6月25日,清华大学KEG和数据挖掘小组(THUDM)发布了第二代ChatGLM2-6B。