
检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结
检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。
强化学习(Reinforcement Learning)是近年来十分火热的一种机器学习研究领域。随着DeepMind(谷歌旗下的研究机构)的AlphaGo在围棋界战胜人类之后,这类方法开始被人们广泛关注。但是,强化学习并不是突然出现,也不是DeepMind的首创,在很久之前,这种方法已经开始发展,但是近年来,随着AI相关的软硬件能力的提升,强化学习的实用价值也开始显现。本文不涉及强化学习本身的技术细节,仅仅记录这种方法的历史由来。

使用idea打包jar文件的方法

有的时候使用Python遇到内存溢出的问题,但其实机器剩余内存很多。需要注意Python版本是否正确

在大语言模型的训练和应用中,计算精度是一个非常重要的概念,本文将详细解释关于大语言模型中FP32、FP16等精度概念,并说明为什么大语言模型的训练通常使用FP32精度。

NumPy是Python中非常优秀的一个数据科学工具包,使用Python做数据分析的童鞋几乎是必备的工具。NumPy的提供了非常丰富的计算能力,但是底层是C语言实现的,因此既有Python语法的低门槛,速度上却依然非常好。NumPy本身也和Pandas、SciPy一起成为一种生态了。今天,NumPy发布了1.20.0最新版本,这个版本的改动很大。值得童鞋们关注~
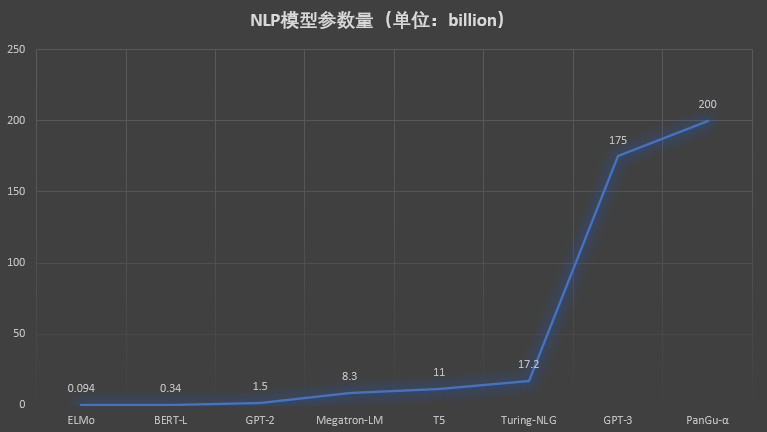
这几年深度学习的发展给人工智能相关应用的落地带来了很大的促进。随着NLP、CV相关领域的算法的发展,算法层面的创新已经逐渐慢了下来,但是工程方面的研究依然非常火热。从底层的硬件的创新,到平台框架的发展,为支撑超大规模模型训练与移动端小规模算法推断而创造的软硬件体系也在飞速革新。本文将总结深度学习平台框架软件及下层的硬件支撑系统。

反向传播算法是深度学习求解最重要的方法。这里我们手动推导一下。

随着预训练大模型技术的发展,基于prompt方式对模型进行微调获得模型输出已经是一种非常普遍的大模型使用方法。但是,对于同一个问题,使用不同的prompt也会获得不同的结果。为了获得更好的模型输出,对prompt进行调整,学习prompt工程技巧是一种必备的技能。
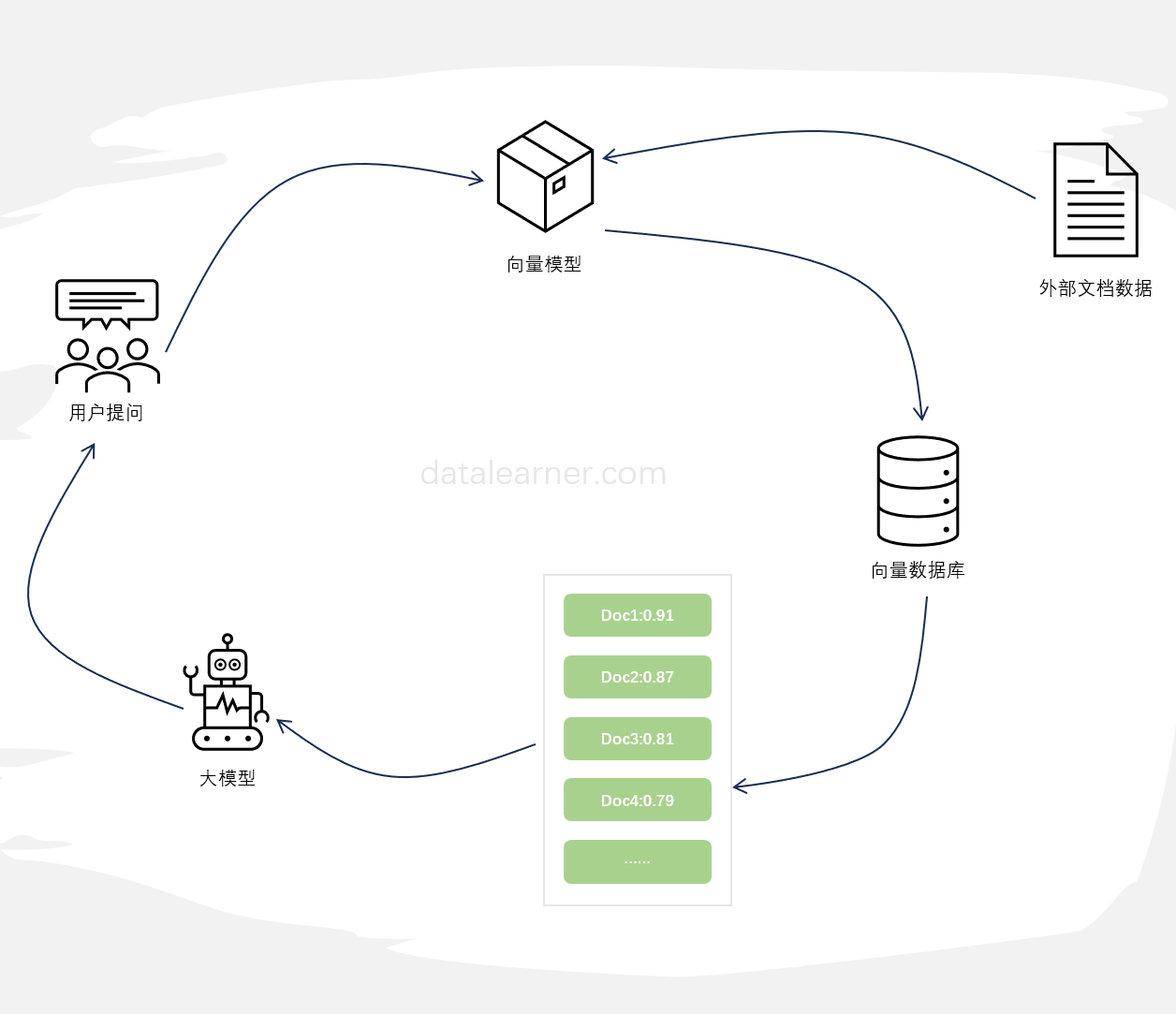
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。
如何更改国内源,提升下载速度,以及只为当前用户安装指定包
linux环境下使用中文分词工具
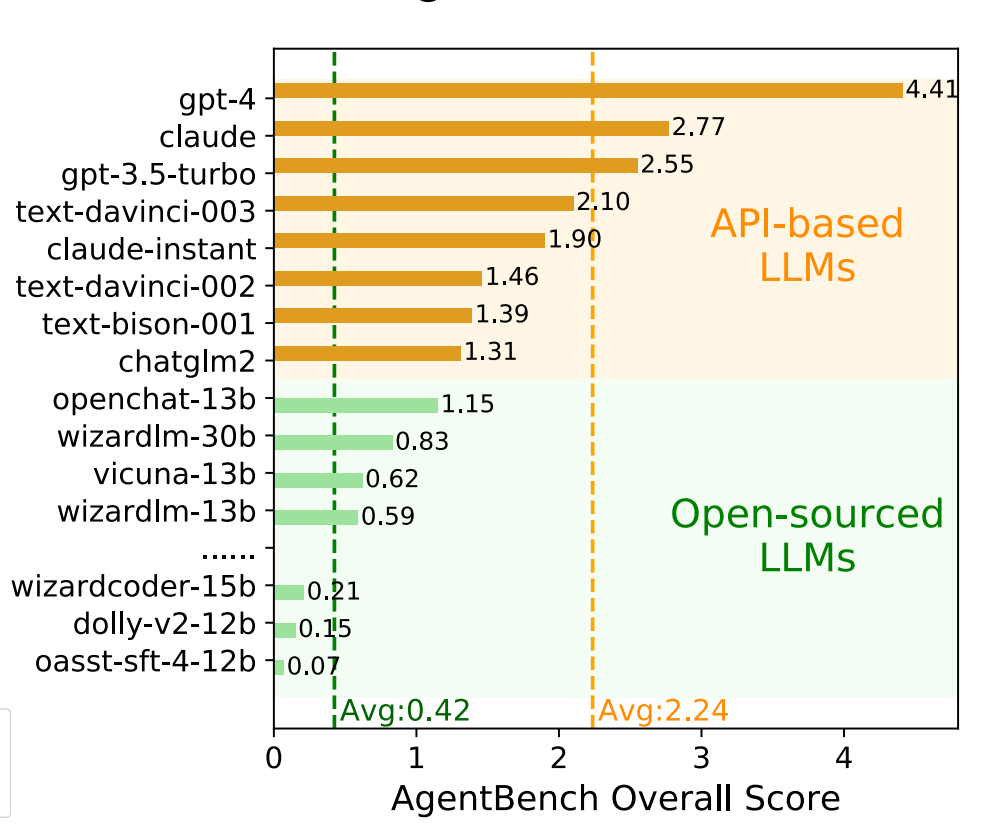
所谓AI Agent就是一个以LLM为核心控制器的一个代理系统。业界开源的项目如AutoGPT、GPT-Engineer和BabyAGI等,都是类似的例子。然而,并不是所有的AI Agent都有很好的表现,其核心还是取决于LLM的水平。尽管LLM已经在许多NLP任务上取得进步,但它们作为代理完成实际任务的能力缺乏系统的评估。清华大学KEG与数据挖掘小组(就是发布ChatGLM模型)发布了一个最新大模型AI Agent能力评测数据集,对当前大模型作为AI Agent的能力做了综合测评,结果十分有趣。
Author Topic Model[ATM理解及公式推导]
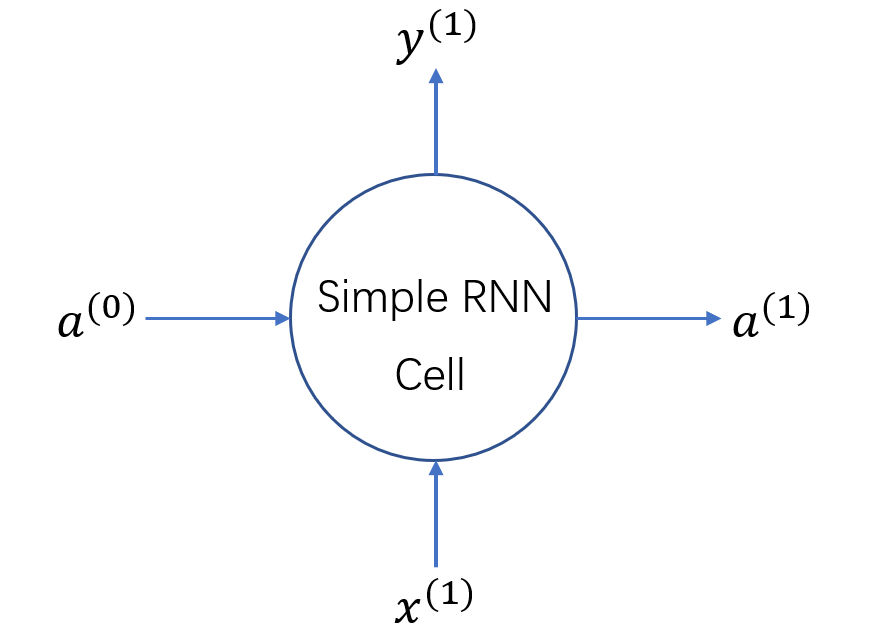
RNN的应用有很多,尤其是两个RNN组成的Seq2Seq结构,在时序预测、自然语言处理等方面有很大的用处,而每个RNN中一个节点是一个Cell,它是RNN中的基本结构。本文从如何使用RNN建模数据开始,重点解释RNN中Cell的结构,以及Keras中Cell相关的输入输出及其维度。我已经尽量解释了每个变量,但可能也有忽略,因此可能对RNN之前有一定了解的人会更友好,本文最主要的目的是描述Keras中RNNcell的参数以及输入输出的两个注意点。如有问题也欢迎指出,我会进行修改。
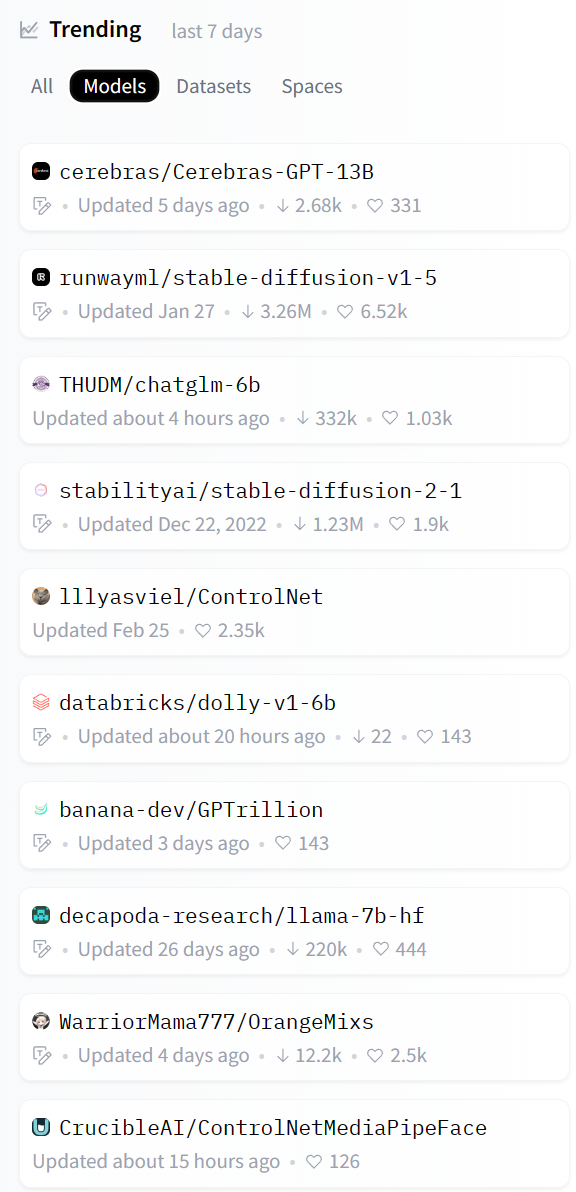
HuggingFace是目前最火热的AI社区(HuggingFace简介:https://www.datalearner.com/blog/1051636550099750 ),很多人称之为AI模型的GitHub。包括Google、微软等很多知名企业都在上面发布模型。而HuggingFace上提供的流行的模型也是大家应当关注的内容。本文简单介绍一下2023年4月初的七天(当然包括3月底几天)的最流行的9个模型(为什么9个,因为我发现第10个是一个数据集!服了!)。让大家看看地球人都在关注和使用什么模型。
DALLE·2的出现,让大家认识到原来文本生成图片可以做到如此逼真效果,此后Stable Diffusion的开源也让大家把Text-to-Image玩出花了。而现在,Meta AI的研究人员让这个工作继续往前一步,发布了Text-to-Video的预训练模型:Make-A-Video。

科研小助手,帮助认识科研中常见缩写词和混淆词等,来自《机器学习导论》的专业词汇
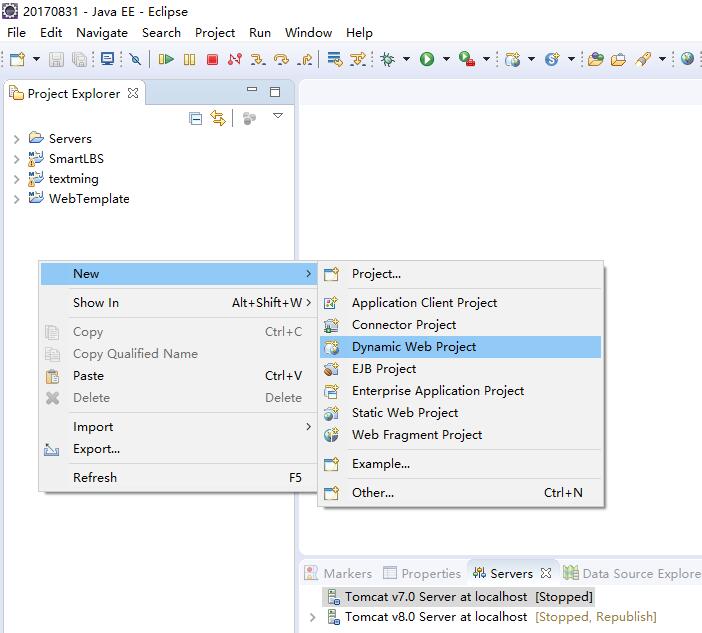
使用SpringMVC框架搭建Web项目工程是目前非常流行的web项目创建方式。同时Spring Security也为我们提供了登录验证和权限控制等内容。
![[翻译]当推荐系统遇上深度学习](https://www.datalearner.com/resources/blog_images/2cdfcd04-ad6f-4183-9e6e-0c3b24ec4515.png)
翻译自Wann-Jiun Ma的Deep Learning Meets Recommendation Systems,主要讲了推荐系统的基础算法以及使用深度学习对电影的海报进行近似计算,从而推荐相似的电影。
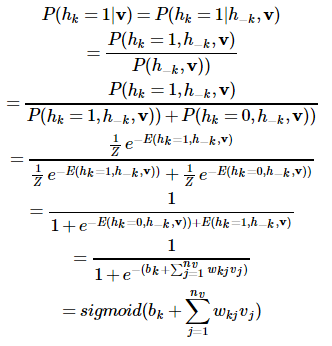
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是G.Hinton教授的一宝。Hinton教授是深度学习的开山鼻祖,也正是他在2006年的关于深度信念网络DBN的工作,以及逐层预训练的训练方法,开启了深度学习的序章。其中,DBN中在层间的预训练就采用了RBM算法模型。RBM是一种无向图模型,也是一种神经网络模型。

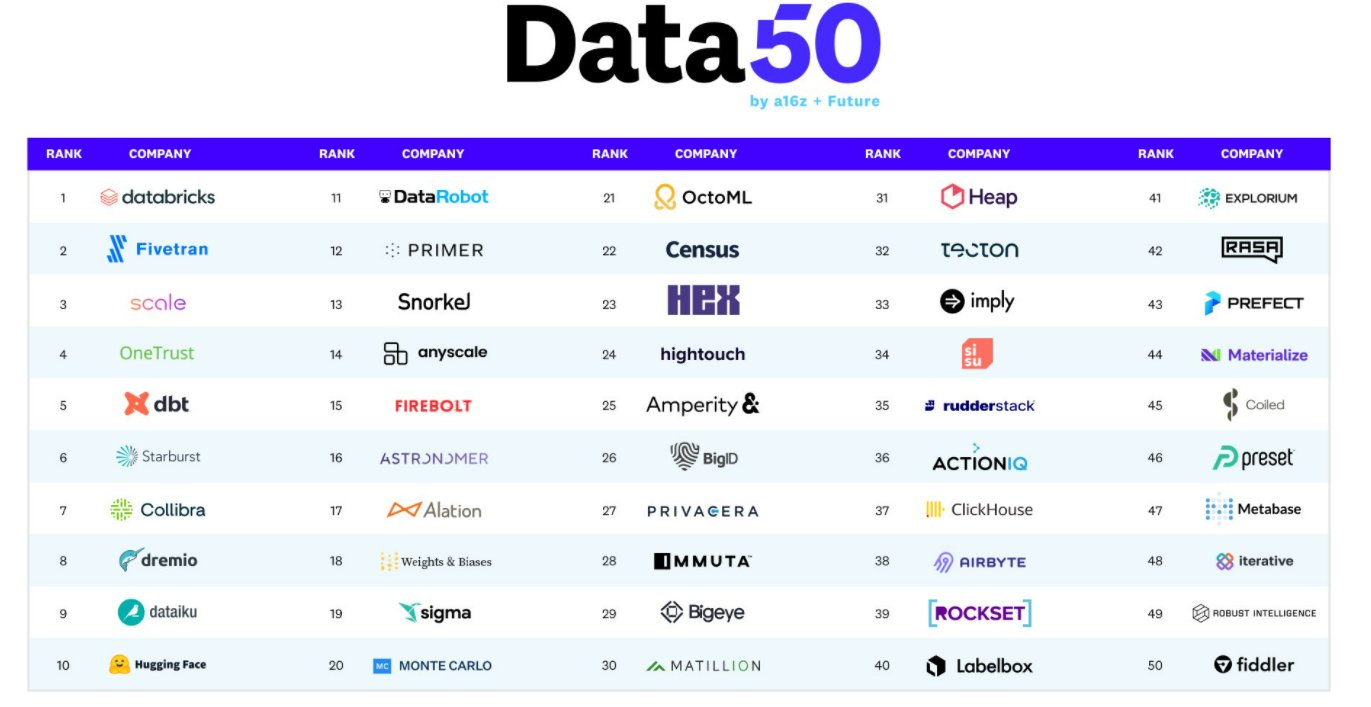
最近几年,数据的重要性在各个领域都获得了巨大的重视。因此,数据管理相关的业务也成为各项基础设施中增长最快的业务,目前的市场规模约700亿美元,占所有企业的基础设施支持约1/5。仅在2021年,数据处理相关的公司获得了数百亿的风险投资。为此,Future总结了2022年全球最大的50家数据创业企业。这里我们列举其中的最大的10个进行介绍。