
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



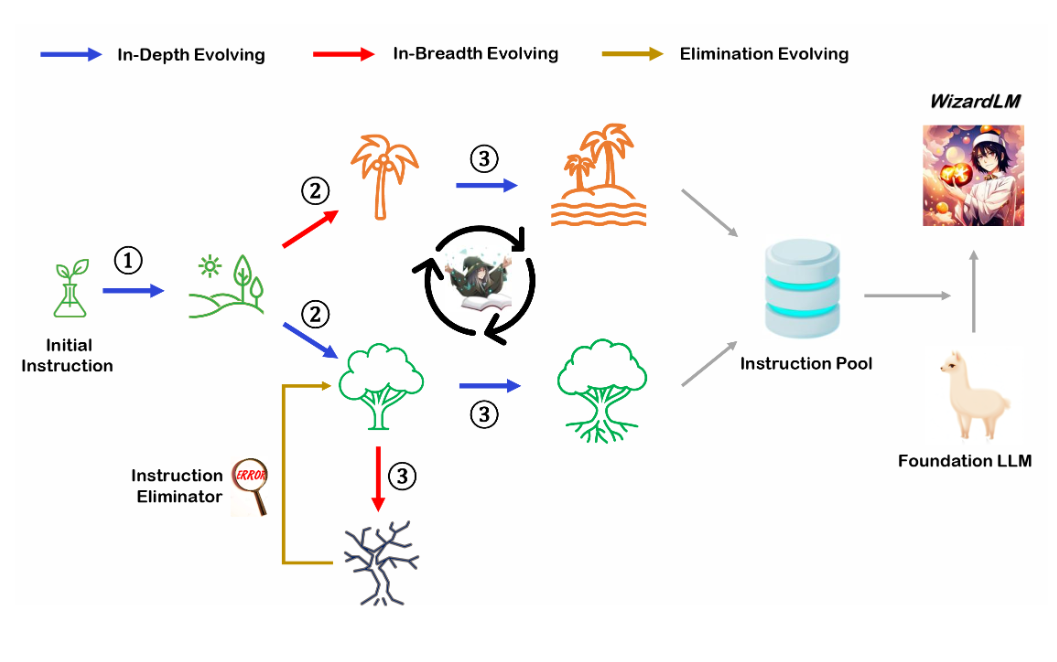
WizardLM是微软联合北京大学开源的一个大语言模型。此前,发布的WizardLM和WizardCoder都是业界开源领域最强的大模型。其中,前者是针对指令优化的大模型,而后者则是针对编程优化的大模型。而此次WizardMath则是他们发布的第三个大模型系列,主要是针对数学推理优化的大模型。在GSM8K的评测上,WizardMath得分超过了ChatGPT-3.5、Claude Instant-1等闭源商业模型,得分十分逆天!
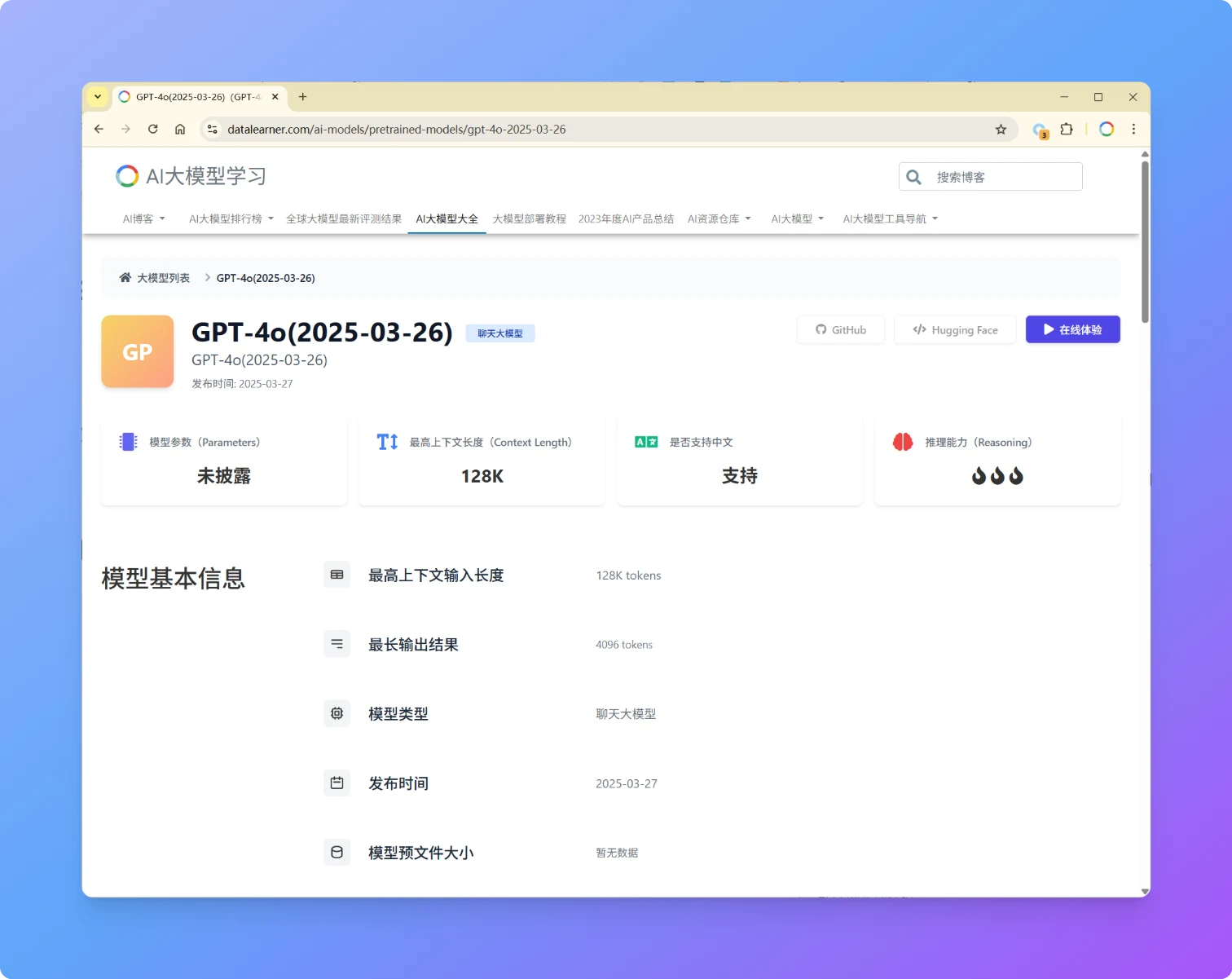
OpenAI再次发布GPT-4o更新版本,版本号为GPT-4o(2025-03-26),本次发布的GPT-4o模型在性能、易用性和协作能力上迎来多项优化,进一步提升了模型的直觉性、创造力和任务执行能力。此次更新聚焦于 STEM 与编程问题解决、指令遵循精度以及自然交互体验,各方面评测进步明显,超过了GPT-4.5。

吴恩达的DeepLearningAI在今天和LangChain的创始人一起合作发布了一个最新的基于LangChain使用LLM构建私有数据的问答系统和聊天机器人的课程(课程名:《LangChain: Chat with Your Data》)。LangChain是大语言模型应用开发领域目前最火的开源库。集成十分多的优秀特性,可以帮助我们非常简单构建LLM的应用。

DALL·E 系列是由 OpenAI 开发的一系列基于大型语言模型的文本到图像生成系统。它们的核心目标是将文本描述转化为高度精确的图像。DALL·E2在2022年4月发布,但是一直没有公开使用,一年半后的2023年9月21日,OpenAI发布第三代DALL·E3,并承诺将与ChatGPT集成。

几分钟之前,OpenAI宣布ChatGPT支持多模态,目前已经支持语音的输入、语音的输出、理解图片的输入!不过目前似乎仅限于客户端~官方说的是未来2周内企业和Plus用户可以使用,后面会普及到其它用户!
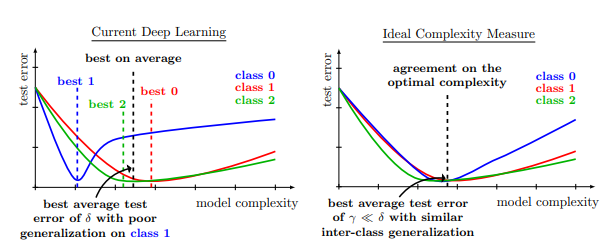
正则化是一种基本技术,通过限制模型的复杂性来防止过度拟合并提高泛化性能。目前的深度网络严重依赖正则化器,如数据增强(DA)或权重衰减,并采用结构风险最小化,即交叉验证,以选择最佳的正则化超参数。然而,正则化和数据增强对模型的影响也不一定总是好的。来自Meta AI研究人员最新的论文发现,正则化是否有效与类别高度相关。
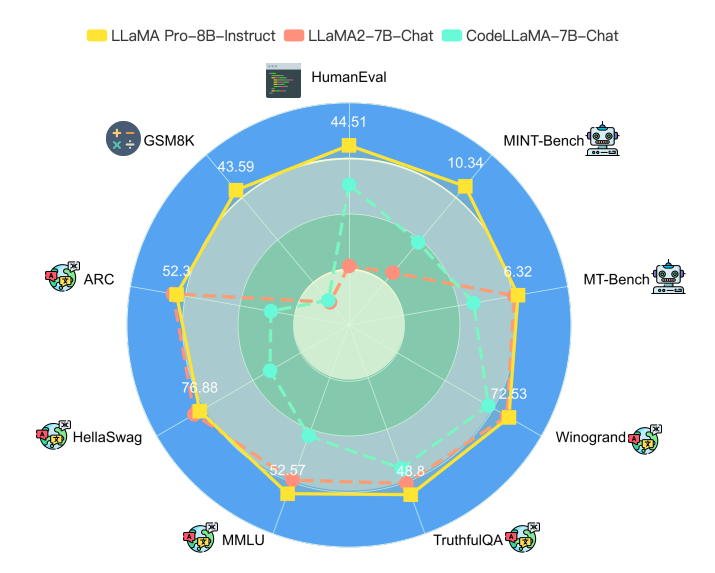
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。
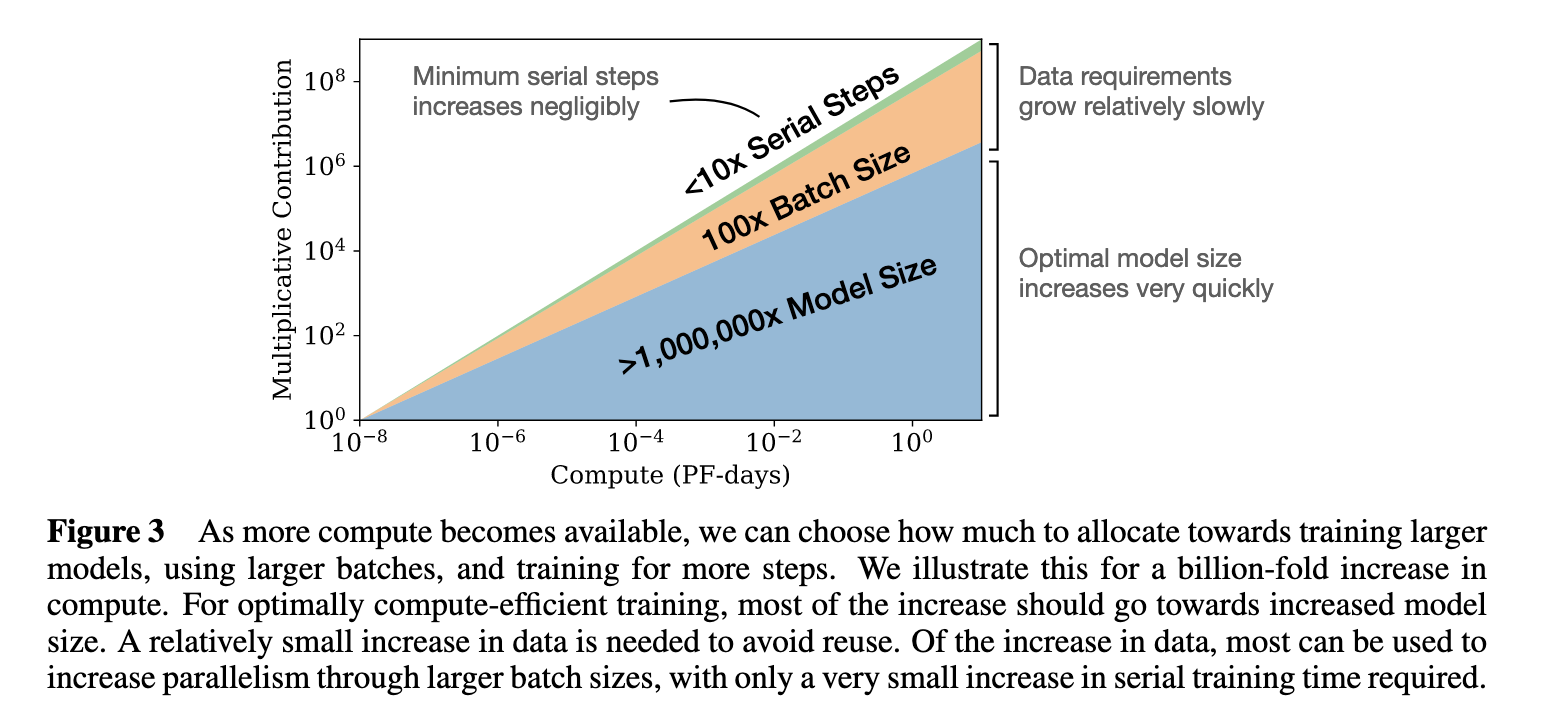
今晚已经是本周的最后一天了,最近的一些深度学习算法方面的进展做个总结吧,感觉都是挺不错的,供大家参考。
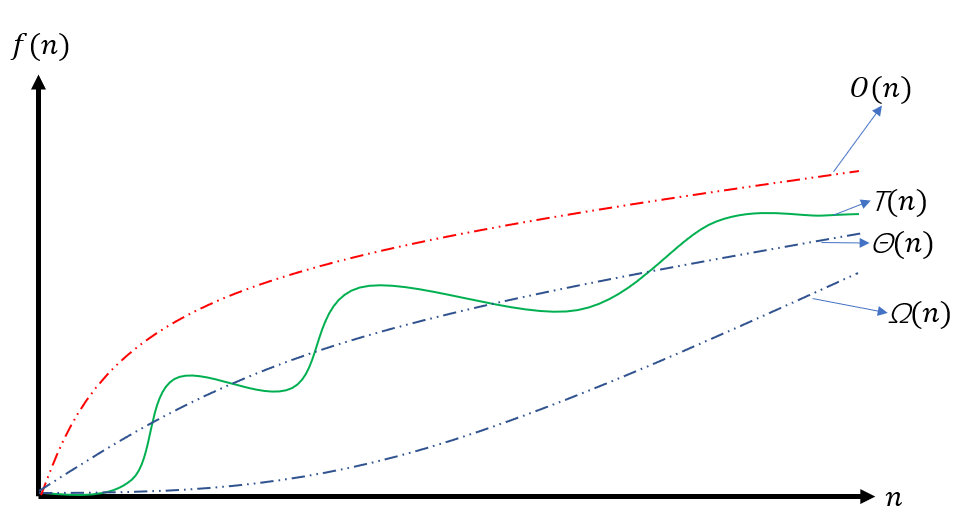
在程序设计和编程中,我们经常会看到关于时间复杂度的讨论。比如为什么A方法比B方法好?是因为A方法的时间复杂度低。那么,这里的时间复杂度如何去理解,又怎么计算呢?常见的O(n)的含义是什么?本文将简单的解释这个概念。
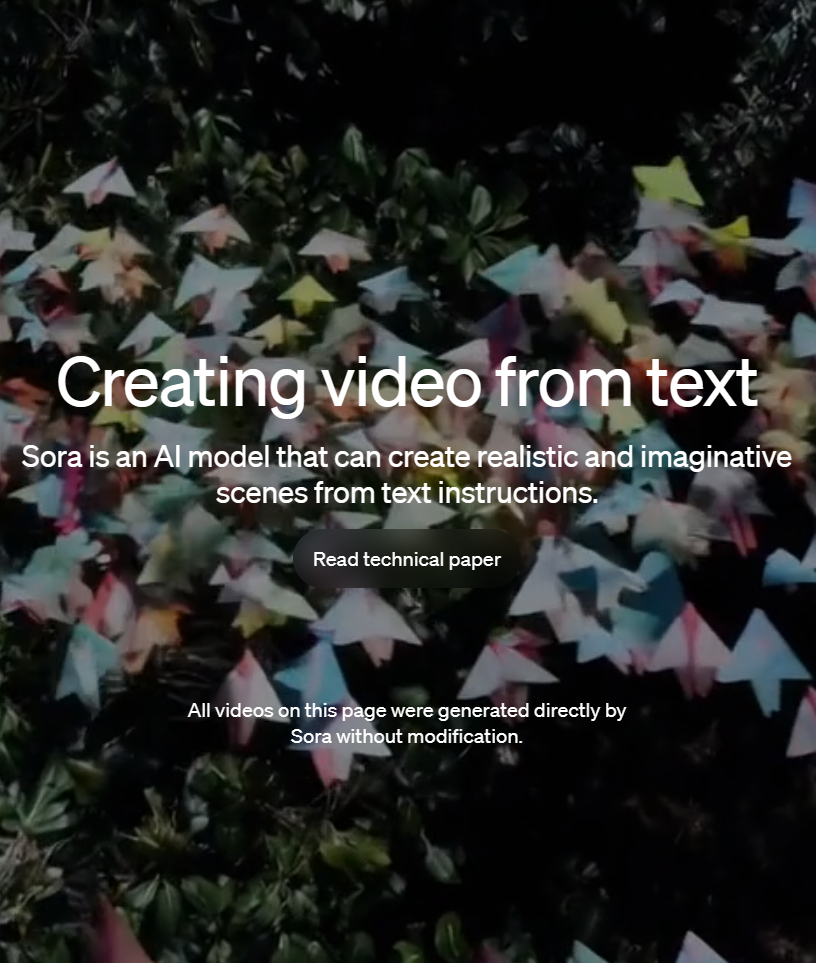
OpenAI宣布发布全新的Diffusion大模型Sora,这是一个可以生成最长60秒视频的视频生成大模型,最大的特点是可以生成非常逼真的电影画面版的视频。

刚刚,吴恩达宣布deeplearning.ai 与 Cohere 合作推出了一个新课程:“Large Language Models with Semantic Search”。这个课程主要教授大家如何使用LLMs进行语义搜索,还提供了大量实践经验,来克服搜索结果和准确性等挑战。
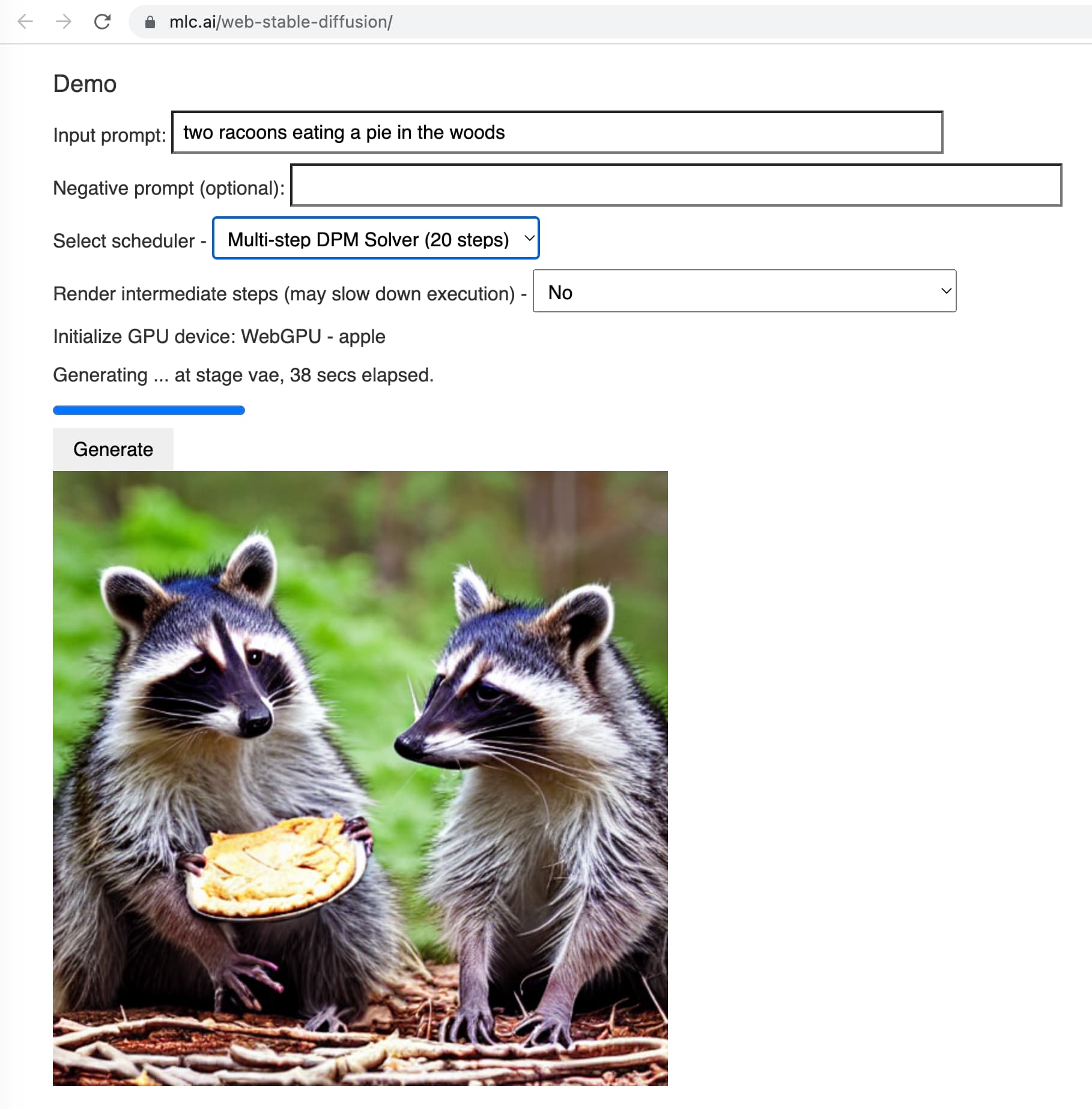
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!

OpenAI在GPT-4发布一年之后再次更新其基础模型,发布最新的GPT-4o模型,其中o代表的是omni,即“全能”的意思。GPT-4o相比较此前最大的升级是对多模态的支持以及性能的提升。GPT-4o在各方面比GPT-4更强,但是速度更快,开发者接口的价格则只有一半!
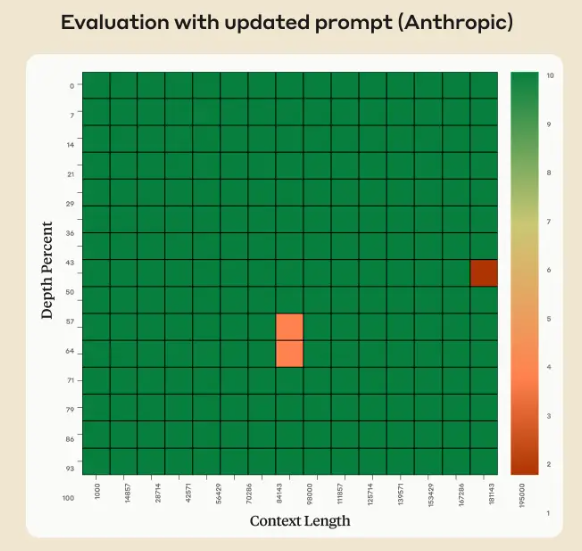
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。

Bloomberg在2022年4月开源了Memray,这是一个Python的内存分析器。它可以跟踪Python代码、本地扩展模块和Python解释器本身的内存分配情况。可以看numpy和pandas的运行内存使用。