
原创博客
原创AI技术博客
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
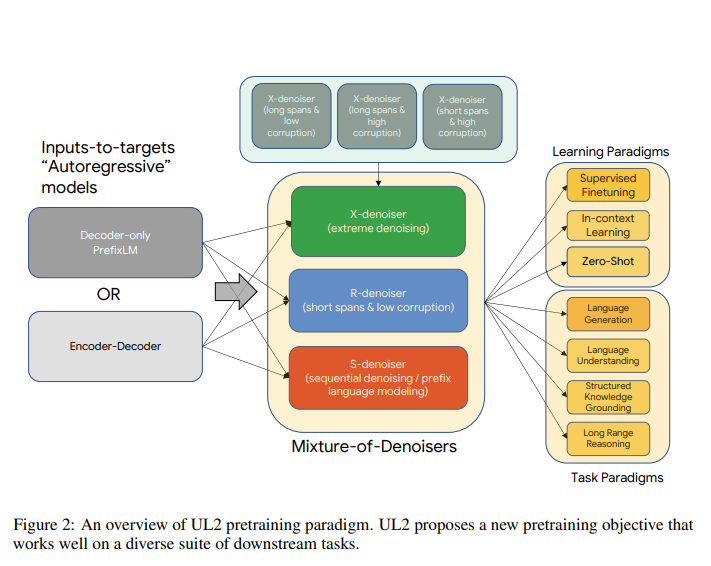
Unifying Language Learning Paradigms——谷歌的一个模型打天下
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。 而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。
突破英特尔CPU+英伟达GPU的大模型训练硬件组合:苹果与AMD都有新进展!
大语言模型的训练和微调的硬件资源要求很高。现行主流的大模型训练硬件一般采用英特尔的CPU+英伟达的GPU进行。主要原因在于二者提供了符合大模型训练所需的计算架构和底层的加速库。但是,最近苹果M2 Ultra和AMD的显卡进展让我们看到了一些新的希望。

Python入门的基本概念之包管理——pip与conda的简介对比
对于刚接触使用Python的同学来说,Python强大的生态与优秀的开源工具应该印象十分深刻。同时对于一些已经在使用Python解决问题的童鞋来说,使用pip来安装一些别人提供的工具应该已经熟悉了。当然,也有一些同学应该也听说可以使用conda来安装一些第三方的开源包。那么,python的包管理工具pip是一个什么样的东西?conda作为一个替代者或者补充,与pip有什么区别,二者分布适合什么情况下使用呢?本文将根据我的个人经验与观点为大家做一个简单的说明。


如何微调大语言模型?吴恩达联合LaminiAI最新一个小时短课教会大模型微调!这次是面向中级水平人员~
当谈及人工智能的巨大进步,大模型的崛起无疑是其中的一个重要里程碑。这些大模型,如GPT-3,已经展现出令人惊叹的语言生成和理解能力,但是为了让它们在特定任务上发挥最佳性能,大模型微调(Fine-tuning)是一种非常优秀的方法。微调是一种将预训练的大型模型进一步优化,以适应特定任务或领域的过程。但微调并不是很简单,今天吴恩达联合Lamini推出了全新的大模型微调短课《Finetuning Large Language Models》。
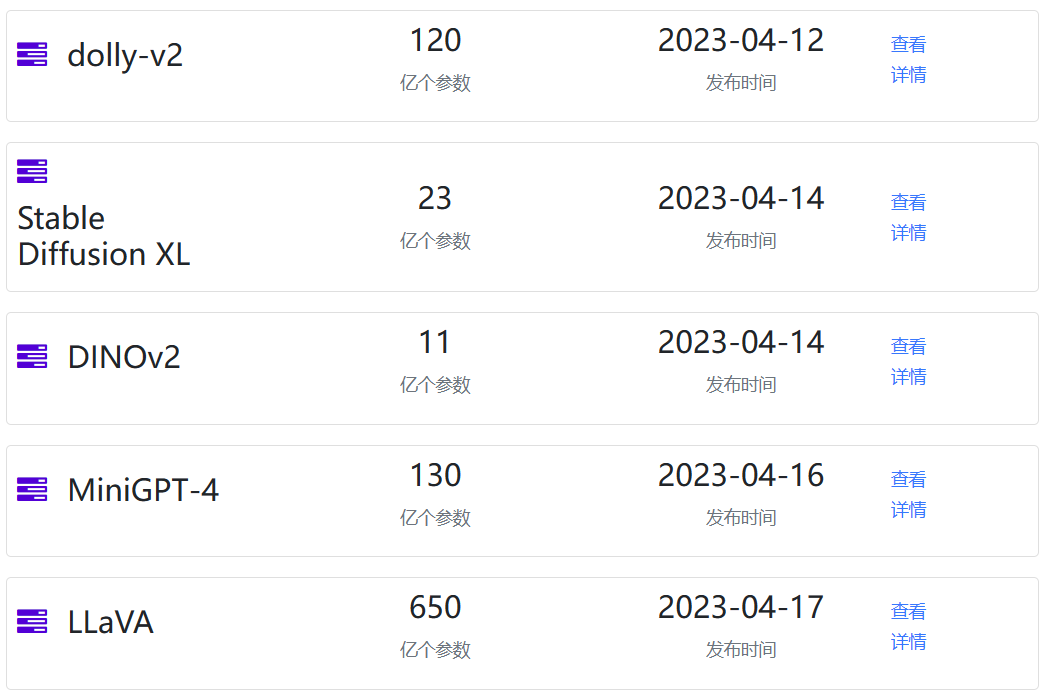
2023年4月中旬值得关注的几个AI模型:Dollly2、MiniGPT-4、LLaVA、DINOv2
AI模型的发展速度令人惊讶,几乎每天都会有新的模型发布。而2023年4月中旬也有很多新的模型发布,我们挑出几个重点给大家介绍一下。

GPT-4在11月份以来变懒的原因可能已经找到:大模型可能会在节假日期间变得不愿意干活,工作日期间却更加高效
最近一段时间,很多人普遍反映GPT-4变得懒散和愚笨,很多此前可以回答的问题在最近一段时间都无法回答,或者回答比较简单。为此,OpenAI官方也在前几天发布信息说的确收到了这样的信息,但是模型并没有在最近一个多月更新过,所以他们也在好奇是什么原因。而今天的一些测试表明,GPT-4模型会像人一样在不同的时间段有不同的效率。
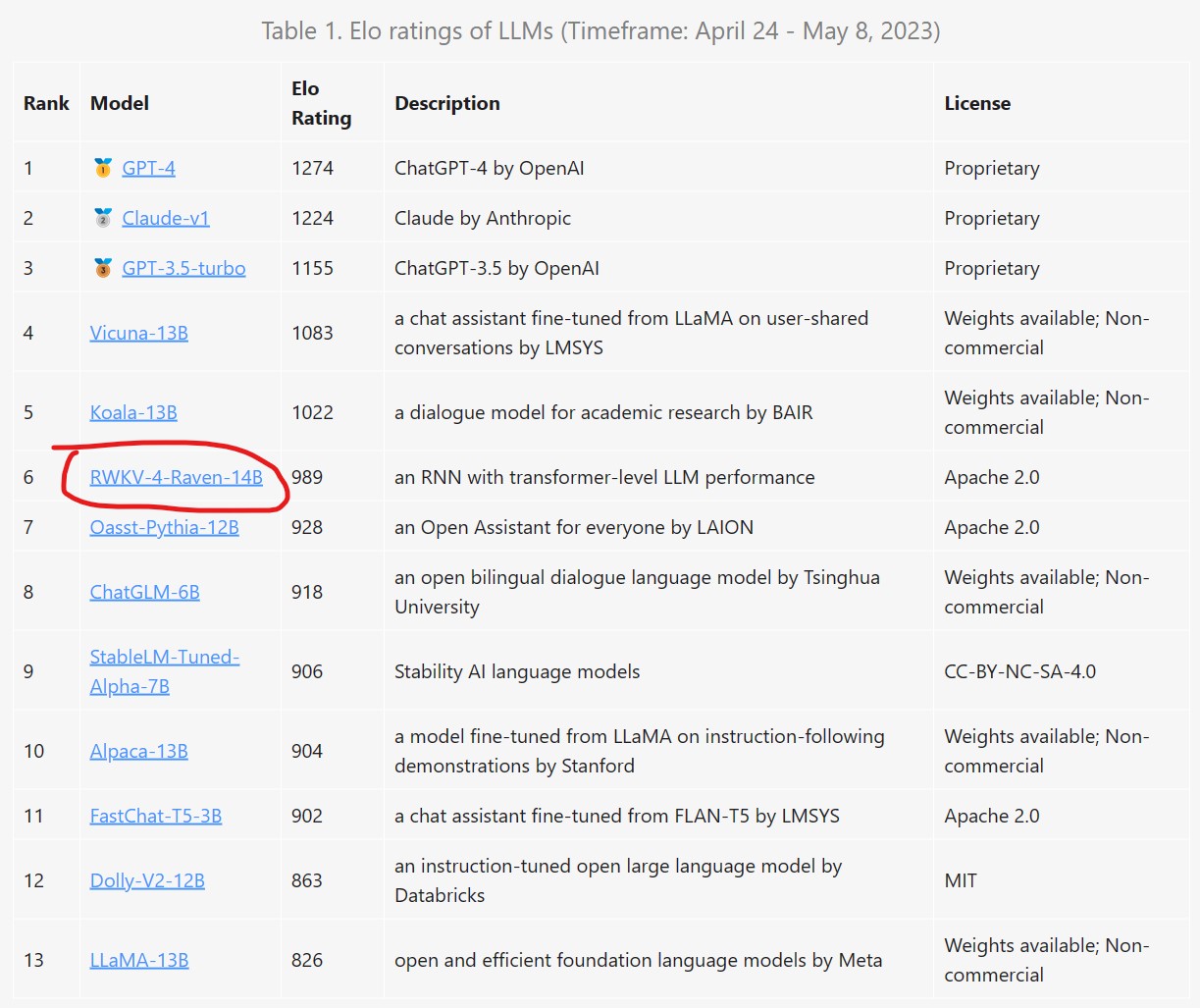
HuggingFace宣布在transformers库中引入首个RNN模型:RWKV,一个结合了RNN与Transformer双重优点的模型
RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。今天,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型,足见RWKV模型的价值。

让大模型支持更长的上下文的方法哪个更好?训练支持更长上下文的模型还是基于检索增强?
在大语言模型中,上下文长度是指模型可以考虑的输入数据的数量。更长的上下文在大语言模型的实际应用中有非常重要的价值。当前,让大语言模型支持更长的上下文有两种常用的方法,一种是训练支持更长上下文长度的模型,扩展模型的输入,另外一种是检索增强生成的方法(Retrieval Augmentation Generation,RAG)。但二者应该如何选择,这是一个很少能直接比较的问题。为此,英伟达(Nvidia)的研究人员做了一个详细的比较。

OpenAI发布新一代向量大模型,接口已经更新到text-embedding-3-large,embedding长度升级,价格最高下降5倍!
决定向量检索准确性的核心是向量大模型的能力,即文本转成embedding向量是否准确。今天,OpenAI宣布了他们第三代向量大模型text-embedding,模型能力增强的同时价格下降!

Awesome ChatGPT Prompts——一个致力于提供挖掘ChatGPT能力的Prompt收集网站
Awesome ChatGPT Prompts是由JavaScript开发者Fatih Kadir Akın创建的一个网站和应用,里面收集了160多个关于ChatGPT的Prompt模板,可以让ChatGPT变成Linux终端、JavaScript控制台、Excel页面等。这些Prompts收集自优秀的实践案例。

平衡二叉树之红黑树(Red-Black Tree)简介及Java实现
红黑树(Red-Black Tree)也是一种自平衡二叉查找树,与AVL不同的是它依靠节点颜色来维护树的平衡,在自平衡操作的时候,依赖变色和旋转两种操作来进行。
重磅!来自Google内部AI研究人员的焦虑:We Have No Moat And neither does OpenAI
5月4日,网络流传了一个所谓Google内部人员写的内部信,表达了Google和OpenAI这样的公司可能并不能在AI领域获得胜利的焦虑。里面说明了开源的AI模型发展迅速,不管是Google还是OpenAI都没有很好的护城河。