
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



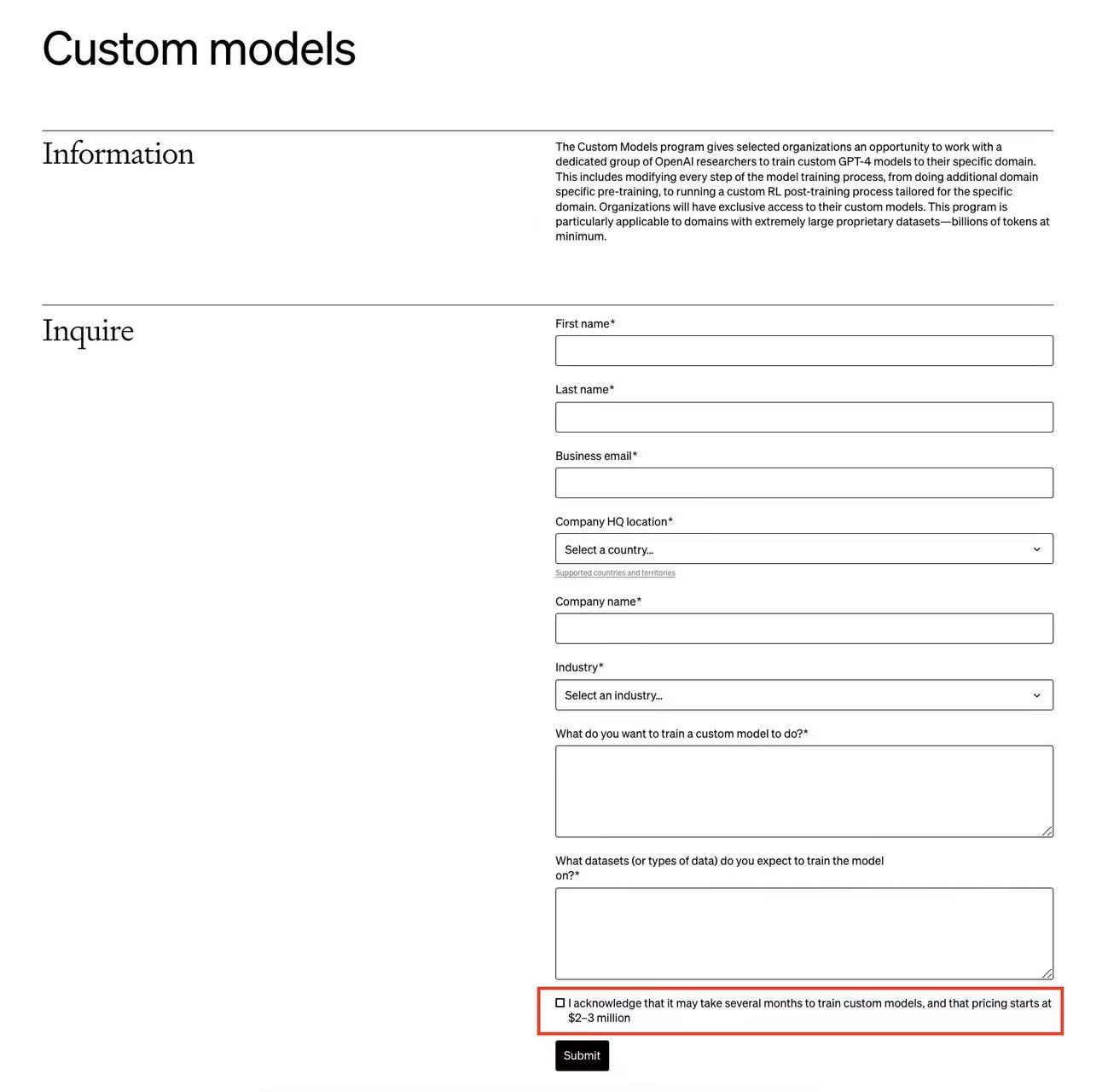
OpenAI的开发者日发布了许多更新。其中,普通用户可以微调GPT-4是非常值得期待的功能之一。但是,OpenAI还有一个针对企业的定制化GPT-4的训练服务,称为Custom Models。而这项为企业单独定制的GPT-4训练服务最新截图显示,需要几个月来训练模型,而且费用是200-300万美元起步!
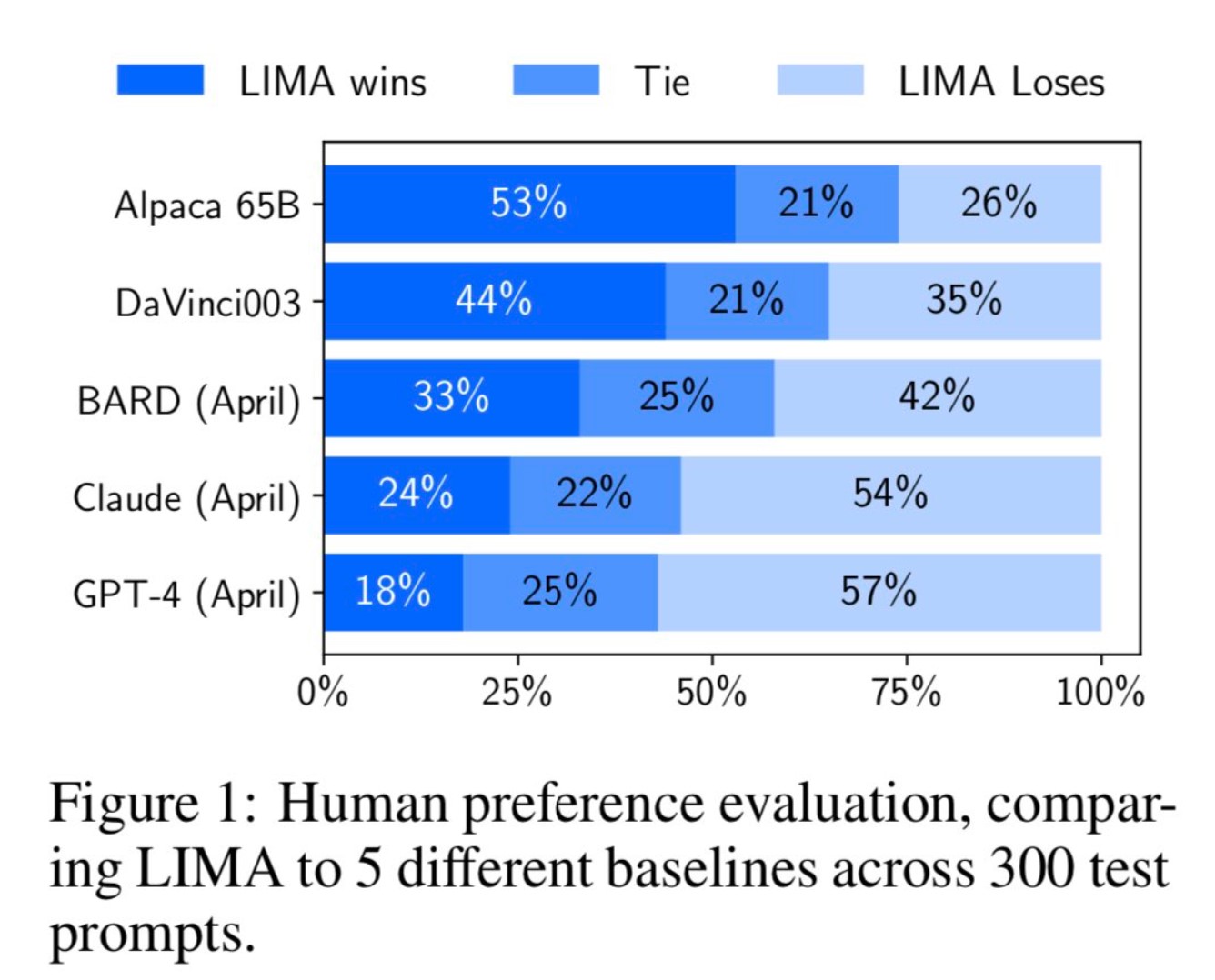
MetaAI最近公布了一个新的大语言模型预训练方法(LIMA: Less Is More for Alignment)。它最大的特点是不使用ChatGPT那样的(Reinforcement Learning from Human Feedback,RLHF)方法进行对齐训练。而是利用1000个精选的prompts与response来对模型进行微调,但却表现出了极其强大的性能。能够从训练数据中的少数几个示例中学习遵循特定的响应格式,包括从规划旅行行程到推测关于交替历史的复杂查询。

重磅福利,斯坦福大学在去年秋季开设了应该是全球第一个transformers相关的课程,授课人员来自OpenAI、Google Brain、Facebook人工智能实验室、DeepMind甚至是牛津大学的业界与学术界的一线大牛。而这两天,这门课相关视频也都公开了,大家可以去观看学习了!
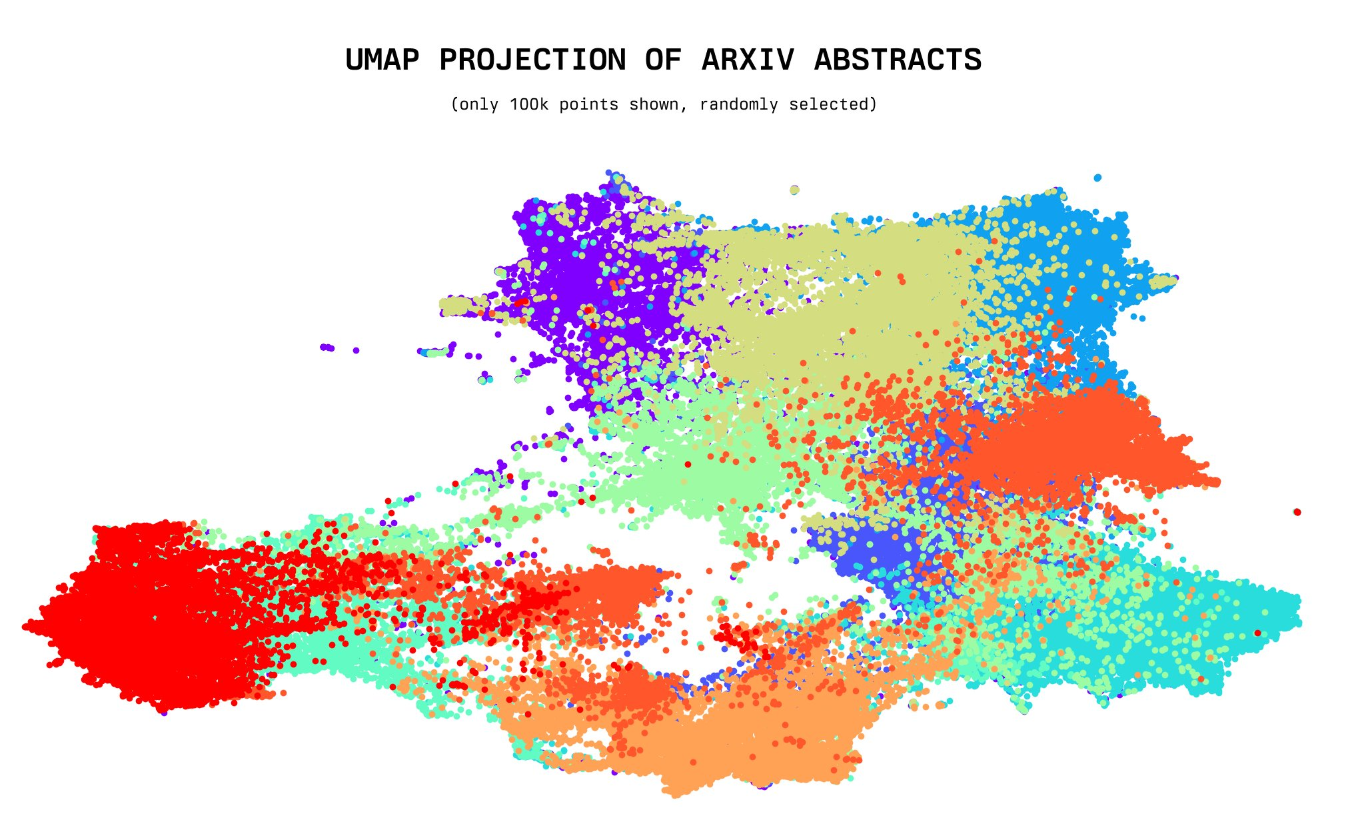
今天,一位年仅20岁的小哥willdepue 开源了230万arXiv论文的标题和摘要的embedding向量数据集,完全开源。该数据集包含截止2023年5月4日的所有arXiv上的论文标题和摘要的embedding结果,使用的是开源的Instructor XL抽取。未来将开放更多其它相关数据的embedding结果

2023年3月23日OpenAI官方宣布ChatGPT即将支持Plugin模式。这是一种用插件的方式来解锁ChatGPT的能力,包括让ChatGPT可以浏览网页、从本地商店订购食材等。今天,沃顿商学院教授Ethan Mollick在推特上公布了自己收到了ChatGPT内测邀请,并使用它的代码解释器(Python Interpreter)插件让ChatGPT针对一份excel数据完成了非常专业的数据分析的工作。
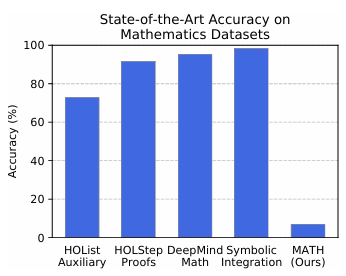
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。

文本embedding是当前大模型应用中一个十分重要的角色。在长上下文支持、私有数据问答等方面有非常重要的应用。但是相比较开源领域快速发布的大模型节奏,开源的embedding模型和数据却非常少。今天,GPT4All宣布在其软件中增加embedding的支持,这是一个完全免费且可商用的产品,最重要的是可以在我们本地用CPU来做推理。
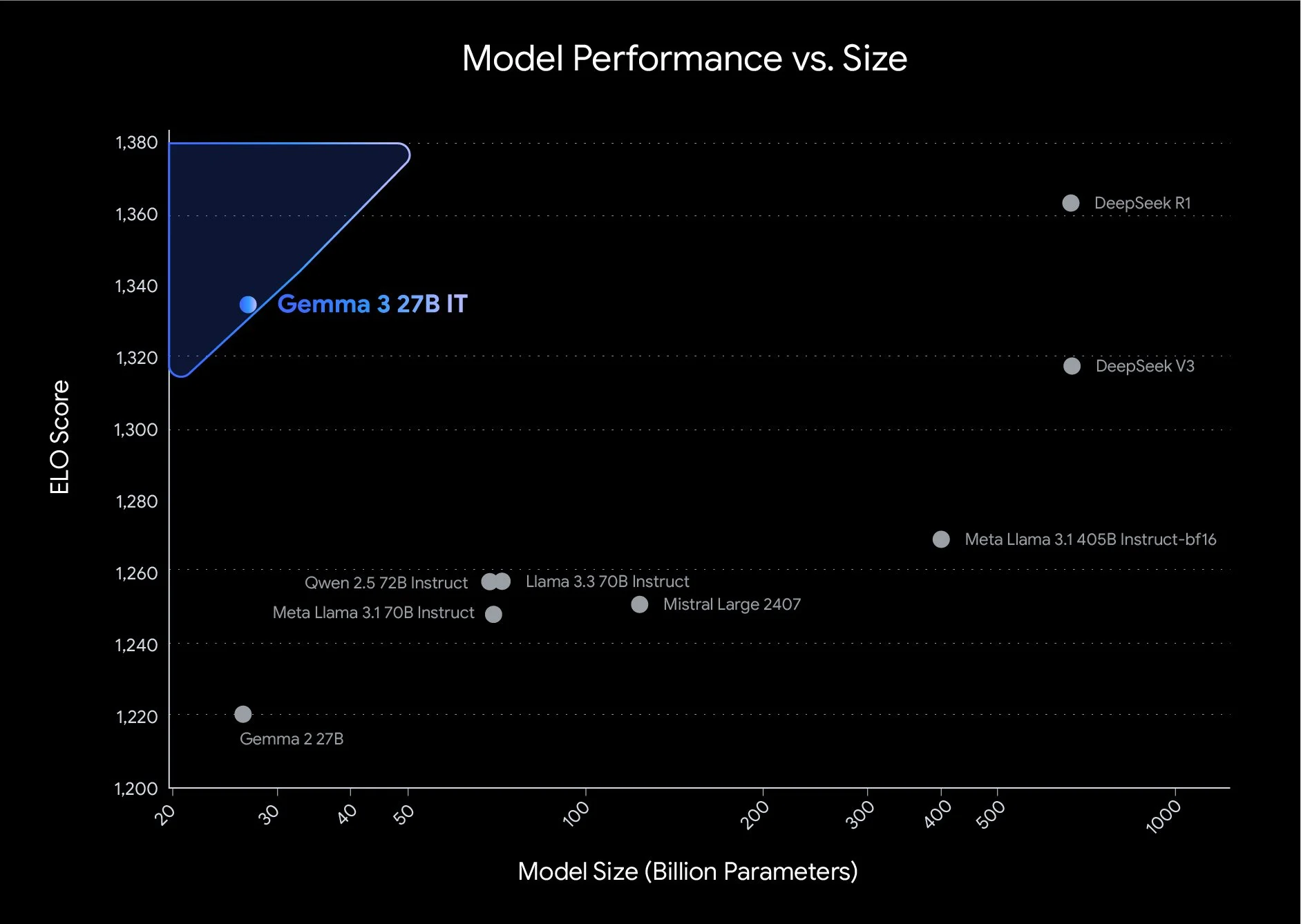
Gemma系列大模型是Google开源的一系列轻量级的大模型。就在刚才(2025年3月12日),Google开源了第三代Gemma系列大模型,共包含4个不同参数规模版本,第三代的Gemma 3系列是多模态大模型,即使是最小的10亿参数规模的Gemma 3-1B也支持多模态输入。
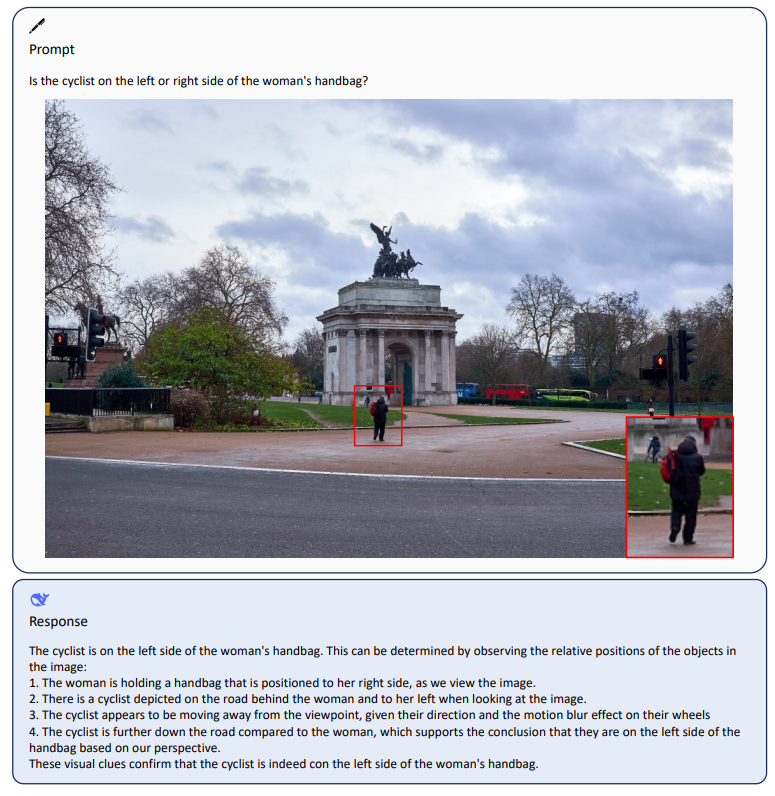
深度求索是著名量化机构幻方量化旗下的一家大模型初创企业,成立与2023年7月份。他们开源了很多大模型,其中编程大模型DeepSeek-Coder系列获得了非常多的好评。而在今天,DeepSeek-AI再次开源了全新的多模态大模型DeepSeek-VL系列,包含70亿和13亿两种不同规模的4个版本的模型。
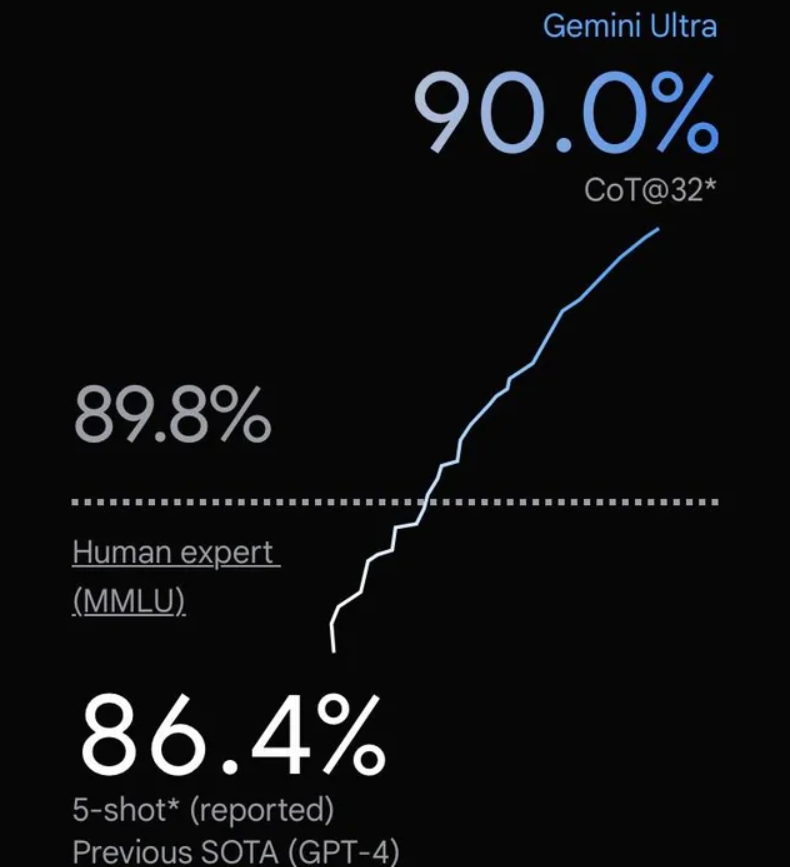
谷歌在几个小时前发布了Gemini大模型,号称历史最强的大模型。这是一系列的多模态的大模型,在各项评分中超过了GPT-4V,可能是目前最强的模型。
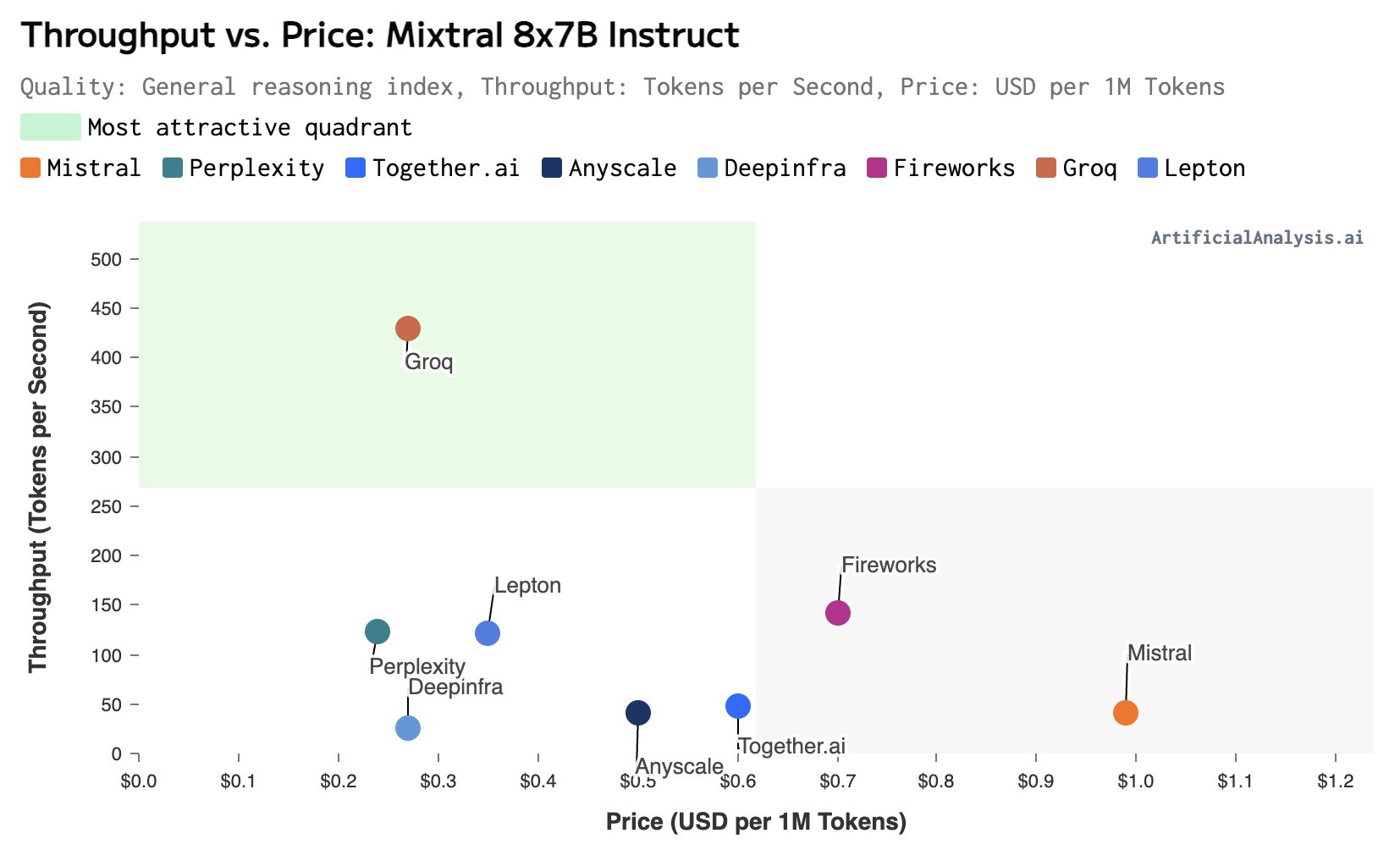
大模型的推理速度是当前制约大模型应用的一个非常重要的问题。在很多的应用场景中(如复杂的接口调用、很多信息处理)的场景,更快的大模型响应速度通常意味着更好的体验。但是,在实际中我们可用的场景下,大多数大语言模型的推理速度都非常有限。慢的有每秒30个tokens,快的一般也不会超过每秒100个tokens。而最近,美国加州一家企业Groq推出了他们的大模型服务,可以达到每秒接近500个tokens的响应速度,非常震撼。
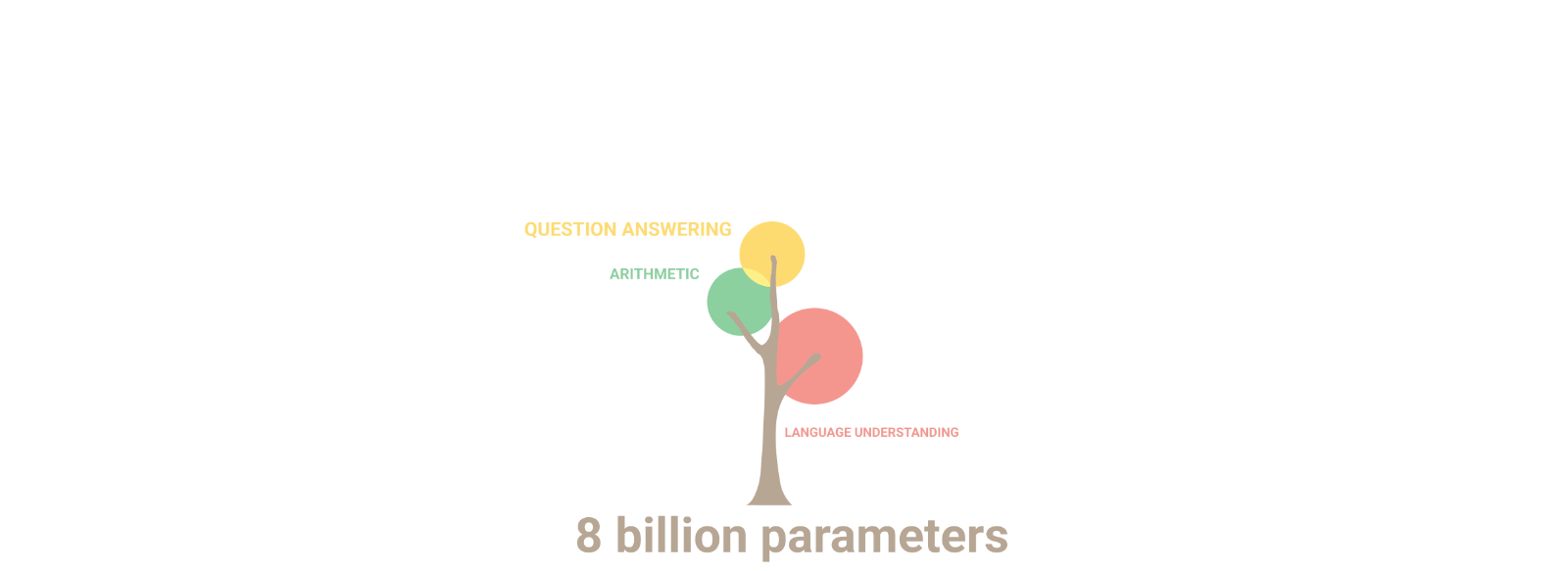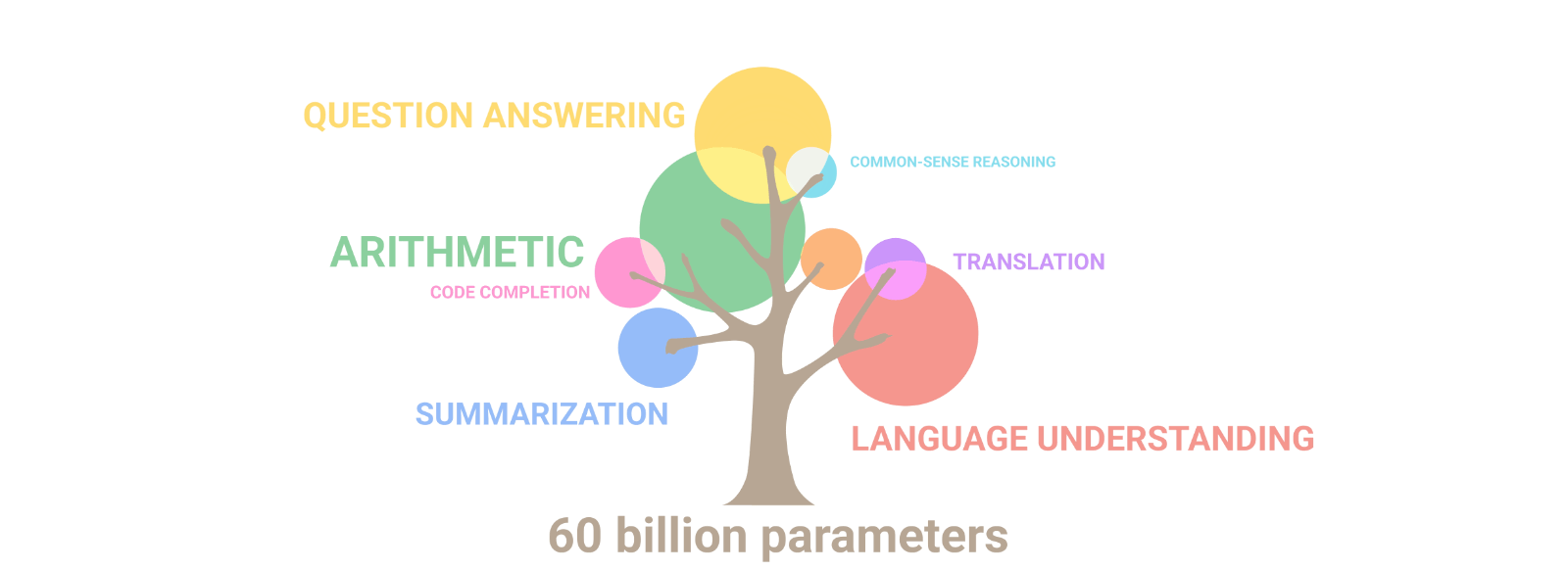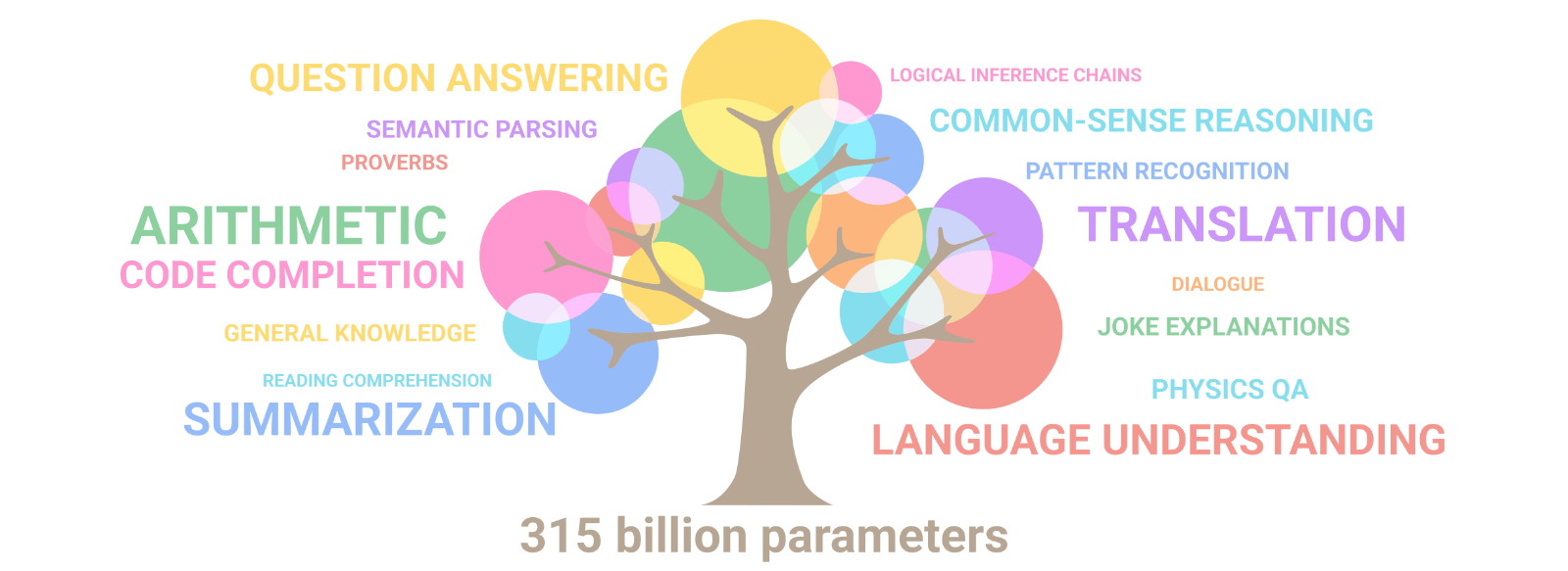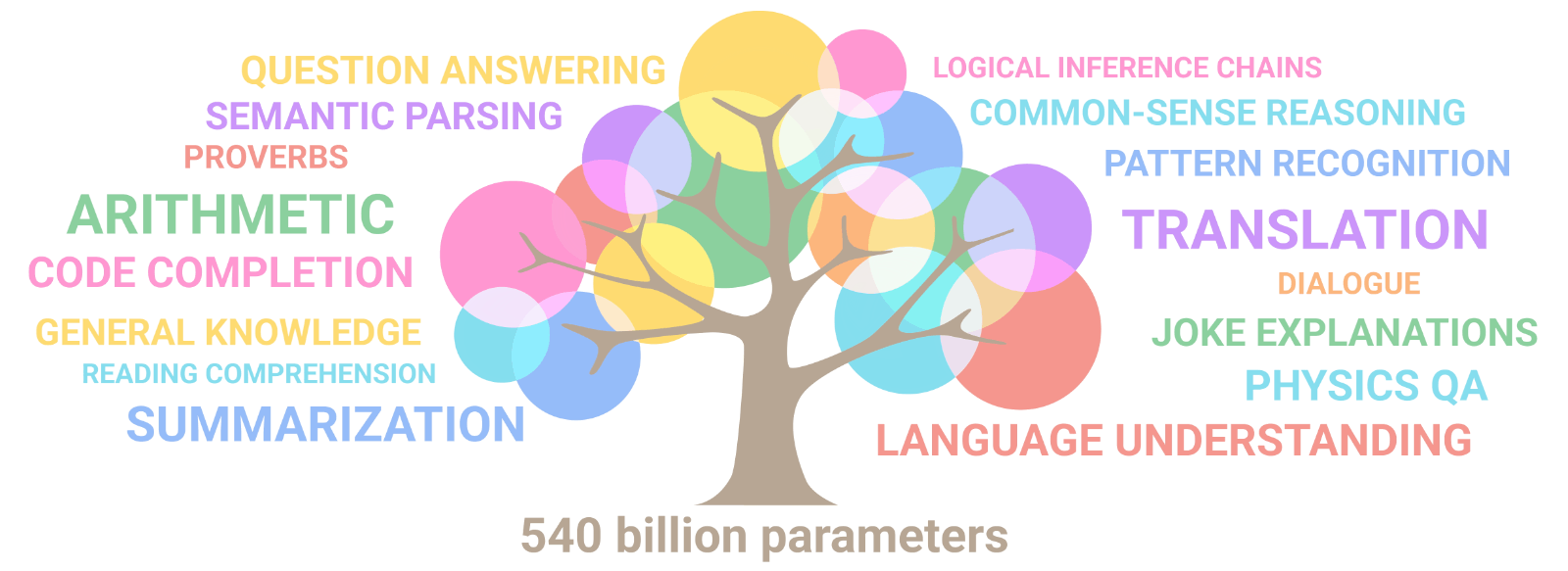
今天,Google介绍了一个新的语言模型,一个Pathways语言模型:PaLM,这是一个用Pathways系统训练的5400亿个参数、仅有dense decoder的Transformer模型,在数百个语言理解和生成任务上对PaLM进行了评估,发现它在大多数任务中实现了最先进的性能,在许多情况下都有显著的优势。
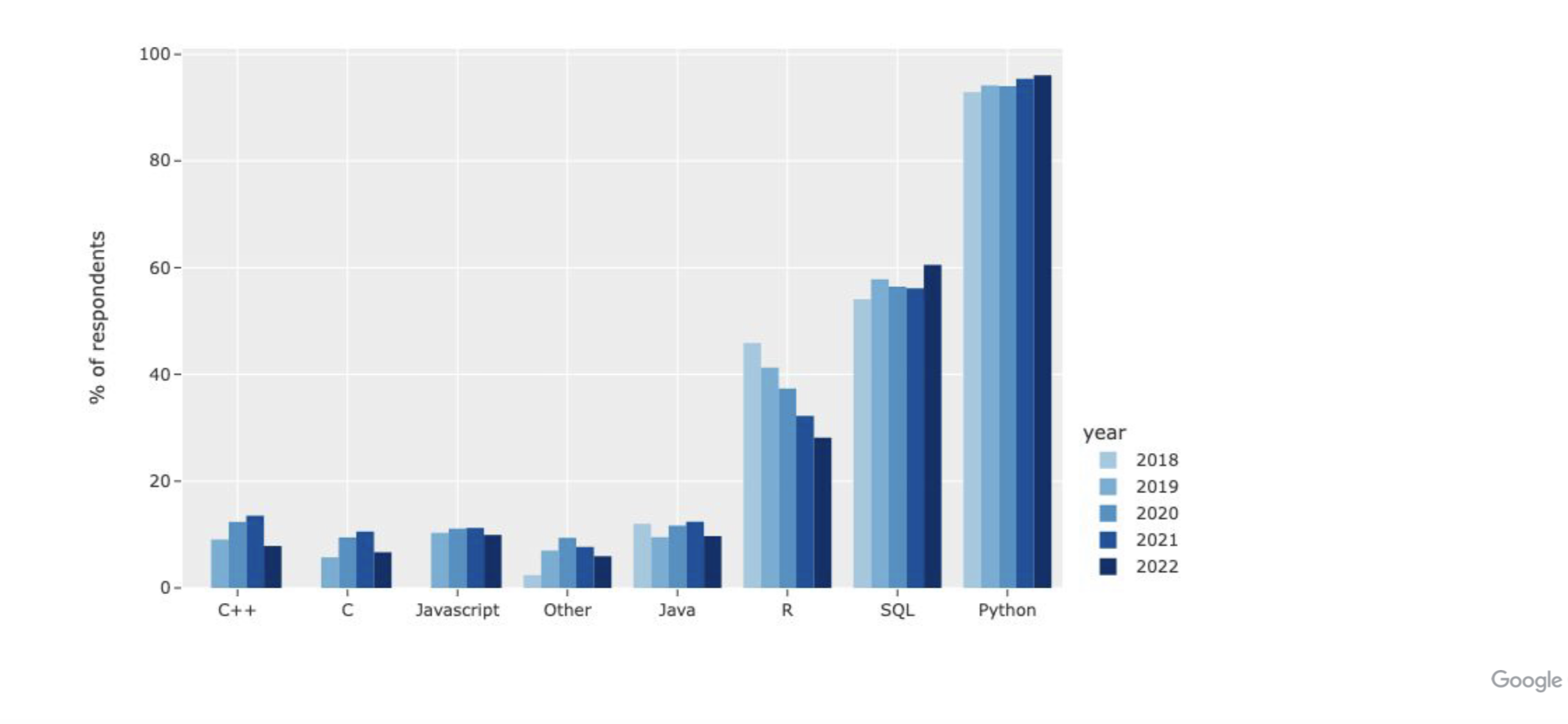
kaggle是各类机器学习竞赛的著名平台,上面聚集了大量的机器学习比赛和数据集,也有大量的数据处理相关专业人员。每年官方都会向平台用户发放问卷,调查数据科学家的工具使用和平台采用情况。今年的调查结果也在两天前发出,有很多有意思的结论。

XVERSE-13B是元象开源的一个大语言模型,发布一周后就登顶HuggingFace流行趋势榜。该模型最大的特点是支持多语言,其中文和英文水平都十分优异,在评测结果上超过了Baichuan-13B,与ChatGLM2-12B差不多,不过ChatGLM2-12B是收费模型,而XVERSE-13B是免费商用授权!