
【转载】全面解读ICML 2017五大研究热点 | 腾讯AI Lab独家解析
腾讯AI Lab去年四月成立,今年是首次参加ICML,共计四篇文章被录取,位居国内企业前列。此次团队由机器学习和大数据领域的专家、腾讯AI Lab主任张潼博士带领到场交流学习,张潼博士还担任了本届ICML领域主席。在本次130人的主席团队中,华人不超过10位,内地仅有腾讯AI Lab、清华大学和微软研究院三家机构。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
腾讯AI Lab去年四月成立,今年是首次参加ICML,共计四篇文章被录取,位居国内企业前列。此次团队由机器学习和大数据领域的专家、腾讯AI Lab主任张潼博士带领到场交流学习,张潼博士还担任了本届ICML领域主席。在本次130人的主席团队中,华人不超过10位,内地仅有腾讯AI Lab、清华大学和微软研究院三家机构。
网络爬虫
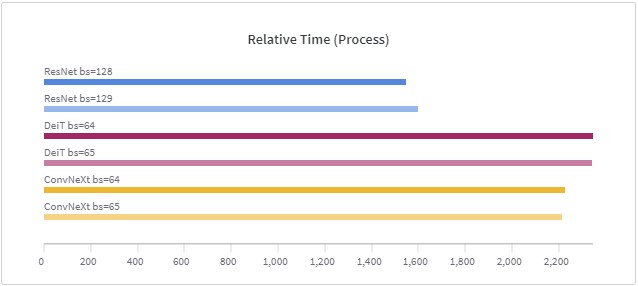
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。
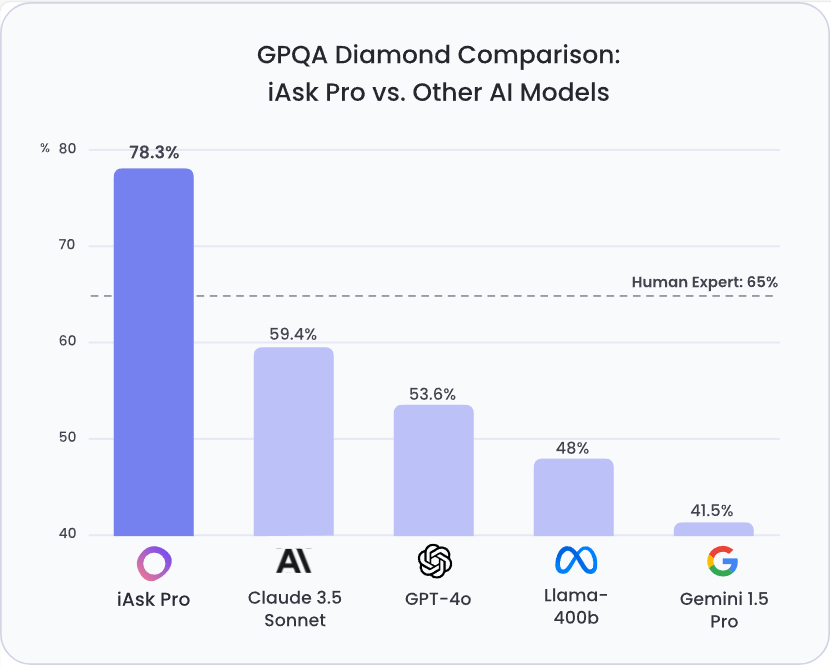
通用人工智能(AGI)的进步需要可靠的评估基准。GPQA (Grade-Level Problems in Question Answering) Diamond 基准旨在衡量模型在需要深度推理和领域专业知识问题上的能力。该基准由纽约大学、CohereAI 及 Anthropic 的研究人员联合发布,其相关论文可在 arXiv 上查阅 (https://arxiv.org/pdf/2311.12022 )。GPQA Diamond是GPQA系列中最高质量的评测数据,包含198条结果。
python中Scrapy的安装详细过程
HttpClient的使用方法案例 爬虫
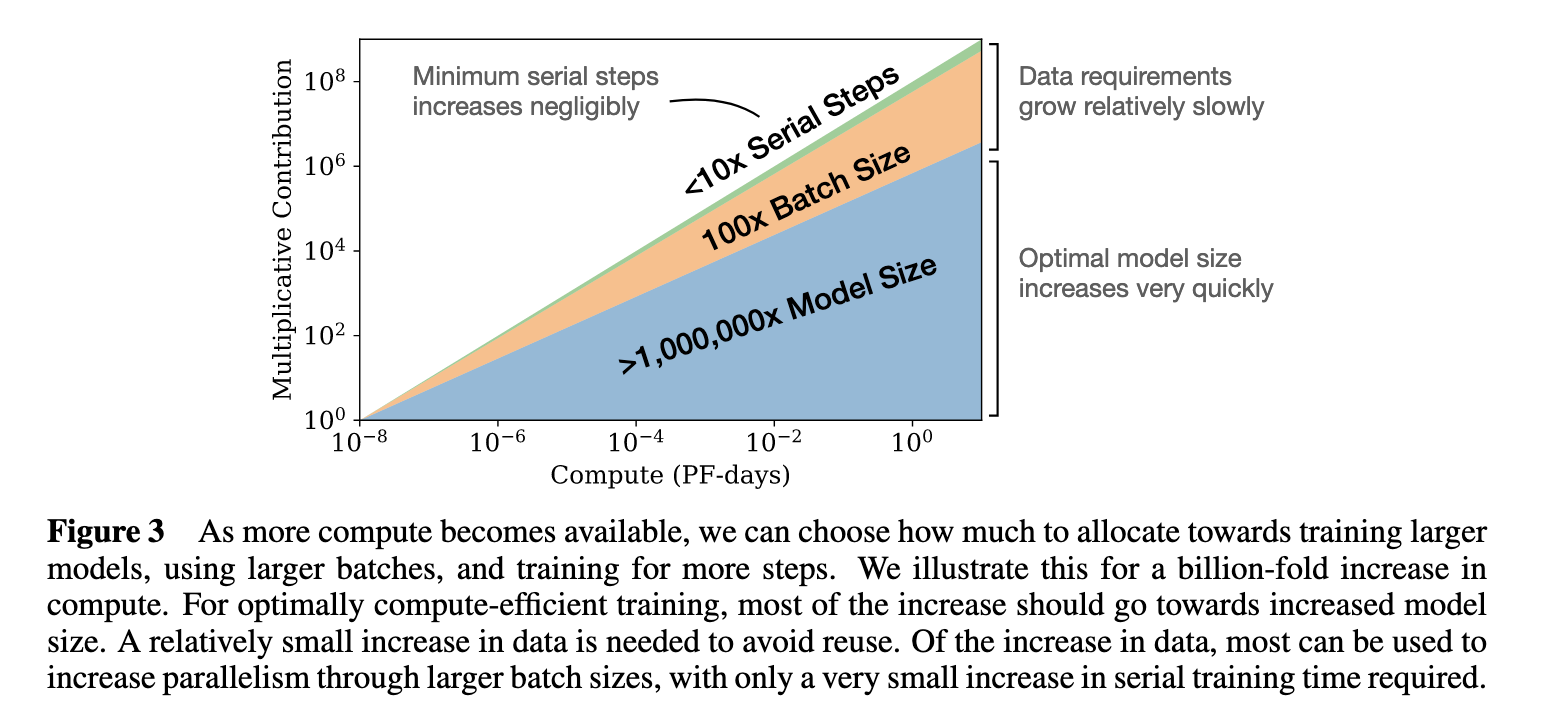
3月29日,DeepMind发表了一篇论文,"Training Compute-Optimal Large Language Models",表明基本上每个人--OpenAI、DeepMind、微软等--都在用极不理想的计算方式训练大型语言模型。论文认为这些模型对计算的使用一直处于非常不理想的状态。并提出了新的模型缩放规律。
网路爬虫数据库操作
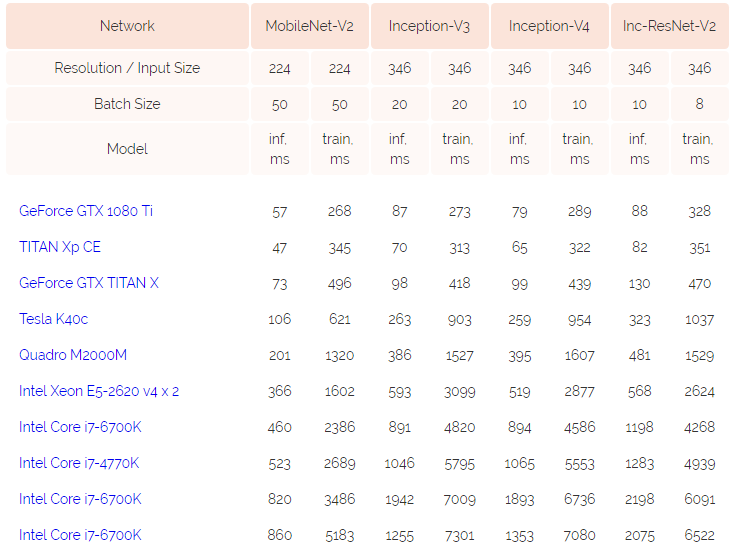

Pandas和NumPy是Python数据科学领域中最基础的两个库,他们都可以读取大量的数据并对数据做计算等处理。有很多的操作他们都能做。那么,这两个Python库在数据处理的性能上有什么差别呢?今天在Reddit上看到一个有意思的讨论和大家分享一下。
ChatGLM系列是智谱AI发布的一系列大语言模型,因为其优秀的性能和良好的开源协议,在国产大模型和全球大模型领域都有很高的知名度。今天,智谱AI开源其第三代基座大语言模型ChatGLM3-6B,官方说明该模型的性能较前一代大幅提升,是10B以下最强基础大模型!
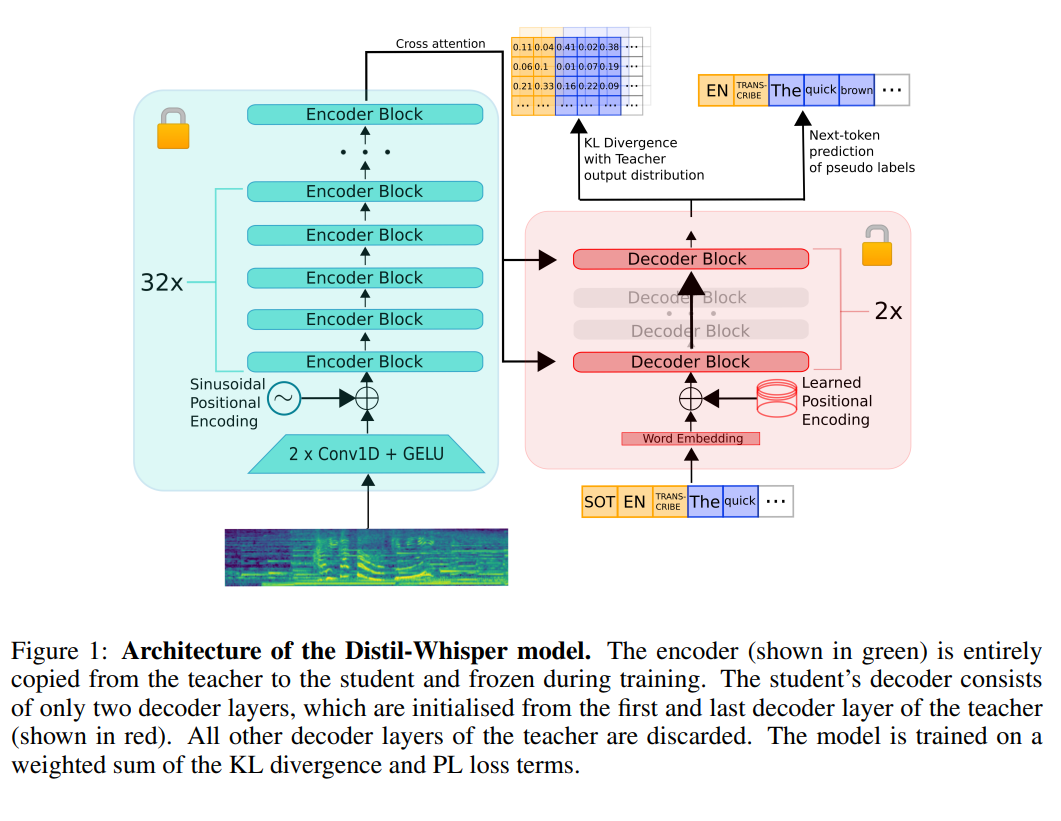
语音识别在实际应用中有非常多的应用。早先,OpenAI发布的Whisper模型是目前语音识别模型中最受关注的一类,也很可能是目前ChatGPT客户端语音识别背后的模型。HuggingFace基于Whisper训练并开源了一个全新的Distil-Whisper,它比Whisper-v2速度快6倍,参数小49%,而实际效果几乎没有区别。
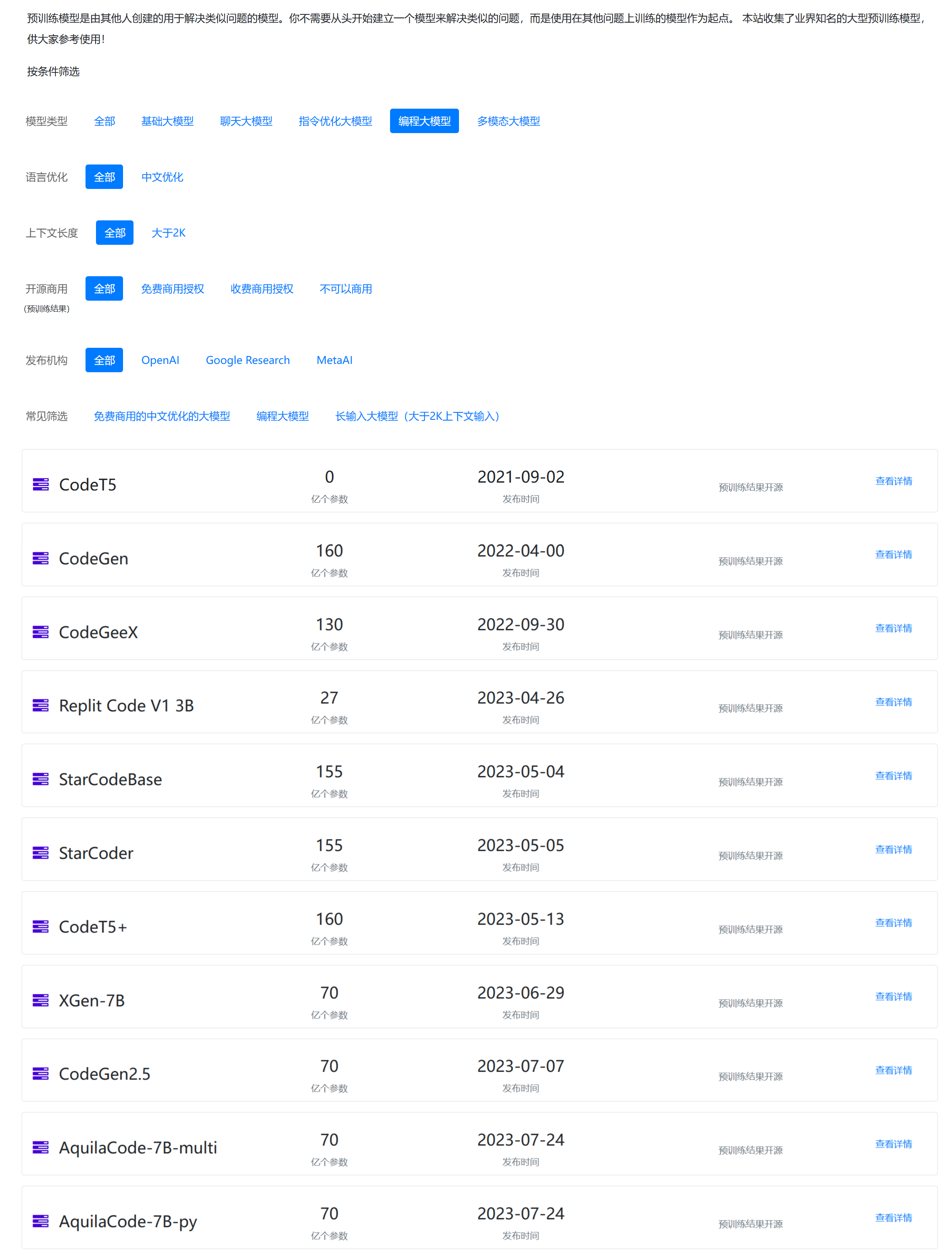
编程大模型是大语言模型的一个非常重要的应用。刚刚,清华大学系创业企业智谱AI开源了最新的一个编程大模型,CodeGeeX2-6B。这是基于ChatGLM2-6B微调的针对编程领域的大模型。

刚刚,StabilityAI宣布Stable Diffusion2.1发布。距离Stable Diffusion2.0大版本发布刚2个星期,2.1版本就发布了,2.1版本有诸多改进功能。

Cornell Tech开源了LLMTune,这是一个可以在消费级显卡上微调大模型的框架,经过测试,可以在48G显存的显卡上微调4bit的650亿参数的LLaMA模型!
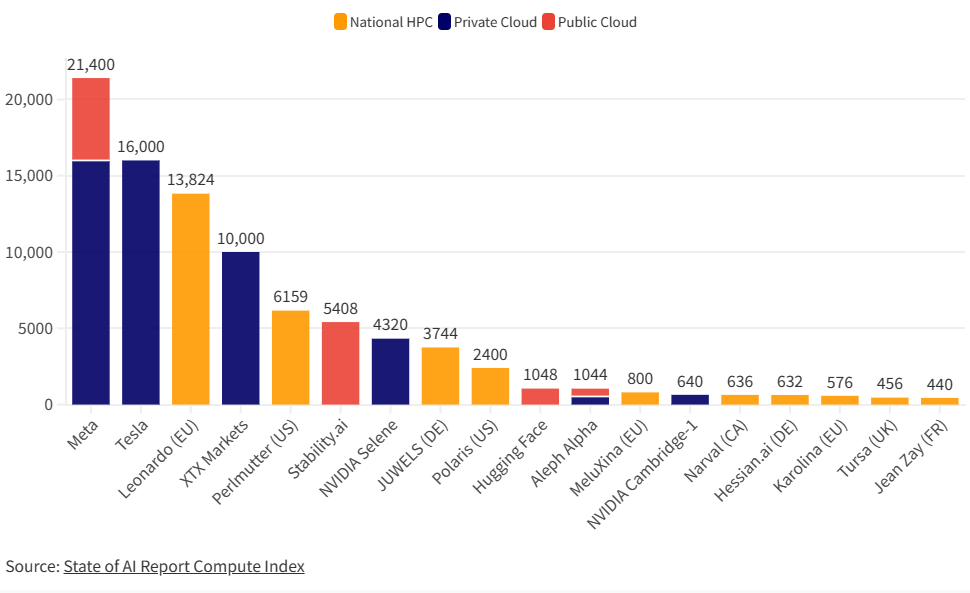
在高性能计算(HPC)、人工智能(AI)、和数据分析等领域,图形处理器(GPUs)正在发挥越来越重要的作用。其中,NVIDIA的 A100尤为引人注目。这是英伟达最强大的显卡处理器,也是当前使用最广泛大模型训练用的显卡。本文主要是各大企业最新的2023年9月份拥有的显卡数量统计。
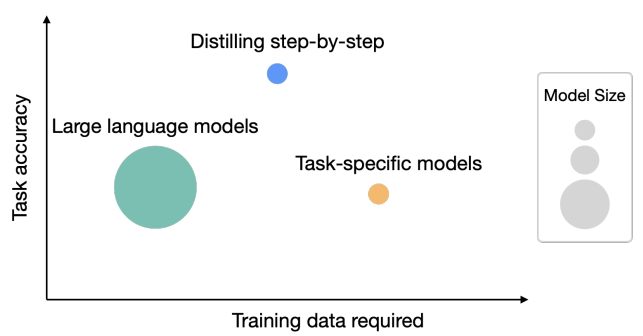
华盛顿大学研究人员与Google的研究人员一起在5月3日公布了一个新的方法,即逐步蒸馏(Distilling step-by-step),这个方法最大的特点有2个:一是需要更少的数据来做模型的蒸馏(根据论文描述,平均只需要之前方法的一半数据,最多只需要15%的数据就可以达到类似的效果);而是可以获得更小规模的模型(最多可以比原来模型规模小2000倍!)
本文是Effective Java第三版笔记的第二个之当构造参数很多的时候考虑使用builder