
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




2022年11月底发布的ChatGPT是基于OpenAI的GPT-3优化得到的可以进行对话的一个产品。直到今年更新到3.5和4之后,官方分为两个产品服务,其中ChatGPT 3.5是基于gpt-3.5-turbo打造,免费试用。因此,几乎所有人都自然认为这是一个与GPT-3具有同等规模参数的大模型,也就是说有1750亿参数规模。但是,在10月26日微软公布的CodeFusion论文的对比中,大家发现,微软的表格里面写的ChatGPT 3.5只有200亿参数规模。
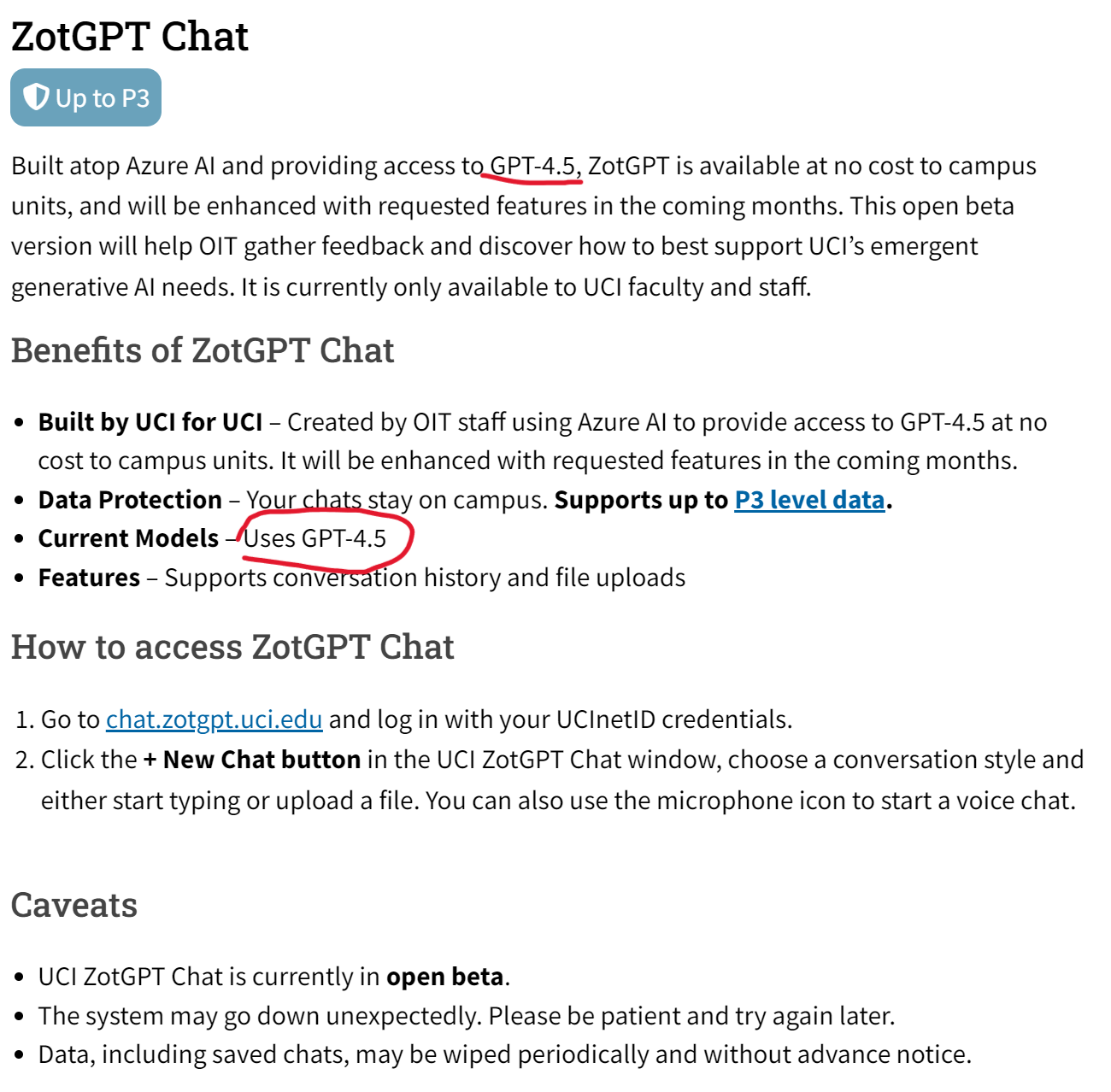
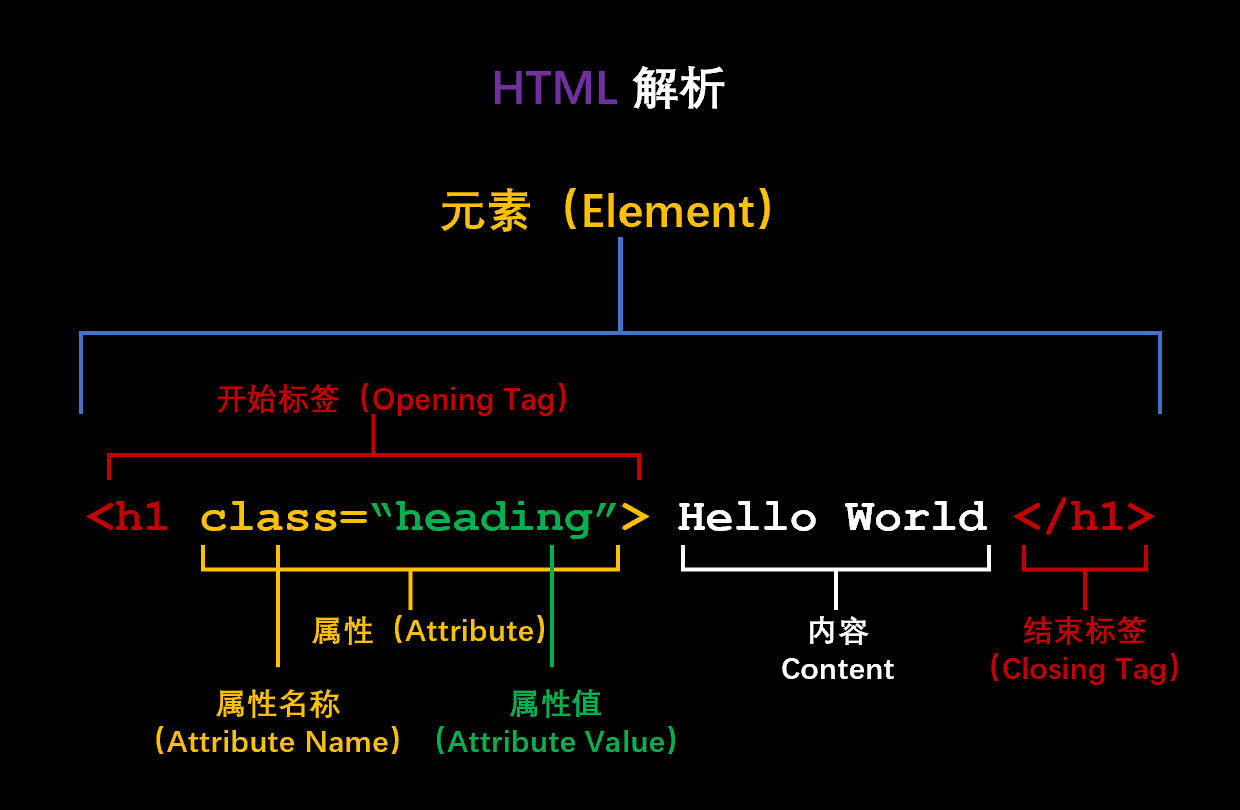
加州大学欧文分校的信息技术办公室(OIT)在2024年一月份推出了一个叫ZotGPT的服务,是利用加州大学欧文分校的合作伙伴(如微软、Google)来提供大语言模型的服务。就是说用一个ZotGPT服务来接入不同服务商提供的大模型,如Gemini、GPT等。目前包含ZotGPT Chat、Copilot和Gemini三大服务,其中最新的ZotGPT Chat服务介绍页面显示,他们现在已经提供GPT-4.5的服务!
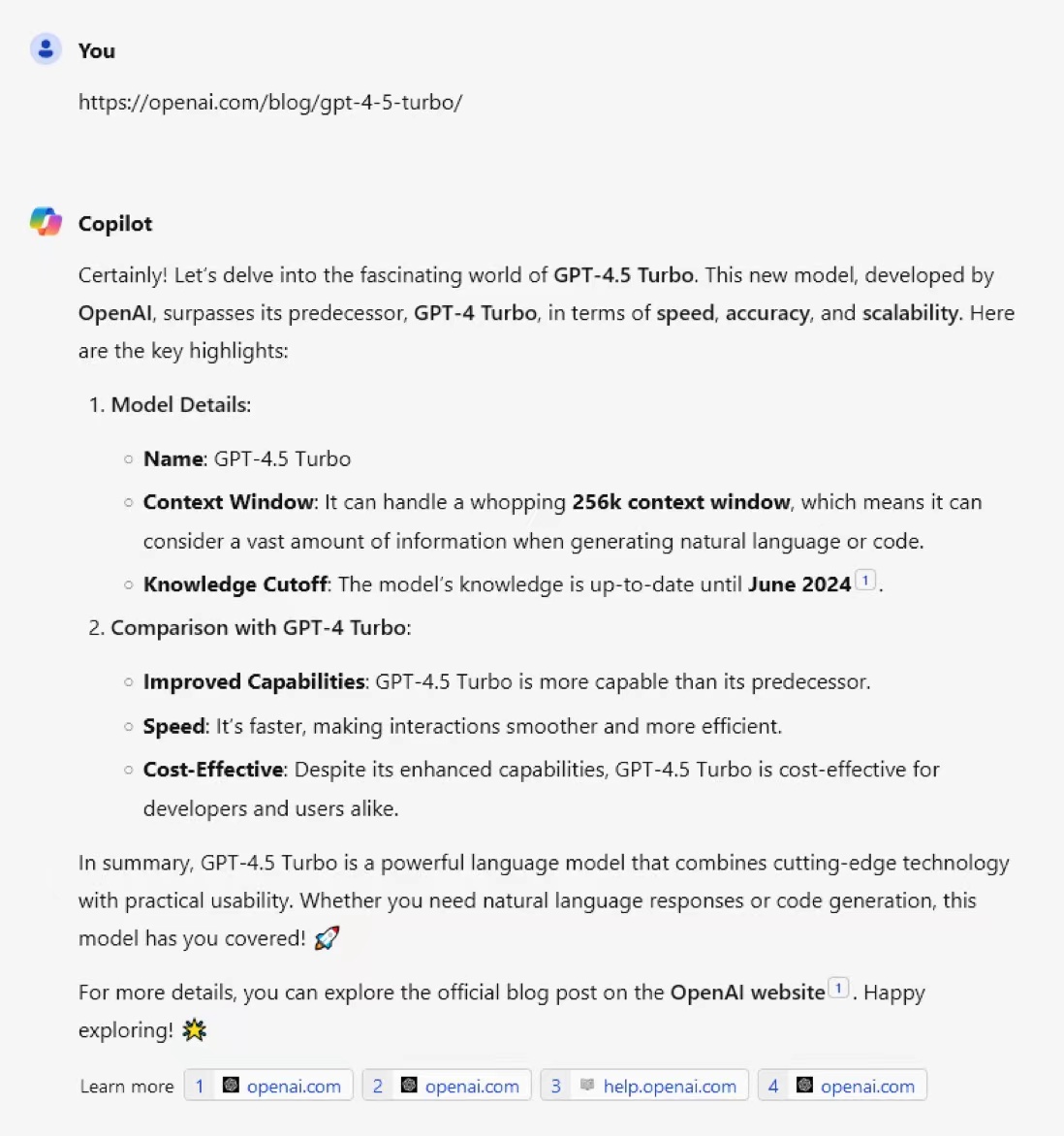
尽管GPT-4.5的传闻一直存在,但是没有任何地方透露过相关的消息。而最新的OpenAI官网似乎已经悄悄上架了GPT-4.5-Turbo的信息。尽管目前网页被删除,但是Bing检索保留了相关缓存并可以在Bing Chat中回答。

MetaAI在2023年8月31日开源了一个全新的图像数据集,FACET(FAirness in Computer Vision EvaluaTion),FACET数据集包含32,000张图片和50,000人,这些图片由专家进行了详细的标注,包括人口统计属性(如感知性别表达和感知年龄组)和其他物理属性(如感知肤色和发型)。这样的设计使得研究人员可以更全面、更深入地评估模型在不同人群中的表现,从而更准确地识别和解决模型的不公平性问题。
OpenAI的o1模型被认为是大模型领域中推理能力最强的代表之一,由于其强大的数学逻辑推理能力,被认为是大模型未来的进化方向。而就在2个月之后的11月快结束的时间里,幻方量化旗下人工智能企业DeepSeekAI发布了全新的DeepSeek-R1-Lite-Preview模型,号称是o1模型的有力挑战者。该模型利用了类似的o1的思维链思索过程,推理能力大幅增强。DataLearnerAI将在本文中对该模型进行介绍,并进行几个简单的对比结果测试。结果证明这个模型是非常优秀的!
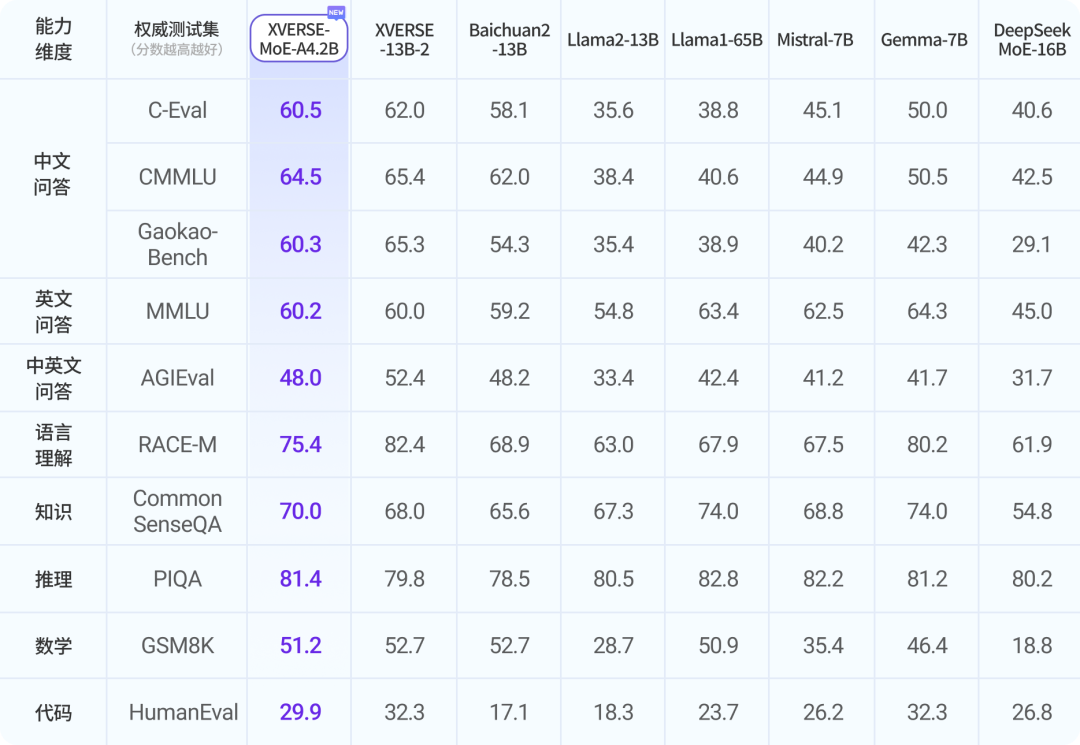
混合专家架构大模型是当前最火热的一个大模型技术发展方向。三月底,业界开源了多个混合专家大模型,包括DBRX、Qwen1.5-MoE-A2.7B等。而在四月初,又一家国产大模型企业开源了一个全新的MoE架构的模型,即深圳元象科技XVERSE开源的XVERSE-MoE-A4.2B。该模型参数256亿,推理时仅激活42亿参数,效果与当前主流的130亿参数的规模差不多。
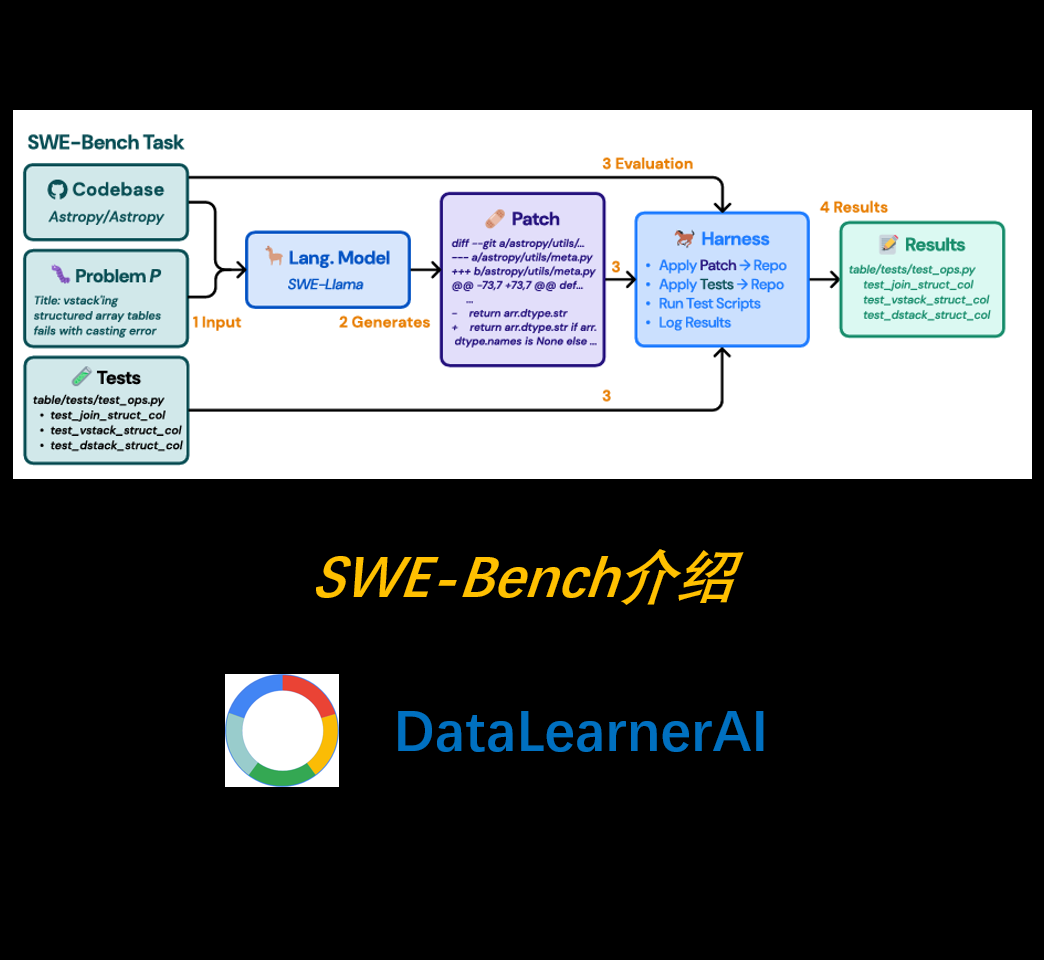
随着大语言模型(LLM)的快速发展,它们在自然语言处理(NLP)、代码生成等领域的表现已达到前所未有的高度。然而,现有的代码评测基准(如 HumanEval)通常侧重于**自包含的、较短的代码生成任务**,而未能充分模拟真实世界的软件开发环境。为弥补这一空白,研究者提出了一种全新的评测基准——**SWE-Bench**,旨在测试 LLM 在**真实软件工程问题**中的能力。
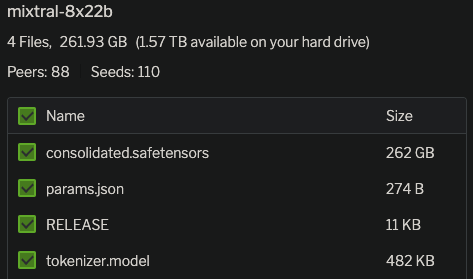
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。
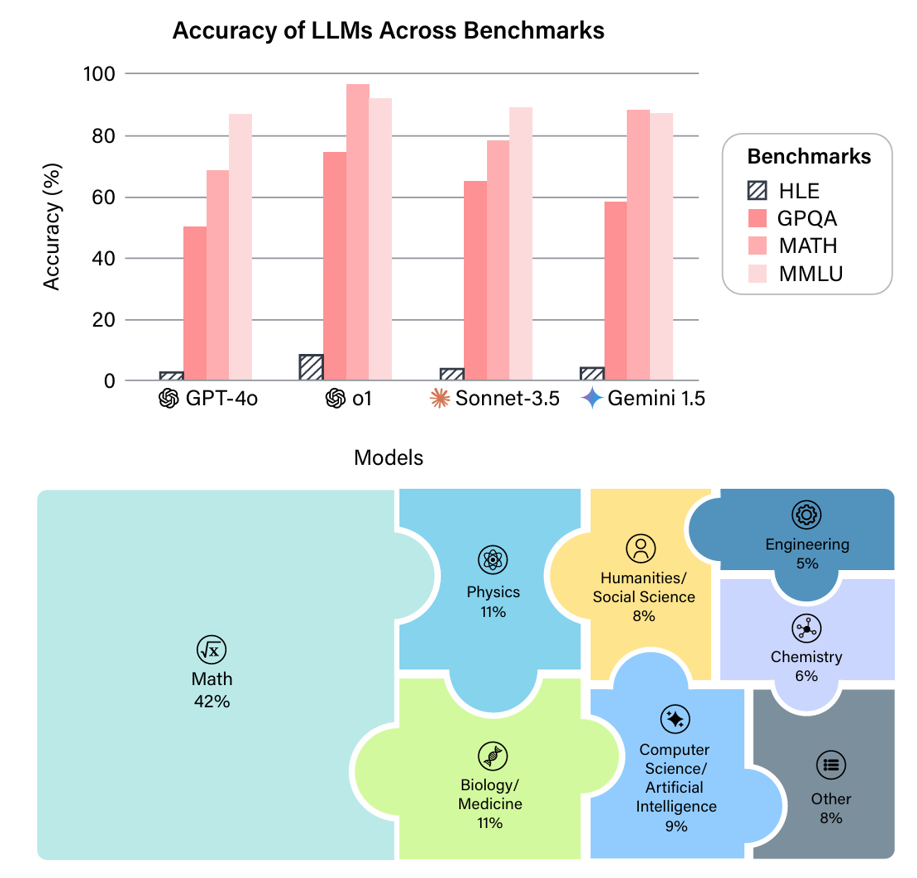
近年来,大语言模型(LLM)的能力飞速提升,但评测基准的发展却显得滞后。以广泛使用的MMLU(大规模多任务语言理解)为例,GPT-4、Claude等前沿模型已能在其90%以上的问题上取得高分。这种“评测饱和”现象导致研究者难以精准衡量模型在尖端知识领域的真实能力。为此,Safety for AI和Scale AI的研究人员推出了Humanity’s Last Exam大模型评测基准。这是一个全新的评测基准,旨在成为大模型“闭卷学术评测的终极考验”。
Qwen2.5-Omni-7B是阿里巴巴发布的一款端到端全模态大模型,支持文本、图像、音频、视频(无音频轨)的多模态输入与实时生成能力,可同步输出文本与自然语音的流式响应。目前,该模型在HuggingFace以Apache2.0协议开源,可以免费商用授权。

网络流传了一张疑似GPT-4.5的定价截图,引爆了很多人的讨论。但是,目前没有人可以确定真假。

在人工智能快速发展的今天,创新型模型如Mixtral 8x7B的出现,不仅推动了技术的进步,还为未来的AI应用开辟了新的可能性。这款基于Sparse Mixture of Experts(SMoE)架构的模型,不仅在技术层面上实现了创新,还在实际应用中展示了卓越的性能。尽管一个月前这个模型就发布,但是MistralAI今天才上传了这个模型的论文,我们可以看到更详细的信息。

OpenAI的CEO Sam最近参加了世界经济论坛,发表了几场演讲。有网友听了完整的Sam的4-5场演讲,并从中抽取了Sam关于GPT-5相关的论述。从中我们可以看到未来GPT-5可能的样子。这里为大家总结翻译一下。

在近年来,随着人工智能技术的飞速发展,大型语言模型(LLM)在代码生成和编辑领域的应用越来越广泛,成为软件开发中不可或缺的助手。今天,我想向大家介绍一个由BigCode项目与Software Heritage合作开发的下一代代码大型语言模型——StarCoder 2。
今日推荐
Transformer蓝图:Transformer 神经网络架构的综合指南——万字长文、20多个图片介绍大语言模型主流架构Transformer的发展历史、现状和未来结果
LM-SYS开源包含人类偏好的3.3万条真实对话语料:可用于RLHF的训练过程!
Stable Diffusion的最新实现——KerasCV的官方实现!
ChatGPT即将发布的新版本:增加自动标签管理并去除对ChatGPT回答的点赞按钮
抛弃RLHF?MetaAI发布最新大语言模型训练方法:LIMA——仅使用Prompts-Response来微调大模型
OpenAI发布最新最强大的AI对话系统——GPT3.5微调的产物ChatGPT
Dirichlet Process and Stick-Breaking(DP的Stick-breaking 构造)
二叉查找树(Binary Search Trees,BST)数据结构详解
OpenAI发布企业使用的ChatGPT:没有限制且更快的GPT-4、数据隔离、基于GPT-4的高级数据分析功能,但是暂不支持私有化部署