统计、机器学习与编程知识的原创博客
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
最新博客

重磅!来自Google内部AI研究人员的焦虑:We Have No Moat And neither does OpenAI
5月4日,网络流传了一个所谓Google内部人员写的内部信,表达了Google和OpenAI这样的公司可能并不能在AI领域获得胜利的焦虑。里面说明了开源的AI模型发展迅速,不管是Google还是OpenAI都没有很好的护城河。
为什么Python可以处理任意长度的整数运算——Python原理详解
在做LeetCode题目的时候,有一类题目是关于大数运算的。比如,全排列计算或者组合运算,在使用C语言或者Java代码解决这类问题的时候都会遇到变量数值超过阈值的情况。一般来说需要自己构造字符串数组或者是其它数组来存储超过长度的数值。但是,使用Python语言处理这类问题时候却毫无压力,这类题目的计算不会有任何问题。本文将从Python底层实现解释这个问题。
Awesome ChatGPT Prompts——一个致力于提供挖掘ChatGPT能力的Prompt收集网站
Awesome ChatGPT Prompts是由JavaScript开发者Fatih Kadir Akın创建的一个网站和应用,里面收集了160多个关于ChatGPT的Prompt模板,可以让ChatGPT变成Linux终端、JavaScript控制台、Excel页面等。这些Prompts收集自优秀的实践案例。
重磅!苹果官方发布大模型框架:一个可以充分利用苹果统一内存的新的大模型框架MLX,你的MacBook可以一键运行LLaMA了
苹果刚刚发布了一个全新的机器学习矿机MLX,这是一个类似NumPy数组的框架,目的是可以在苹果的芯片上更加高效地运行各种机器学习模型,当然最主要的目的是大模型。
Map或Hashtable的value排序
Map或Hashtable的value排序

网络爬虫之基础java集合操作篇
网络爬虫之基础java集合操作篇
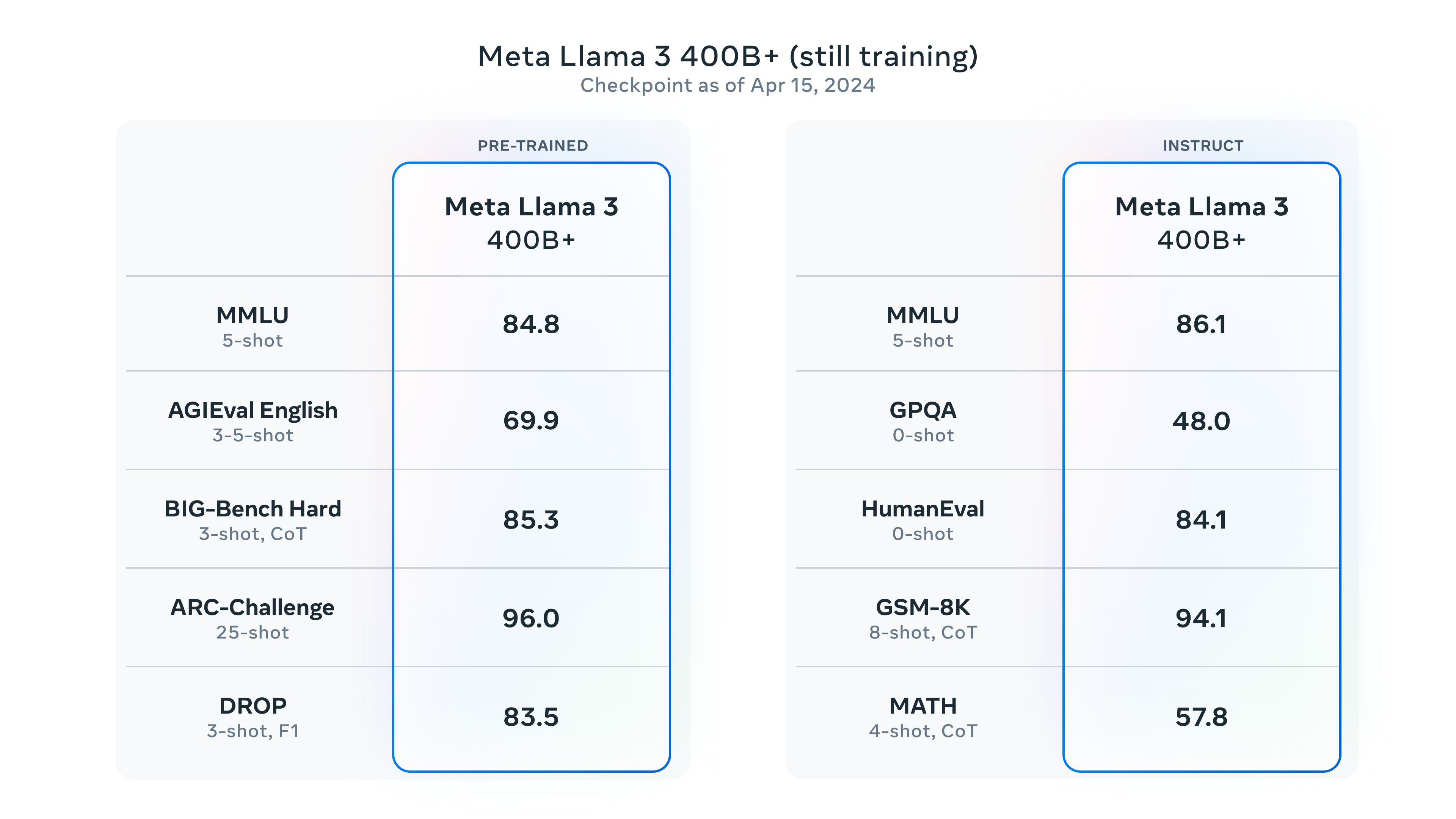
开源王者!全球最强的开源大模型Llama3发布!15万亿数据集训练,最高4000亿参数,数学评测超过GPT-4,全球第二!
大语言模型开源领域最重要的一个模型就是MetaAI开源的Llama系列。当前,很多著名开源模型都是基于Llama系列进行预训练得到。就在刚才,MetaAI开源了第三代Llama3系列。官方透露的信息非常多,Llama3系列是目前为止最强的开源大语言模型,未来还有4000亿参数版本,支持多模态、超长上下文、多国语言!

全球主要开源组织概述
开源软件在现代互联网技术的发展中扮演者重要的作用。很多技术的进步和发展都是由开源软件推动的。而开源软件的发展离不开背后强大的开源组织的管理。本文列举最著名的五个开源组织,简述其背景,欢迎大家阅读。
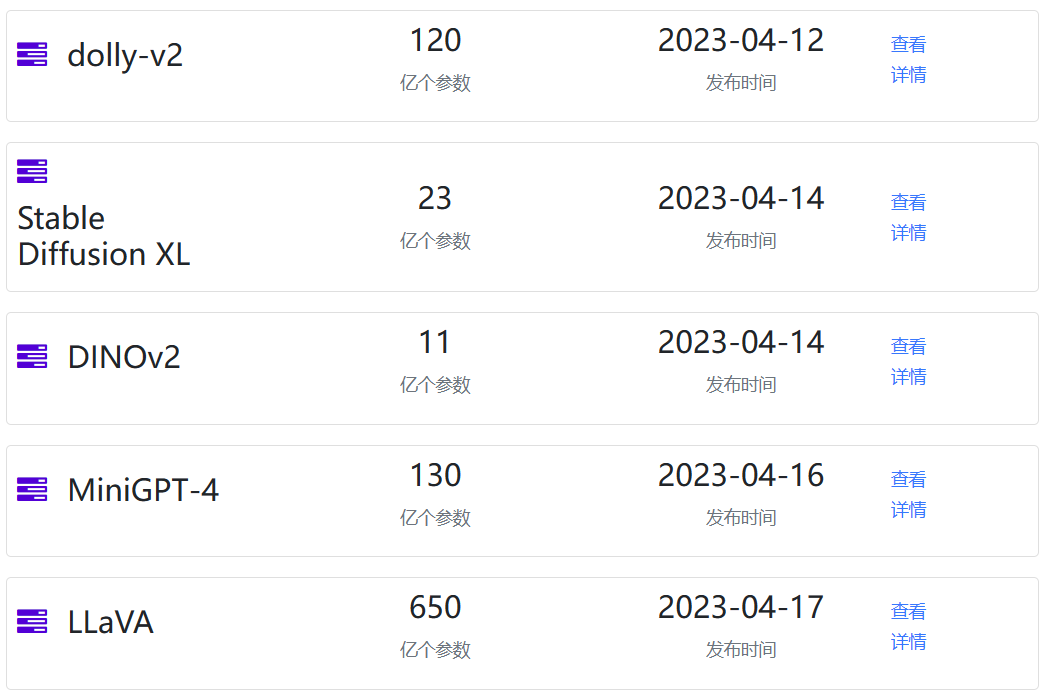
2023年4月中旬值得关注的几个AI模型:Dollly2、MiniGPT-4、LLaVA、DINOv2
AI模型的发展速度令人惊讶,几乎每天都会有新的模型发布。而2023年4月中旬也有很多新的模型发布,我们挑出几个重点给大家介绍一下。
学术工具
为学术新人提供的学术工具列表
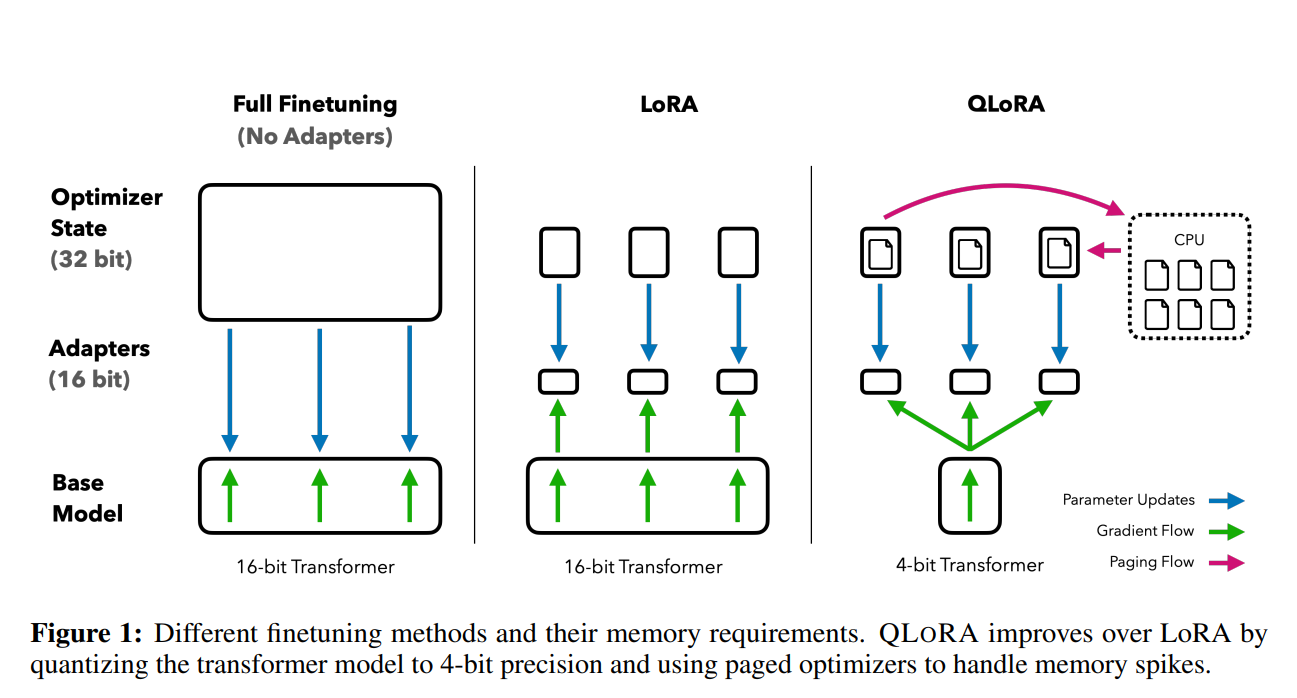
华盛顿大学提出QLoRA及开源预训练模型Guanaco:将650亿参数规模的大模型微调的显存需求从780G降低到48G!单张显卡可用!
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!
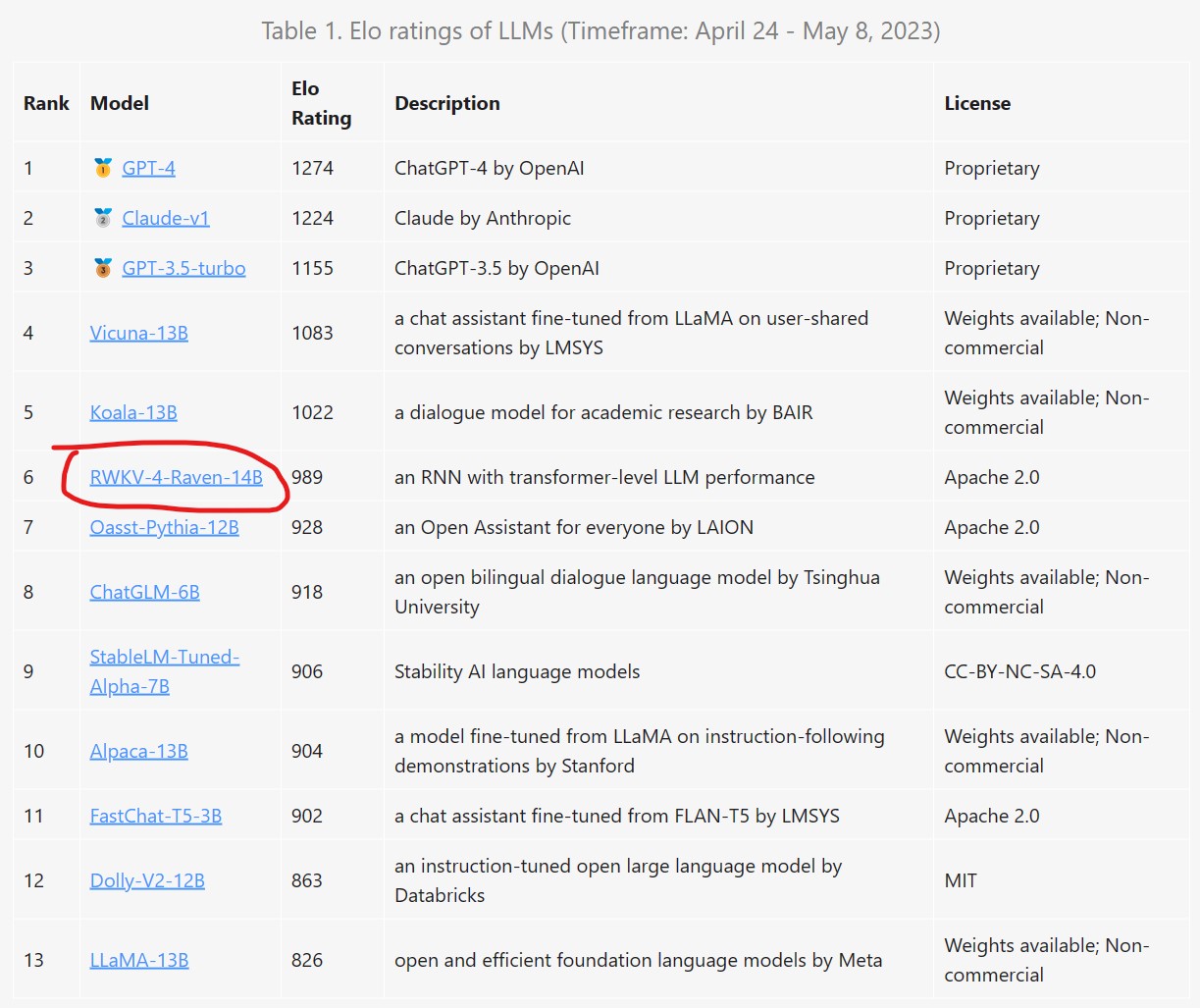
HuggingFace宣布在transformers库中引入首个RNN模型:RWKV,一个结合了RNN与Transformer双重优点的模型
RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。今天,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型,足见RWKV模型的价值。

Python入门的基本概念之包管理——pip与conda的简介对比
对于刚接触使用Python的同学来说,Python强大的生态与优秀的开源工具应该印象十分深刻。同时对于一些已经在使用Python解决问题的童鞋来说,使用pip来安装一些别人提供的工具应该已经熟悉了。当然,也有一些同学应该也听说可以使用conda来安装一些第三方的开源包。那么,python的包管理工具pip是一个什么样的东西?conda作为一个替代者或者补充,与pip有什么区别,二者分布适合什么情况下使用呢?本文将根据我的个人经验与观点为大家做一个简单的说明。
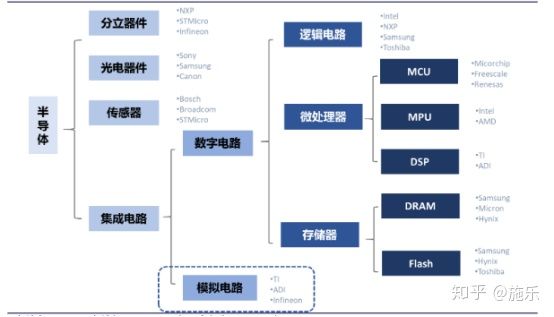
半导体市场概览
美国对华为的制裁让我们看到半导体领域核心技术国产化的重要性,尽管国内互联网发展迅速,也产生了阿里、腾讯、美团等巨头,但是底层的硬件技术依然依赖于西方国家。其实我个人觉得也不是我们多么希望自己自力更生,实在是被逼无奈,时不时断供一下,这谁能受得了。最近个人也在补充这些知识,把一些学习的这些东西记录下来,如有问题也希望大家指出。

OpenAI CEO详解今明两年GPT发展计划:10万美元部署私有ChatGPT、最高支持100万tokens、建立微调模型应用市场
前段时间,OpenAI的CEO Sam Altman与二十多位开发者一起聊了很多关于OpenAI的API和产品的规划问题。Sam Altman透露了一些非常重要的OpenAI的发展方向,包括GPT产品功能的未来规划等。目前这份原始博客内容已经应OpenAI的要求被删除,这里我们简单总结一下这些内容。
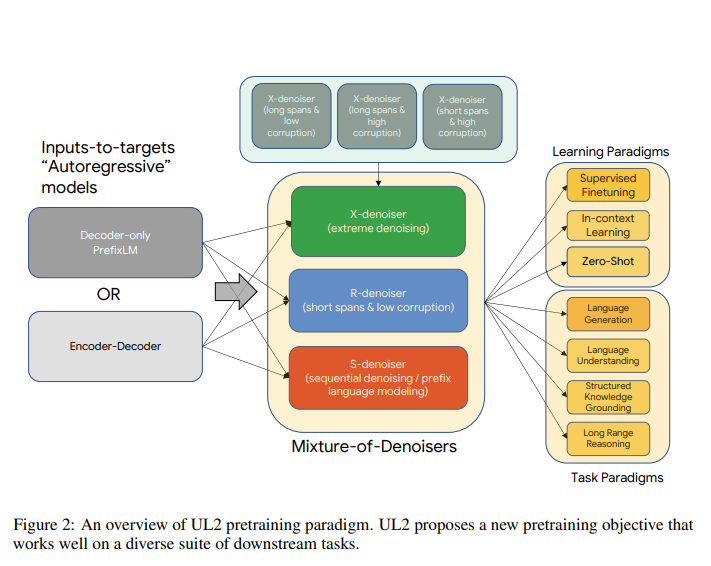
Unifying Language Learning Paradigms——谷歌的一个模型打天下
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。 而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。


0基础安装搭建Visual Studio Code开发环境——Python开发环境
Visual Studio Code简称VS Code,是由微软开发的跨平台免费开源的源代码编辑器。相比较Eclipse、PyCharm等软件,它很轻量,并不太像一个完整的IDE(Integrated Development Environment,集成开发环境)。但是,由于其轻量、快速、第三方扩展生态强大等原因,在2015年推出之后就迅速发展成为最受欢迎的开发环境。2019年的Stack Overflow的开发者调查中名列第一,使用占比月50.7%。

GPT-4在11月份以来变懒的原因可能已经找到:大模型可能会在节假日期间变得不愿意干活,工作日期间却更加高效
最近一段时间,很多人普遍反映GPT-4变得懒散和愚笨,很多此前可以回答的问题在最近一段时间都无法回答,或者回答比较简单。为此,OpenAI官方也在前几天发布信息说的确收到了这样的信息,但是模型并没有在最近一个多月更新过,所以他们也在好奇是什么原因。而今天的一些测试表明,GPT-4模型会像人一样在不同的时间段有不同的效率。