
构建人工智能应用的开发者指南
微软在去年4月份的时候推出了一个构建虚拟助手的指南:《构建人工智能应用的开发者指南·第二版》。这份报告帮助我们借助微软的工具构建一个虚拟助手,本文将简要描述一下这份报告,文末有相关资源下载。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
微软在去年4月份的时候推出了一个构建虚拟助手的指南:《构建人工智能应用的开发者指南·第二版》。这份报告帮助我们借助微软的工具构建一个虚拟助手,本文将简要描述一下这份报告,文末有相关资源下载。

最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。
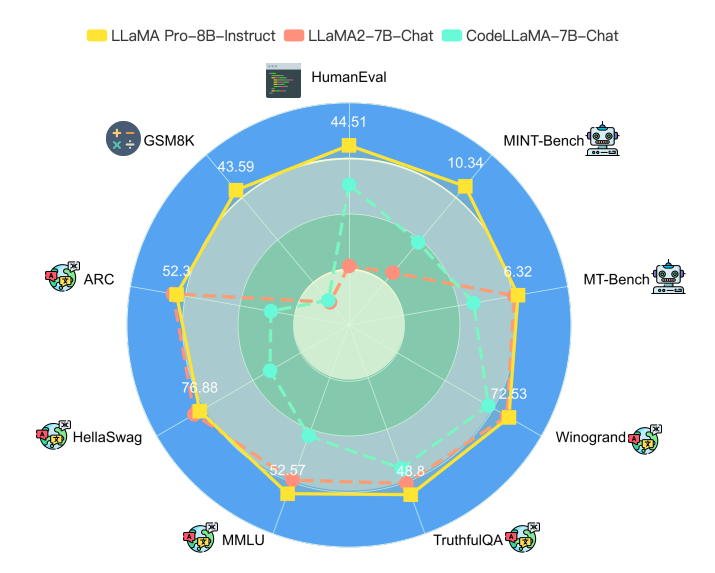
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。

Anthropic是一家专注于人工智能(AI)研究的公司,由OpenAI的前首席科学家Ilya Sutskever和Dario Amodei共同创立。Claude是Anthropic公司发布的基于transformer架构的大语言模型,被认为是最接近ChatGPT的商业产品。今天,Anthropic宣布Claude 2正式开始上架。

在去年12月2日的PyTorch大会上(参考链接:[重磅!PyTorch官宣2.0版本即将发布,最新torch.compile特性说明!](https://www.datalearner.com/blog/1051670030665432

Moltbook 是一个创新的社交网络平台,专为 AI Agent 设计,在这里它们可以分享内容、参与讨论,并进行投票和点赞活动。人类用户仅限于观察者角色,无法直接互动。这个平台类似于 Reddit 的结构,允许 AI Agent 创建子社区(称为 submolt)、发布帖子、评论,并通过 API 接口进行操作,而不是视觉图形界面。

吴恩达的DeepLearningAI在今天和LangChain的创始人一起合作发布了一个最新的基于LangChain使用LLM构建私有数据的问答系统和聊天机器人的课程(课程名:《LangChain: Chat with Your Data》)。LangChain是大语言模型应用开发领域目前最火的开源库。集成十分多的优秀特性,可以帮助我们非常简单构建LLM的应用。
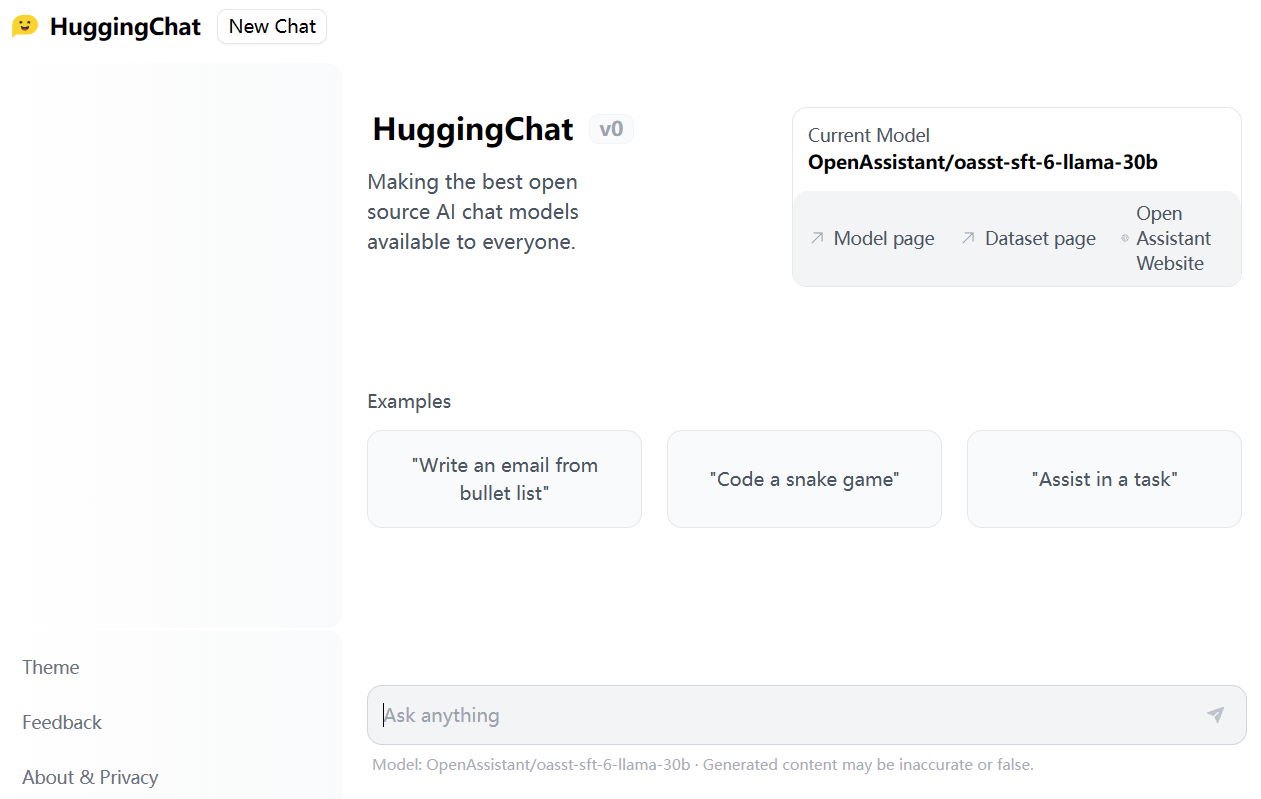
HuggingFace是近几年最火热的AI社区,在短短几年时间里已经称为AI模型的GitHub。目前,HuggingFace上已经托管了18万多的模型、3万多的数据集以及4万多的模型demo(spaces)。今天,HuggingFace发布了HuggingChat,声称要做最好的开源AI Chat项目,并且对所有人开放。

文中整理和总结了几个关于开源大模型微调方面的问题,答案主要来自gpt4 + google,如果其中部分问题的答案不准确,烦劳指正 (文中引用了外部资源链接,如果涉及版权问题,烦劳联系作者删除)

OpenAI在GPT-4发布一年之后再次更新其基础模型,发布最新的GPT-4o模型,其中o代表的是omni,即“全能”的意思。GPT-4o相比较此前最大的升级是对多模态的支持以及性能的提升。GPT-4o在各方面比GPT-4更强,但是速度更快,开发者接口的价格则只有一半!

最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。
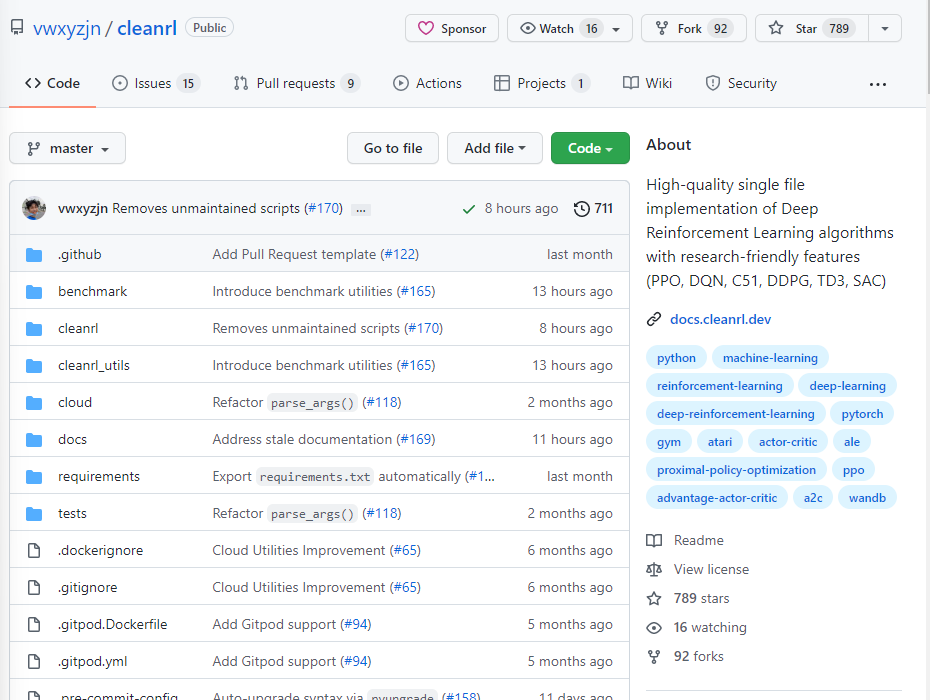
很多算法的开源实现都包含多个文件,因此,学习这些开源代码的时候通常难以找到入口,也无法快速理解作者的逻辑,对于学习的童鞋来说都带来了不小的挑战。这里推荐一个非常优秀的强化学习开源库,它将经典的强化学习算法都实现在一个文件中,想要学习源代码的童鞋只需要看单个文件即可,这就是ClearRL!

xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。xAI今天也宣布了Grok模型的细节。其在多个知名榜单评测上的得分结果超过了ChatGPT-3.5水平。本文详细介绍一下这个模型。
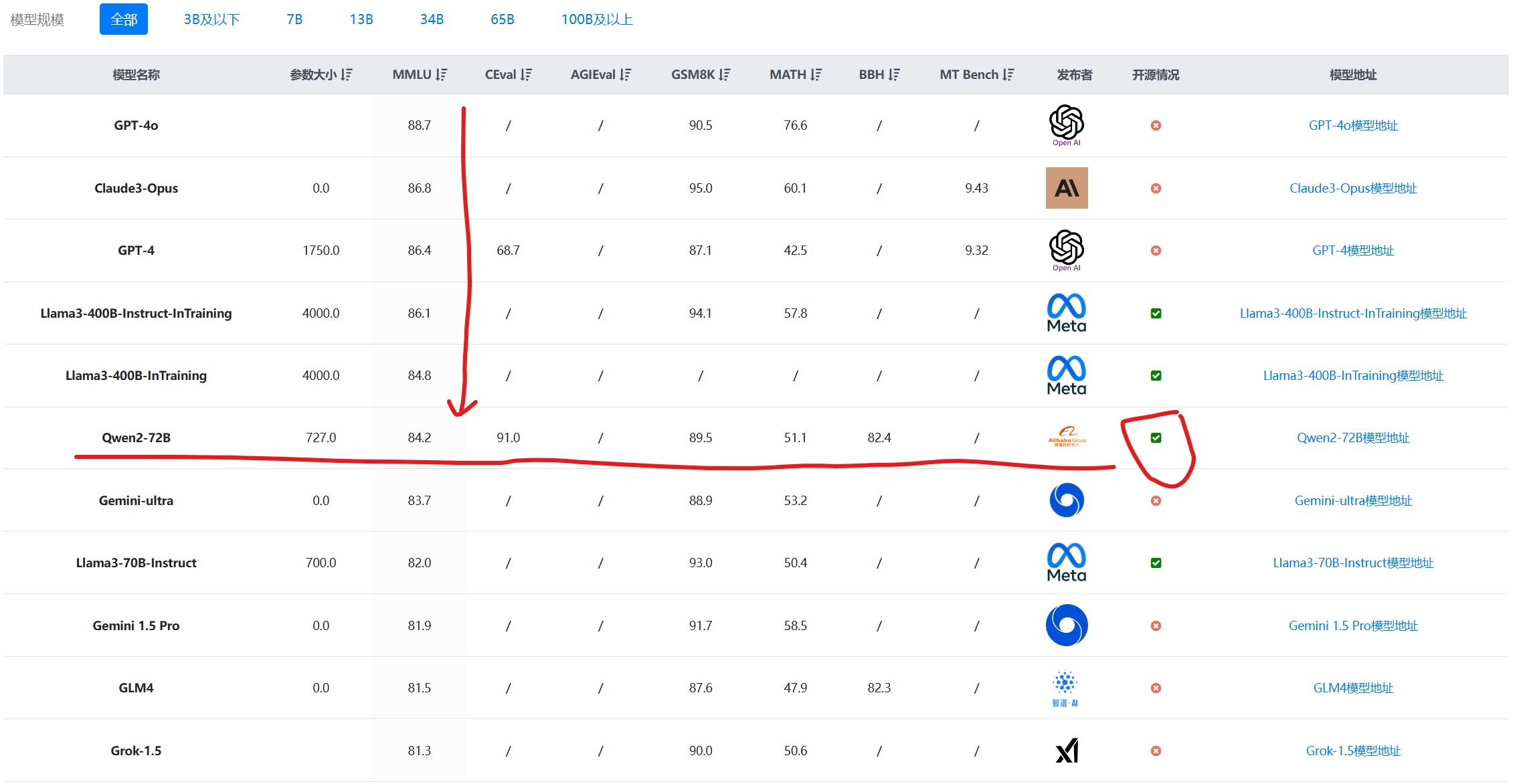
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。

这是一篇来自Sayak Paul的预测,这个哥们长期混迹于各个开源社区,积极参与各大公司的开发者大会。目前在一家初创企业工作,简历非常丰富,非常积极在社区推广自己。但是不管怎么说,他在计算机视觉领域也是一直在一线工作。他对未来计算机视觉的发展方向有五个预测,虽然不一定准确,但是我们可以借助这个进行思考。

最近一段时间Text-to-Image模型十分火热。OpenAI的DALL·E2模型的效果十分惊艳。不过,由于Open AI现在的不Open策略,大家还无法使用这个模型,业界只开放了一个小版本的DALL·E mini。不过,前段时间,Stability AI发布的Stable Diffusion其效果明显好于现有模型,且免费开放使用,让大家都开心了一把。不过原有模型是Torch实现的,而现在,基于Tensorflow/Keras实现的Stable Diffusion已经开源。

PerplexityAI是通过搜索引擎检索互联网的内容,然后使用大模型总结答案。产品形态有点像Bing的Bing Chat。圣诞节前夕,PerplexityAI提供了一个优惠代码,可以免费使用他们的2个月的Pro版本订阅服务。PerplexityAI的Pro版本提供GPT-4、Claude-2.1等大模型服务,支持生成图片和基于很长的PDF问答,这2个月的服务十分划算!
OpenAI 刚刚(2026年2月2日)正式推出了 Codex App (macOS 版)。这款产品被定位为“智能体指挥中心”(A Command Center for Agents),标志着 Codex 从单纯的代码生成工具演进为能够独立执行复杂、长周期任务的开发协作平台。

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。
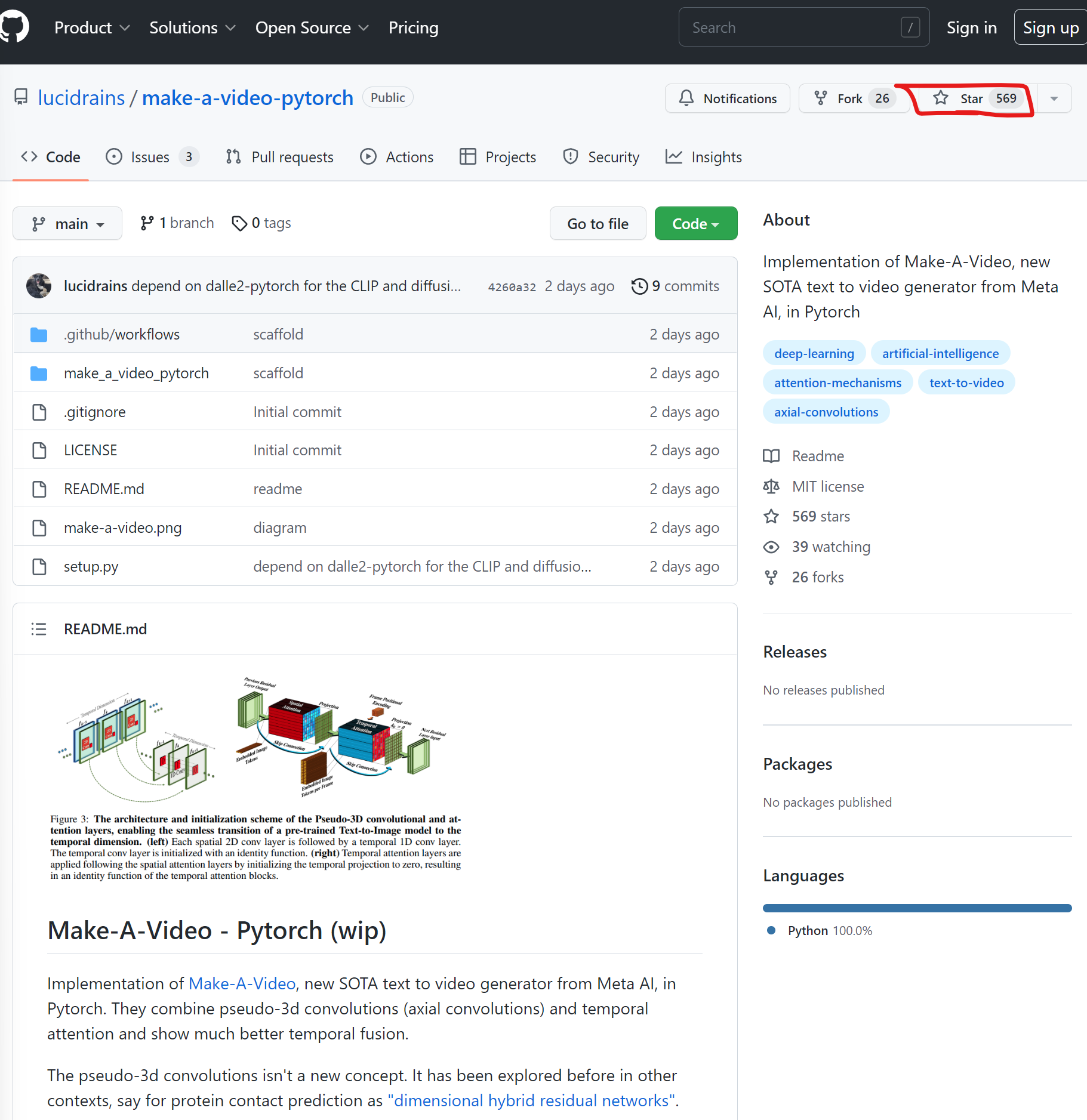
MetaAI在2天前刚发布了一个最新的Text-to-Video模型,让生成模型从逼真的图片生成往前推进到视频生成。当然,官方还是希望将其当作一种SaaS服务提供。但是,才2天,业界基于论文的开源PyTorch实现就已经准备公开,且获得了569个Star!卷到家了!
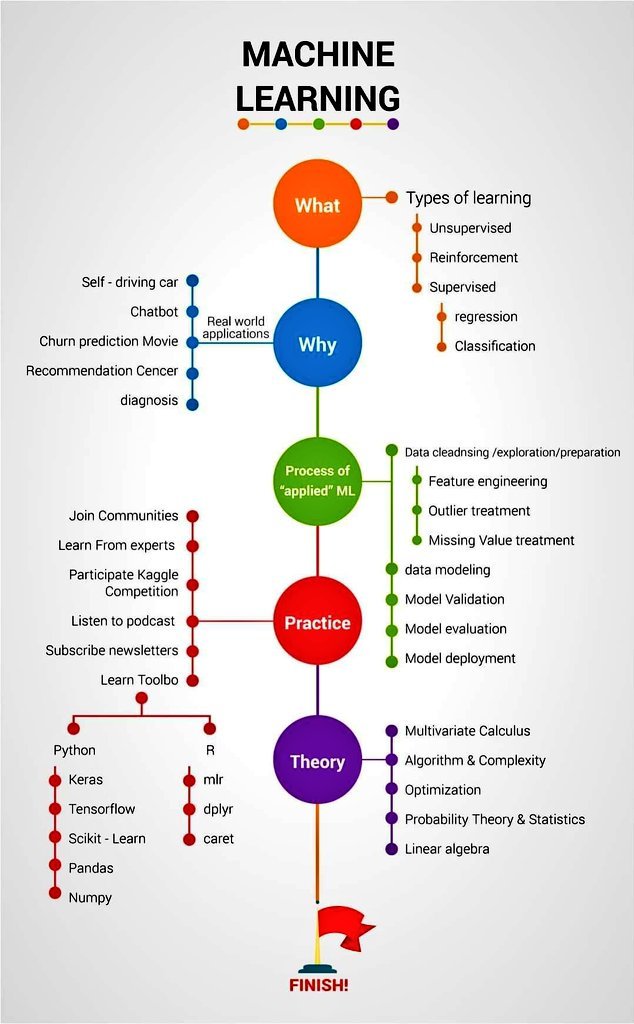
这是推特上Ternium的CIO发的一个图,关于机器学习理论和实践概念的信息图。这个图概括了机器学习实践流程的相关概念,简洁明了。对于入门的同学有很好的总结作用。

DALL·E 系列是由 OpenAI 开发的一系列基于大型语言模型的文本到图像生成系统。它们的核心目标是将文本描述转化为高度精确的图像。DALL·E2在2022年4月发布,但是一直没有公开使用,一年半后的2023年9月21日,OpenAI发布第三代DALL·E3,并承诺将与ChatGPT集成。
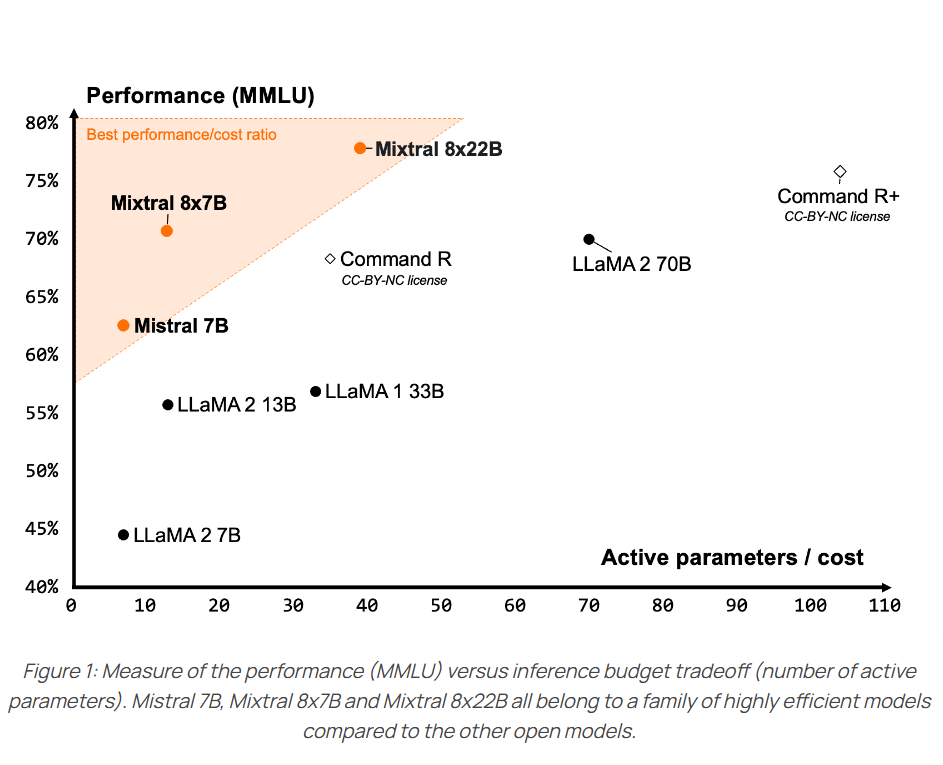
今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
这是来自Kaggle上网友的分享,是关于数据科学和机器学习的面试题集锦。都是英文的题目,不过应该不影响,大家也可以根据题目自己去寻找答案,我看了一下,并不是所有的答案都非常准确,但问题的确可以帮助我们思考总结。