
PyTorch终于支持苹果的M1芯片了!
自从苹果发布M1系列的自研芯片开始,基于ARM架构的电脑处理器开始大放异彩。而强大的M1芯片的能力也让很多Mac用户高兴很久。而就在现在,M1也开始支持PyTorch的深度学习框架了。PyTorch官网刚刚宣布,经过和Apple的Metal工程师队伍的合作,PyTorch支持Mac的GPU加速了。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
自从苹果发布M1系列的自研芯片开始,基于ARM架构的电脑处理器开始大放异彩。而强大的M1芯片的能力也让很多Mac用户高兴很久。而就在现在,M1也开始支持PyTorch的深度学习框架了。PyTorch官网刚刚宣布,经过和Apple的Metal工程师队伍的合作,PyTorch支持Mac的GPU加速了。
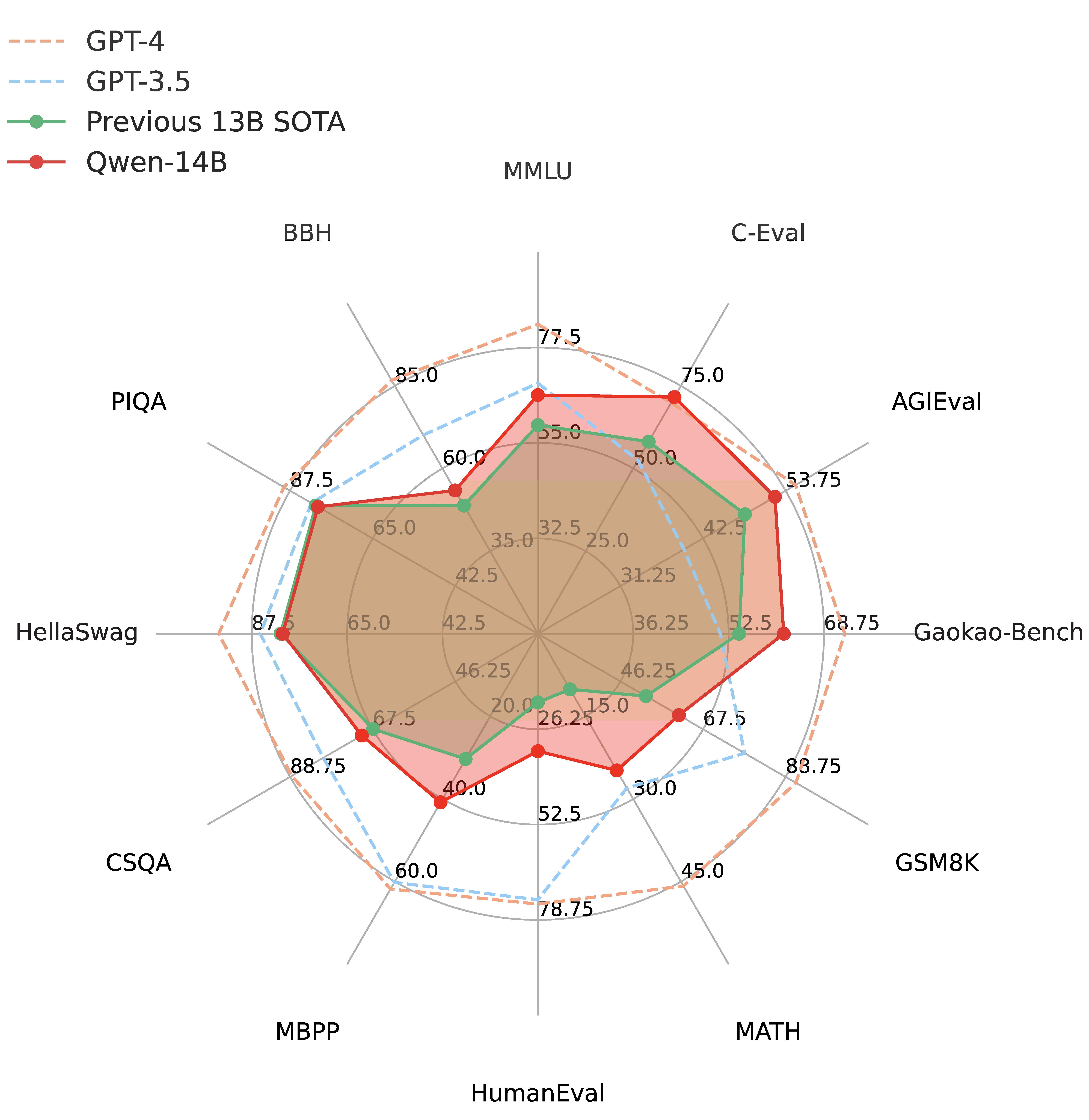
通义千问是阿里巴巴推出的一个大语言模型,此前开源的Qwen-7B引起了广泛的关注,因为他的理解能力很强但是参数规模很小,因此受到了很多人的欢迎。而目前再次开源全新的Qwen-14B的模型,参数规模142亿,但是它的理解能力接近700亿参数规模的LLaMA2-70B,数学推理能力超过GPT-3.5。

文中整理和总结了几个关于开源大模型微调方面的问题,答案主要来自gpt4 + google,如果其中部分问题的答案不准确,烦劳指正 (文中引用了外部资源链接,如果涉及版权问题,烦劳联系作者删除)

DALL·E 系列是由 OpenAI 开发的一系列基于大型语言模型的文本到图像生成系统。它们的核心目标是将文本描述转化为高度精确的图像。DALL·E2在2022年4月发布,但是一直没有公开使用,一年半后的2023年9月21日,OpenAI发布第三代DALL·E3,并承诺将与ChatGPT集成。

xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。xAI今天也宣布了Grok模型的细节。其在多个知名榜单评测上的得分结果超过了ChatGPT-3.5水平。本文详细介绍一下这个模型。
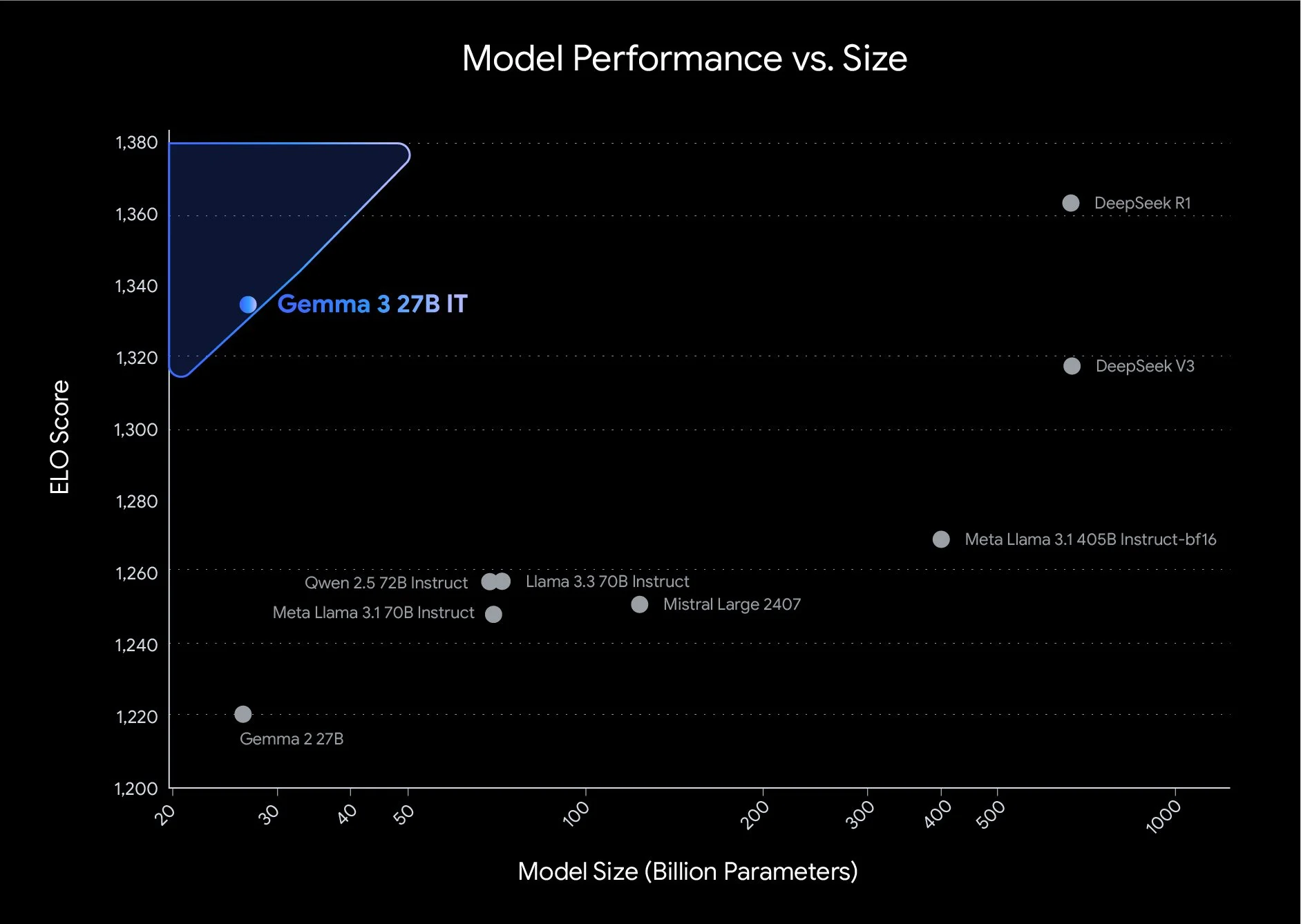
Gemma系列大模型是Google开源的一系列轻量级的大模型。就在刚才(2025年3月12日),Google开源了第三代Gemma系列大模型,共包含4个不同参数规模版本,第三代的Gemma 3系列是多模态大模型,即使是最小的10亿参数规模的Gemma 3-1B也支持多模态输入。
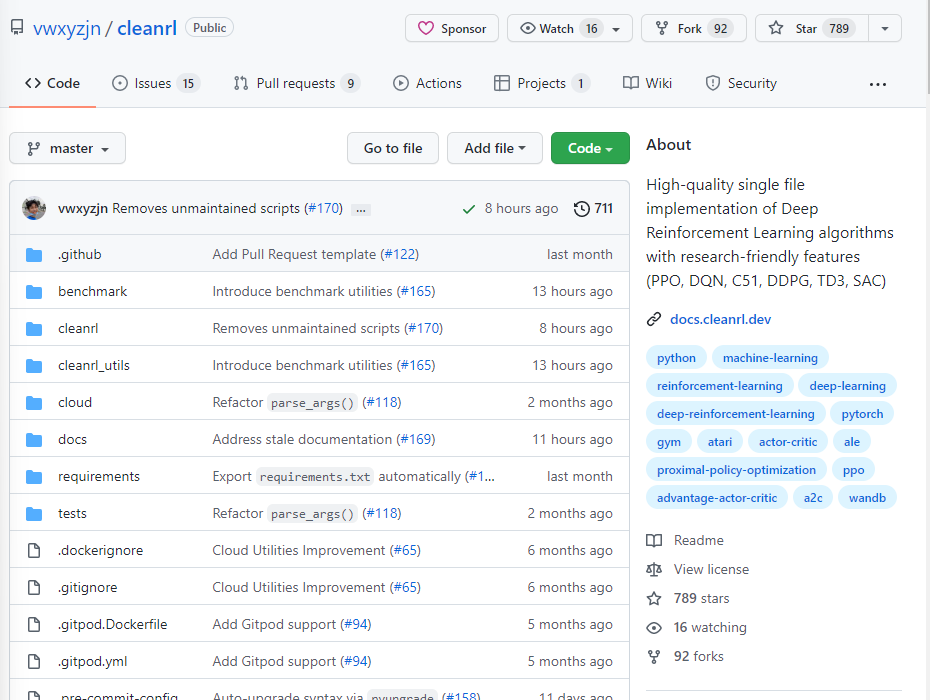
很多算法的开源实现都包含多个文件,因此,学习这些开源代码的时候通常难以找到入口,也无法快速理解作者的逻辑,对于学习的童鞋来说都带来了不小的挑战。这里推荐一个非常优秀的强化学习开源库,它将经典的强化学习算法都实现在一个文件中,想要学习源代码的童鞋只需要看单个文件即可,这就是ClearRL!

吴恩达的DeepLearningAI在今天和LangChain的创始人一起合作发布了一个最新的基于LangChain使用LLM构建私有数据的问答系统和聊天机器人的课程(课程名:《LangChain: Chat with Your Data》)。LangChain是大语言模型应用开发领域目前最火的开源库。集成十分多的优秀特性,可以帮助我们非常简单构建LLM的应用。

自从2019年OpenAI开始商业化以来,OpenAI的成果越来越封闭,而商业化的进程越来越快。GPT系列的发展正好印证了这个路径。GPT最初的版本包含了论文、代码和预训练结果。GPT-2刚开始也认为可能会造成不好的伤害而在论文官宣了大半年之后才公布了完整模型。到GPT-3的时候也就给了官方介绍博客和论文,模型则是彻底闭源且开始商业化。而今天OpenAI直接官方博客宣布GPT-3.5商业化,连论文都没有了!

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。
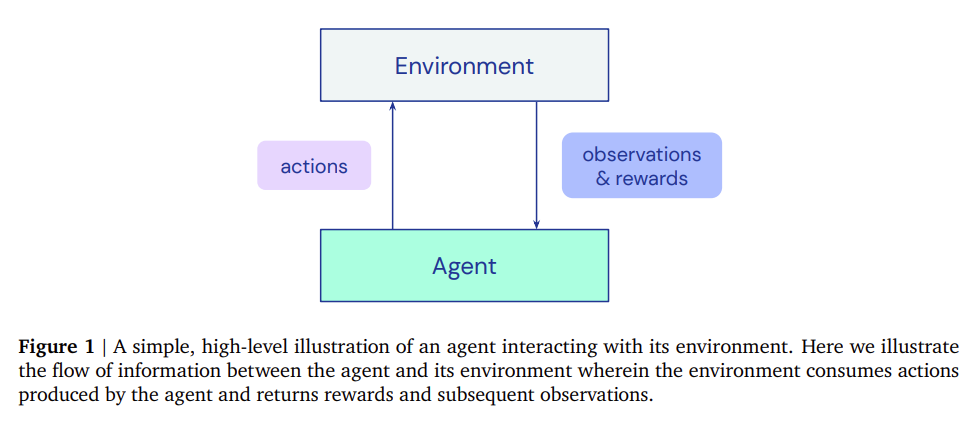
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的
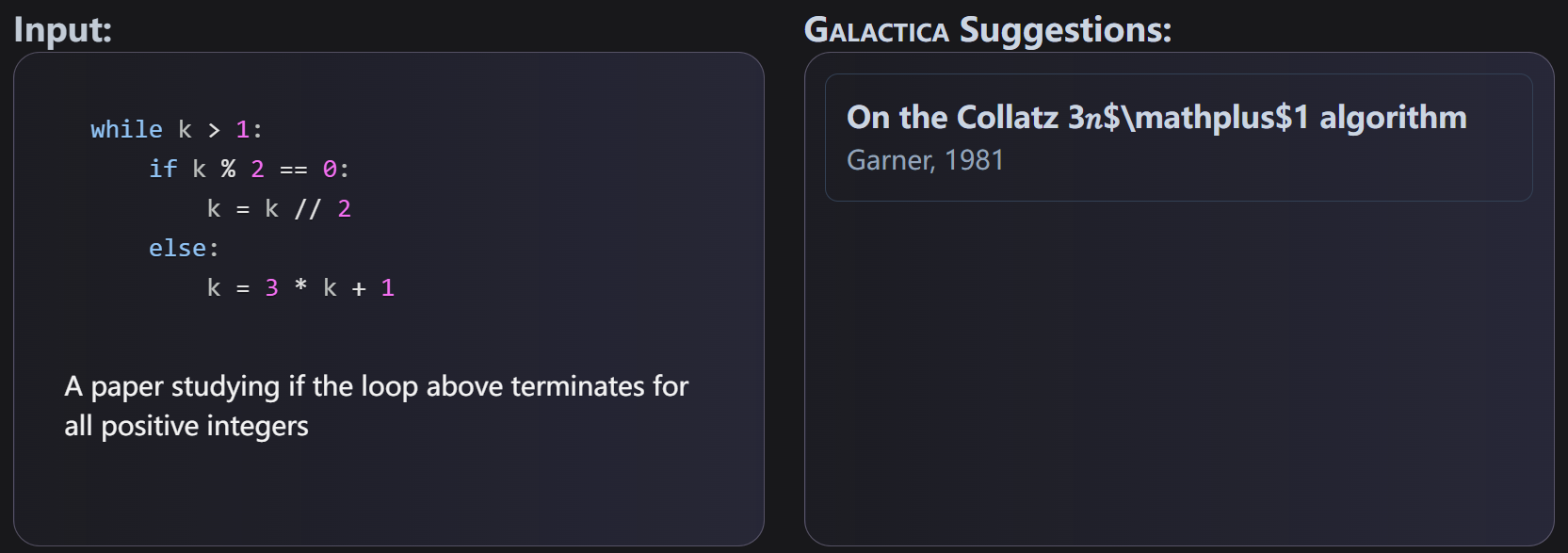
自然语言处理预训练大模型在最近几年十分流行,如OpenAI的GPT-3模型,在很多领域都取得了十分优异的性能。谷歌的PaLM也在很多自然语言处理模型中获得了很好的效果。而昨天,PapersWithCode发布了一个学术论文处理领域预训练大模型GALACTICA。功能十分强大,是科研人员的好福利!

Anthropic是一家专注于人工智能(AI)研究的公司,由OpenAI的前首席科学家Ilya Sutskever和Dario Amodei共同创立。Claude是Anthropic公司发布的基于transformer架构的大语言模型,被认为是最接近ChatGPT的商业产品。今天,Anthropic宣布Claude 2正式开始上架。

今天Google发布了TensorStore,这是一个开源的C++和Python软件库,设计用于存储和操作大规模n维数据。TensorStore已经被用来解决科学计算中的关键工程挑战(例如,管理和处理神经科学中的大型数据集,如石油级的三维电子显微镜数据和神经元活动的 "4d "视频)。TensorStore还被用于创建大规模的机器学习模型,如PaLM,解决了分布式训练期间管理模型参数(检查点)的问题。
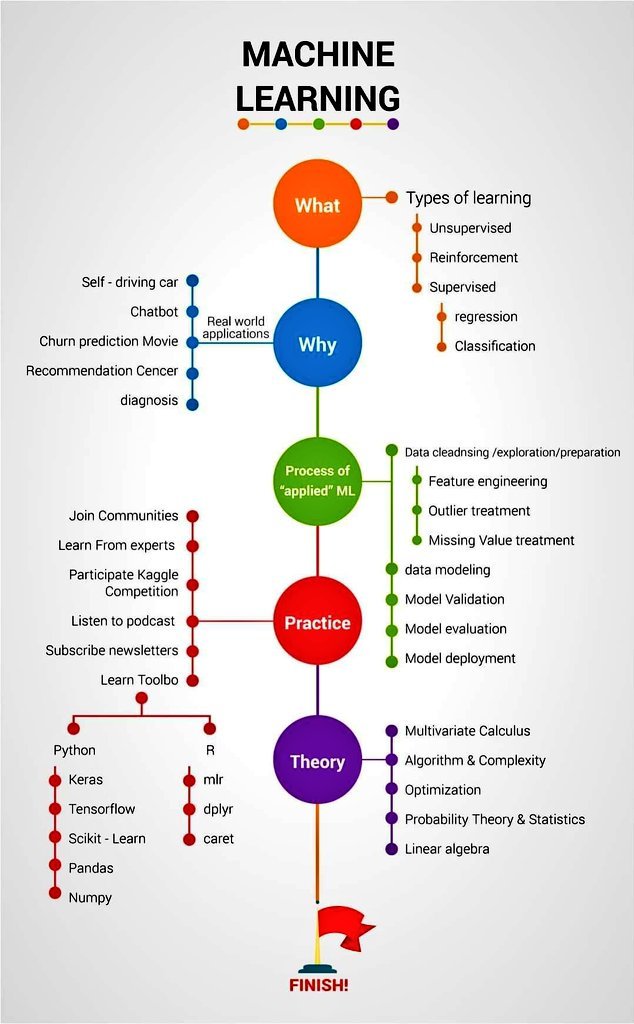
这是推特上Ternium的CIO发的一个图,关于机器学习理论和实践概念的信息图。这个图概括了机器学习实践流程的相关概念,简洁明了。对于入门的同学有很好的总结作用。
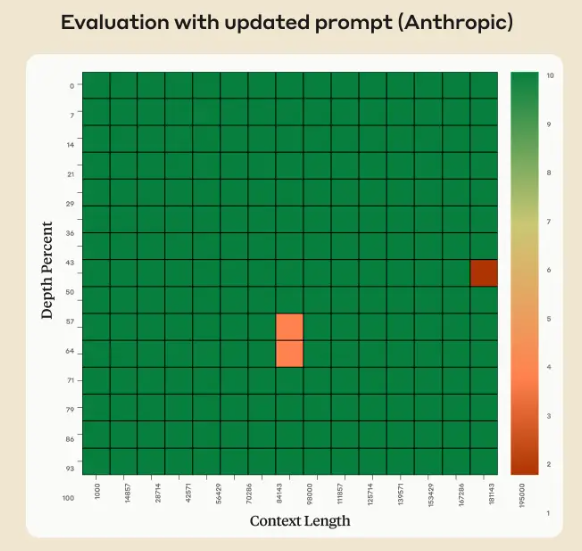
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。

GPT-5 在 ChatGPT 中引入了“自动在普通/推理间切换”的机制,但模式命名、配额规则和速率限制让许多用户困惑。本文梳理不同模式的作用、是否计入推理配额、各订阅层的可用性与限制、旧模型的替换规则,并提供三步配额优化策略。特别提示:编码与大上下文任务应优先使用 GPT-5 Thinking(≈196k 上下文),而普通 Chat 模式上下文为 32k。

大家都知道,编程的开发离不开互联网的支持,不管是编程的学习还是bug的修复,都需要社区和外部的支持。因此,我们全新开通了一个程序必备网站列表栏目,为大家提供一站式访问目录。也欢迎评论,大家可以说一下你们写代码时候喜欢用的网站,我们也会更新上去。在这里我们挑选几个必备网站简单介绍一下。

OpenAI在GPT-4发布一年之后再次更新其基础模型,发布最新的GPT-4o模型,其中o代表的是omni,即“全能”的意思。GPT-4o相比较此前最大的升级是对多模态的支持以及性能的提升。GPT-4o在各方面比GPT-4更强,但是速度更快,开发者接口的价格则只有一半!
深度求索是著名量化机构幻方量化旗下的一家大模型初创企业,成立与2023年7月份。他们开源了很多大模型,其中编程大模型DeepSeek-Coder系列获得了非常多的好评。而在今天,DeepSeek-AI再次开源了全新的多模态大模型DeepSeek-VL系列,包含70亿和13亿两种不同规模的4个版本的模型。

几分钟之前,OpenAI宣布ChatGPT支持多模态,目前已经支持语音的输入、语音的输出、理解图片的输入!不过目前似乎仅限于客户端~官方说的是未来2周内企业和Plus用户可以使用,后面会普及到其它用户!
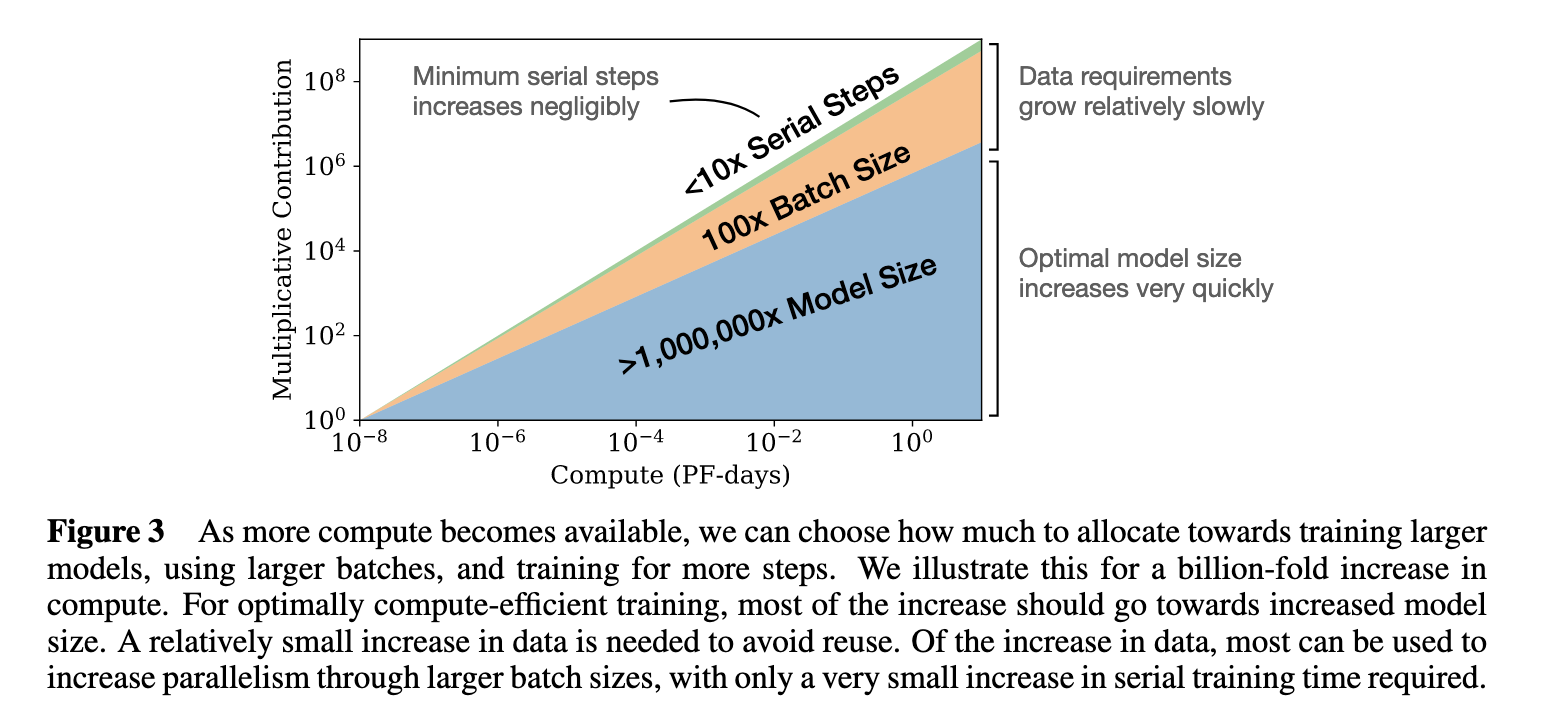
今晚已经是本周的最后一天了,最近的一些深度学习算法方面的进展做个总结吧,感觉都是挺不错的,供大家参考。
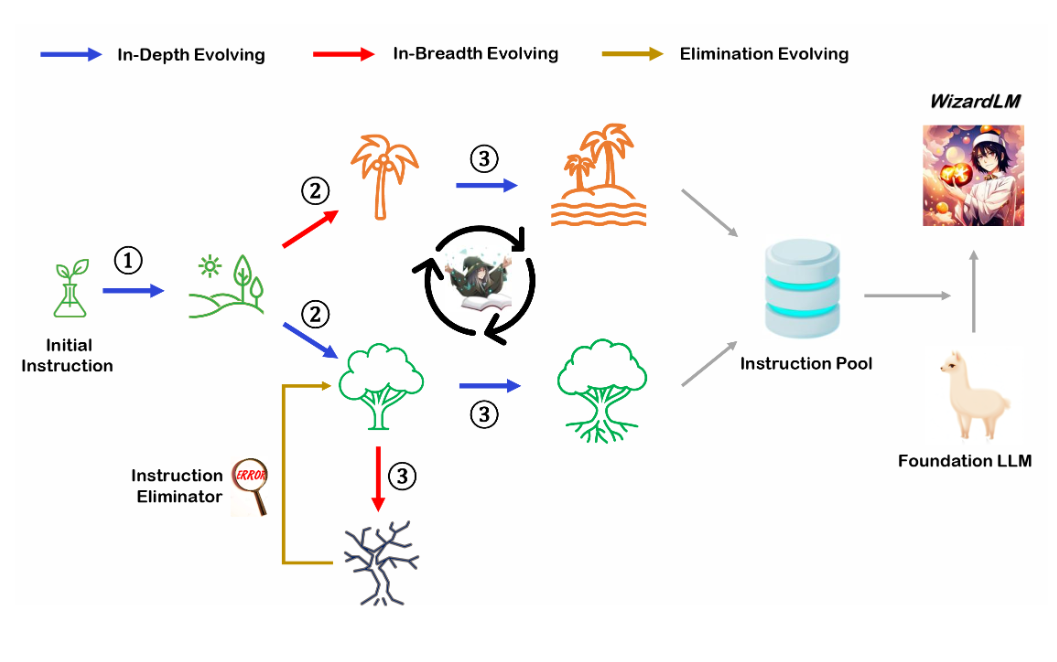
WizardLM是微软联合北京大学开源的一个大语言模型。此前,发布的WizardLM和WizardCoder都是业界开源领域最强的大模型。其中,前者是针对指令优化的大模型,而后者则是针对编程优化的大模型。而此次WizardMath则是他们发布的第三个大模型系列,主要是针对数学推理优化的大模型。在GSM8K的评测上,WizardMath得分超过了ChatGPT-3.5、Claude Instant-1等闭源商业模型,得分十分逆天!
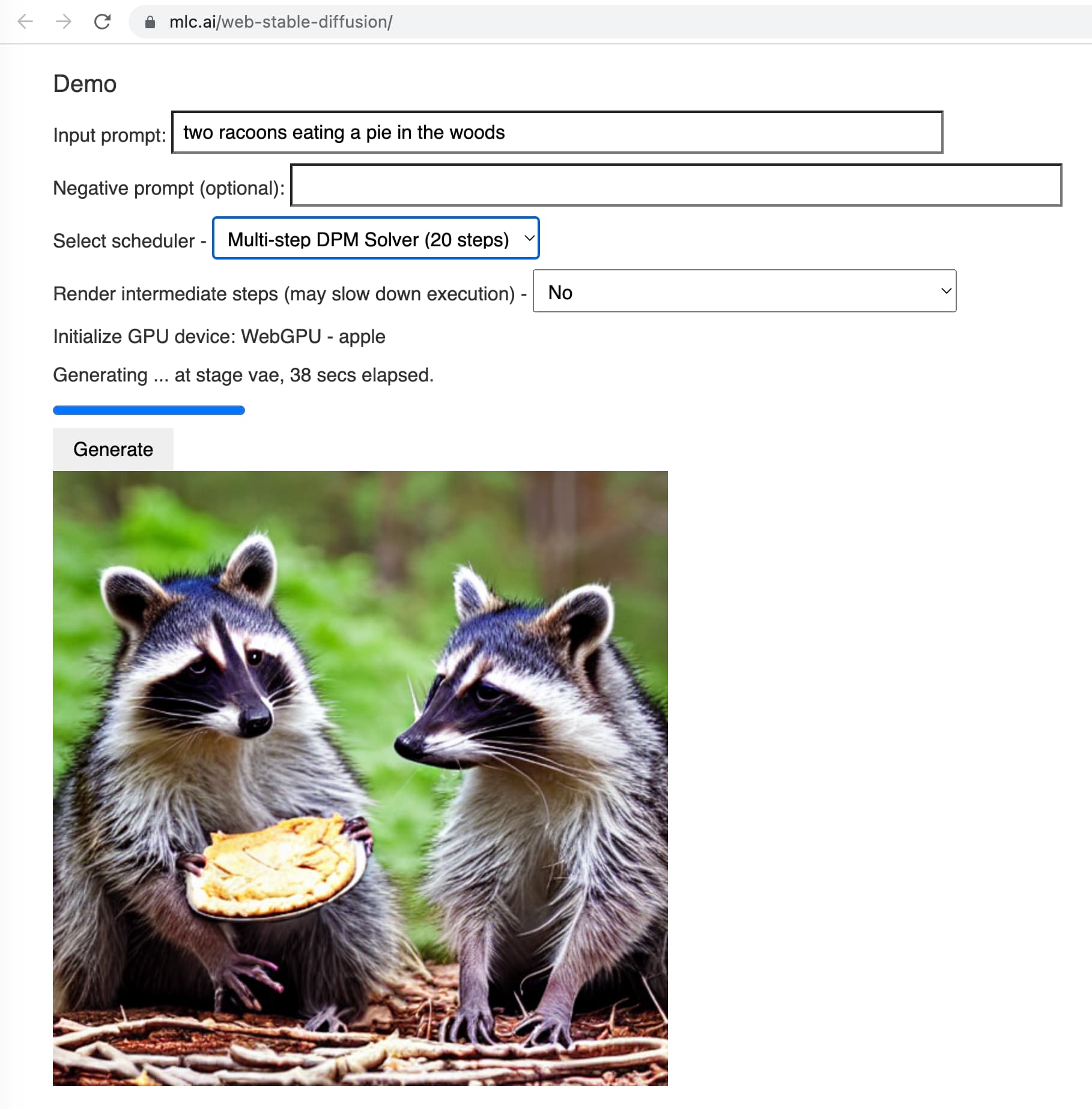
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!