原创博客
原创AI技术博客
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
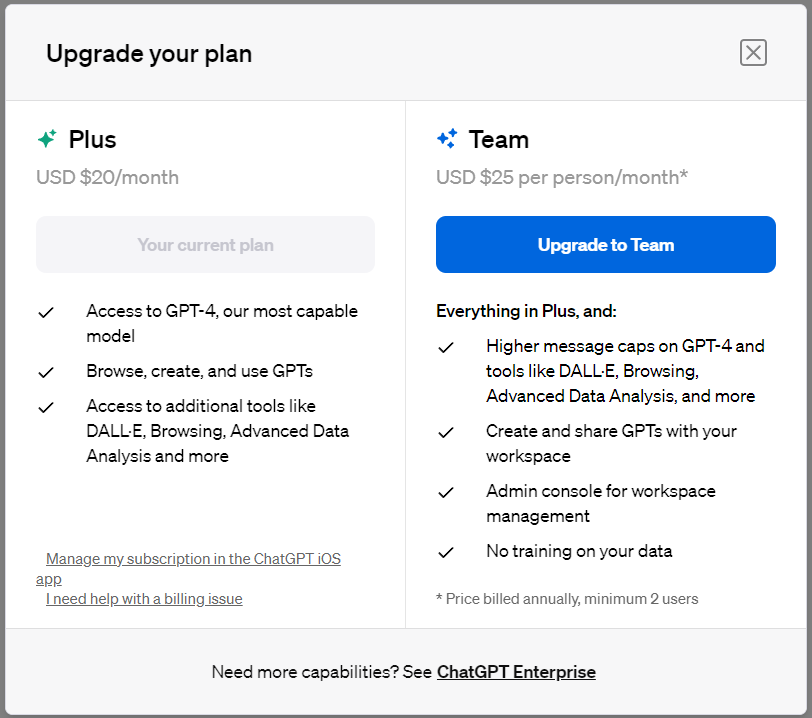
OpenAI正式开放ChatGPT Team订阅计划,价格每个月贵25%,更多的GPT-4,附ChatGPT付费计划对比
OpenAI今天开放了ChatGPT的Team版本的订阅计划,相比较普通的Plus会员版本,Team版本的计划价格更贵,但是可以使用更多的GPT-4额度。不过,与此前传闻比较少了很多功能,唯一比较吸引人的就是更多的GPT-4使用额度了。最少两个人合买。
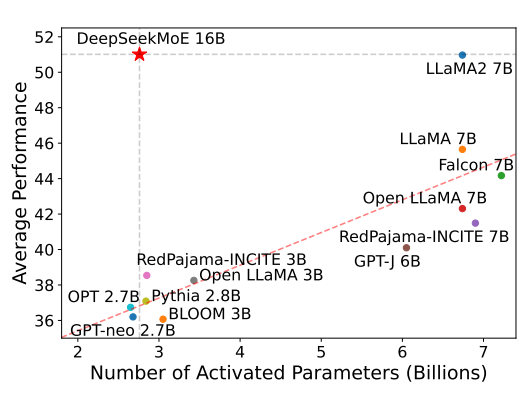
DeepSeekAI开源国产第一个基于混合专家技术的大模型:DeepSeekMoE-16B,未来还有1450亿参数的MoE大模型
混合专家(Mixture of Experts)是大模型一种技术,这个技术将大模型划分为不同的子专家模型,每次推理只选择部分专家网络进行推理,在降低成本的同时保证模型的效果。此前Mistral开源的Mixtral-8×7B-MoE大模型被证明效果很好,推理速度很棒。而幻方量化旗下的DeepSeek刚刚开源了可能是国产第一个MoE技术的大模型,DeepSeek-MoE 16B。
Dask分布式任务中包含写文件的方法时候,程序挂起不结束的解决方案
使用Dask进行分布式处理的时候一个最常见的场景是有很多个文件,每个文件由一个进程处理。这种操作经常会遇到一个程序挂起的问题,使得程序永远运行,无法结束。本文描述如何解决。

MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
MistralAI是一家法国的大模型初创企业,其2023年9月份发布的Mistral-7B模型声称是70亿参数规模模型中最强大的模型,并且由于其商用友好的开源协议,吸引了很多的关注。在昨晚,MistralAI突然在推特上公布了一个磁力下载链接,而下载之后大家发现这是一个基于混合专家的大模型这是由8个70亿参数规模专家网络组成的混合模型(Mixture of Experts,MoE,混合专家网络)。

吴恩达的LandingAI究竟是一家什么样的创业公司
吴恩达是人工智能领域非常著名的人物。2011年在谷歌创建的谷歌大脑项目,震惊了全世界。2014年他加入百度负责百度大脑计划,并于2017年离职。离职之后他创建了人工智能公司LandingAI,并担任首席执行官。昨天吴恩达宣布他新成立的这家公司已经募集到5,700万美金。本文主要简单介绍这家公司的业务。



目前正在举办的机器学习相关的比赛
机器学习相关的竞赛为大家学习使用算法提供了一个非常好的平台和机会。既能检验大家学习的算法的实际应用情况,也可以帮助我们学习到很多有用的技巧。很多竞赛也都产生了优秀的算法思想与经验。所以积极参加比赛是一种非常重要的学习方式。本文总结目前正在举办的比赛,各位可以根据自己的情况参与。
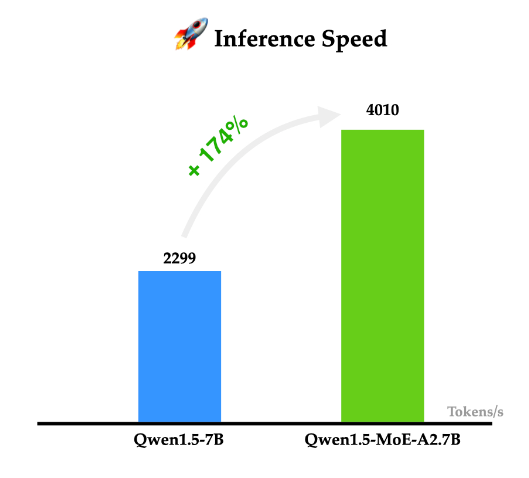
重磅!阿里巴巴开源自家首个MoE技术大模型:Qwen1.5-MoE-A2.7B,性能约等于70亿参数规模的大模型Mistral-7B
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。

Hugging Face发布最新的深度学习模型评估库Evaluate!
就在儿童节前一天,Hugging Face发布了一个最新的深度学习模型评估库Evaluate。对于机器学习模型而言,评估是最重要的一个方面。但是Hugging Face认为当前模型评估方面非常分散且没有很好的文档。导致评估十分困难。因此,Hugging Face发布了这样一个Python的库,用以简化大家评估的步骤与时间。

为什么GitHub要求文件的末尾必须有换行符?
这几天逛reddit的时候发现了一个很有意思的讨论,有个童鞋说他在GitHub上提交代码的时候发现了提交文件被提示有一个红色警告的提示,鼠标移动上去会告诉你“No newline at end of file”(也就是文件末尾没有换行)。因此,他很奇怪,他不懂为什么GitHub要求文件的末尾必须有换行符。这个问题引起了很多的讨论。这里我也顺便记录共享一下。
Google发布面试辅助工具Interview Warmup帮助我们理解谷歌面试内容
最近,谷歌发布了一项新的工具:Google Interview Warmup,让你练习回答由行业专家选定的问题,并使用机器学习来转录你的答案,帮助你发现改进面试的回答。

OpenAI CEO详解今明两年GPT发展计划:10万美元部署私有ChatGPT、最高支持100万tokens、建立微调模型应用市场
前段时间,OpenAI的CEO Sam Altman与二十多位开发者一起聊了很多关于OpenAI的API和产品的规划问题。Sam Altman透露了一些非常重要的OpenAI的发展方向,包括GPT产品功能的未来规划等。目前这份原始博客内容已经应OpenAI的要求被删除,这里我们简单总结一下这些内容。
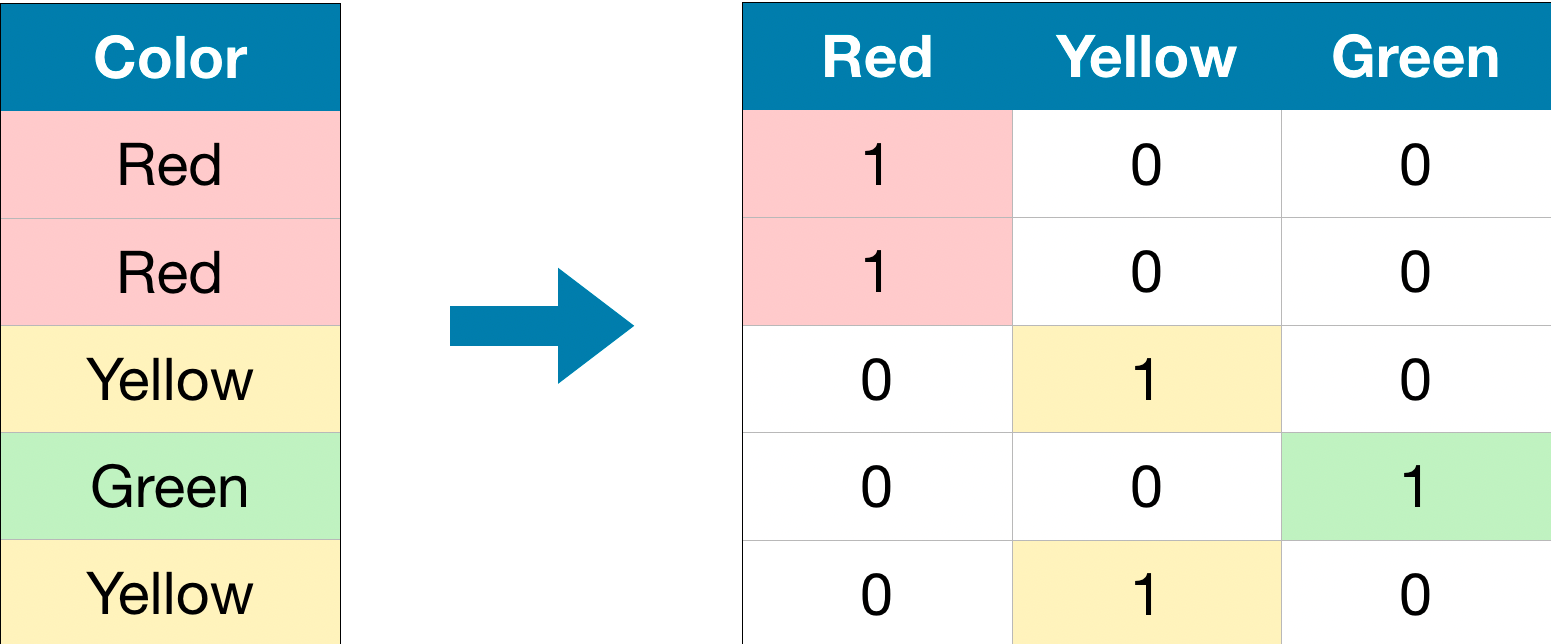
使用kaggle房价预测的实例说明预测算法中OneHotEncoder、LabelEncoder与OrdinalEncoder的使用及其差异
对于分类特征的处理,sklearn中常见的方法有两种,一种是OneHotEncoder,另一种很多人说是LabelEncoder,其实不对。sklearn中,还有一个OrdinalEncoder,二者似乎一样,但其实并不相同,差别很大。本文将用Kaggle的房价预测的实例来描述如何这些差异以及不同处理对预测算法的影响。

Python for Data Analysis第三版免费在线学习网站来临!
《Python for Data Analysis: Data Wrangling with pandas, NumPy, and Jupyter》是由Wes McKinney撰写的Python数据分析专业工具书籍。很容易理解,这本书就是教大家如何使用Pandas、NumPy以及Jupyter分析数据的。

如何训练你自己的大语言模型?——来自Replit一线工程师的亲身经验
本文是Replit工程师发表的训练自己的大语言模型的过程的经验和步骤总结。Replit是一家IDE提供商,它们训练LLM的主要目的是解决编程过程的问题。Replit在训练自己的大语言模型时候使用了Databricks、Hugging Face和MosaicML等提供的技术栈。这篇文章提供的都是一线的实际经验,适合ML/AI架构师以及算法工程师学习。