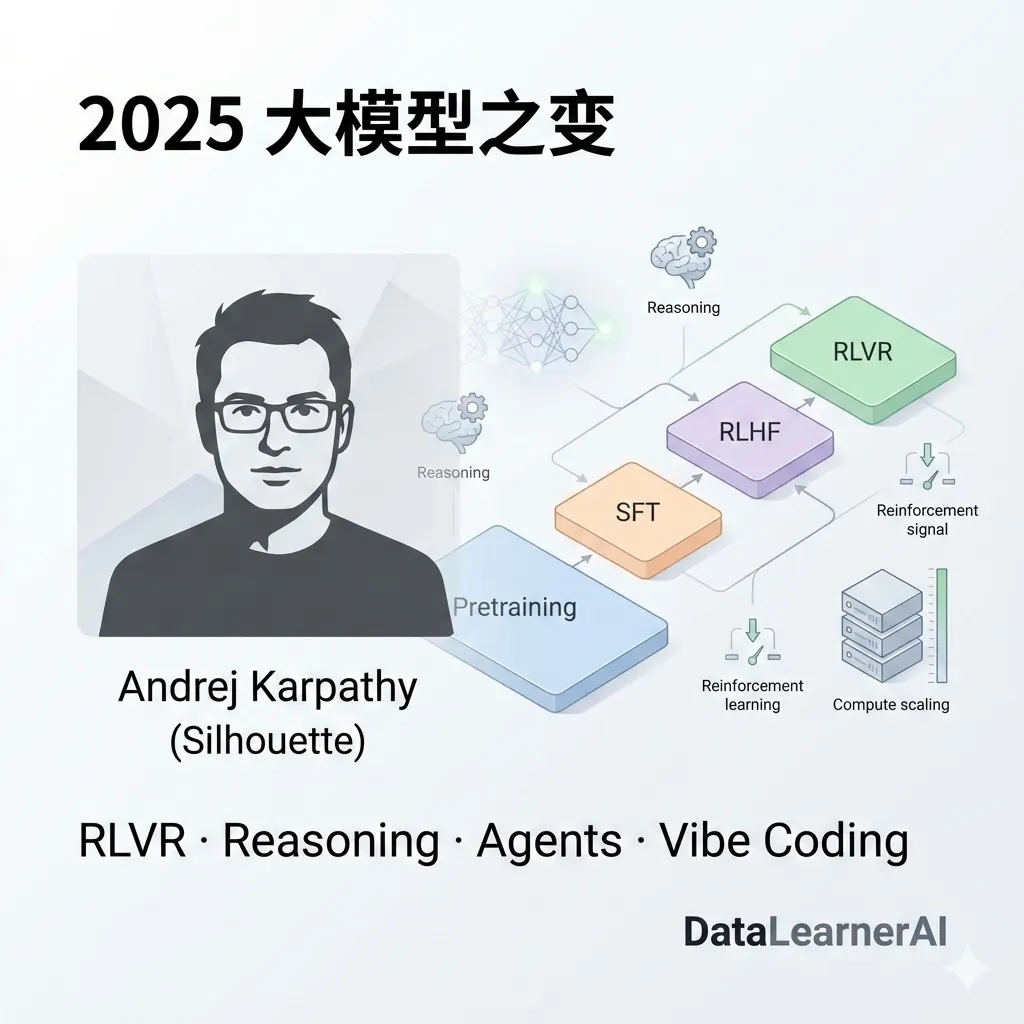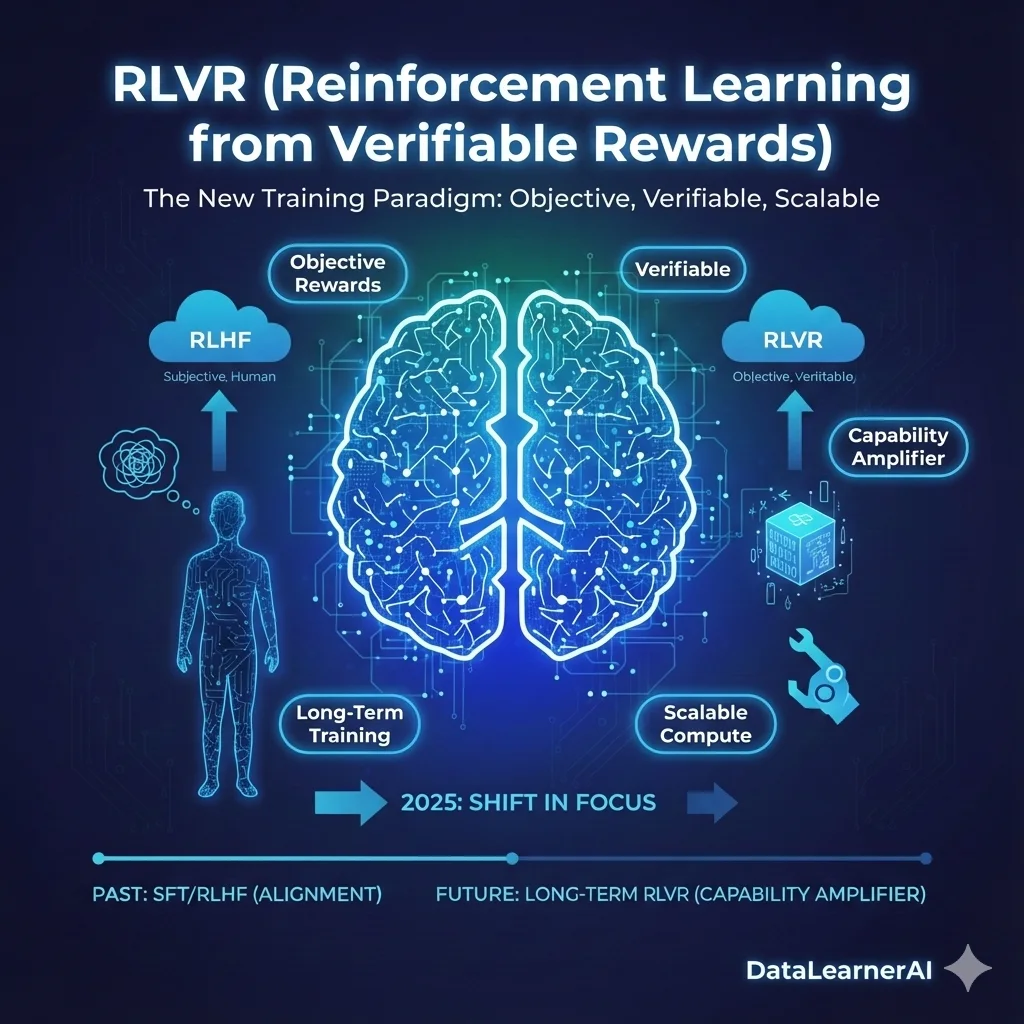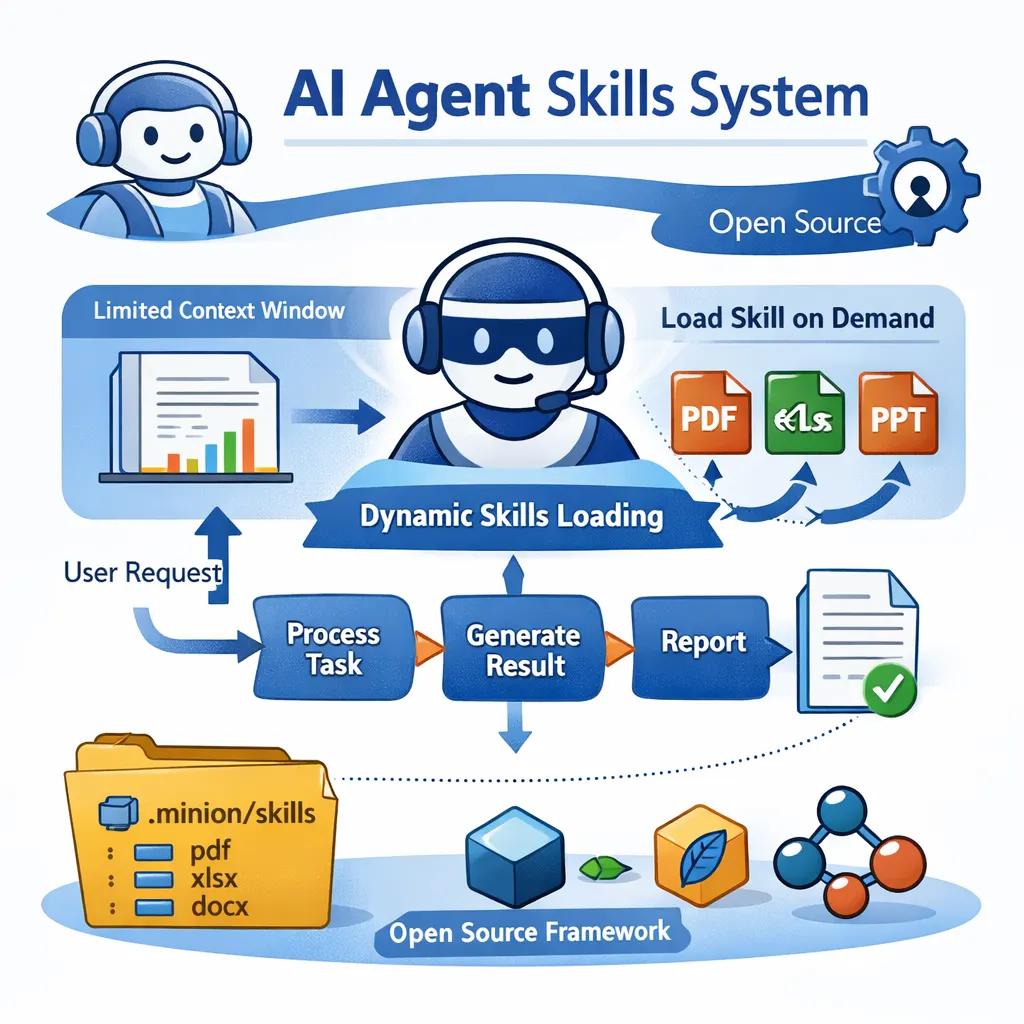
在大模型时代,AI 产品为什么更难复用?AI Agent产品应该如何开发?来自 Manus 的3个工程实践经验
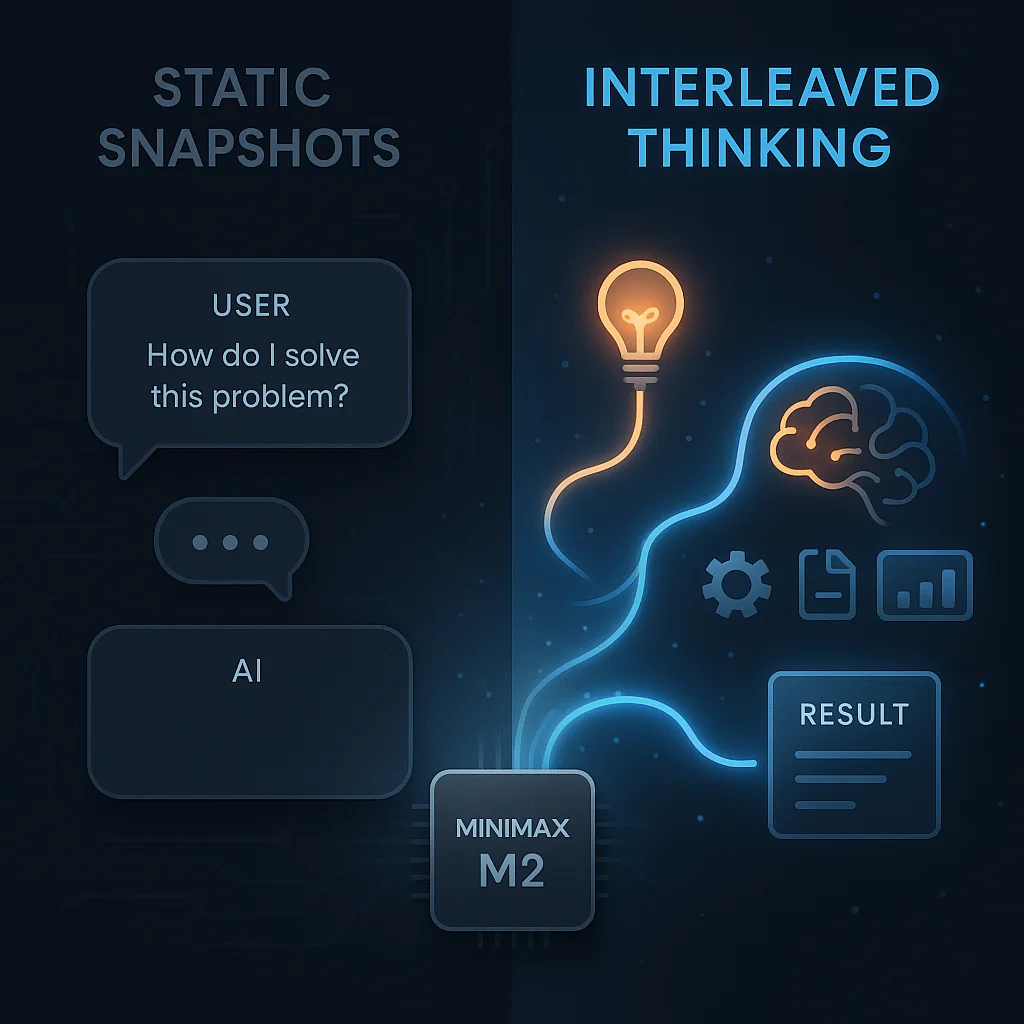
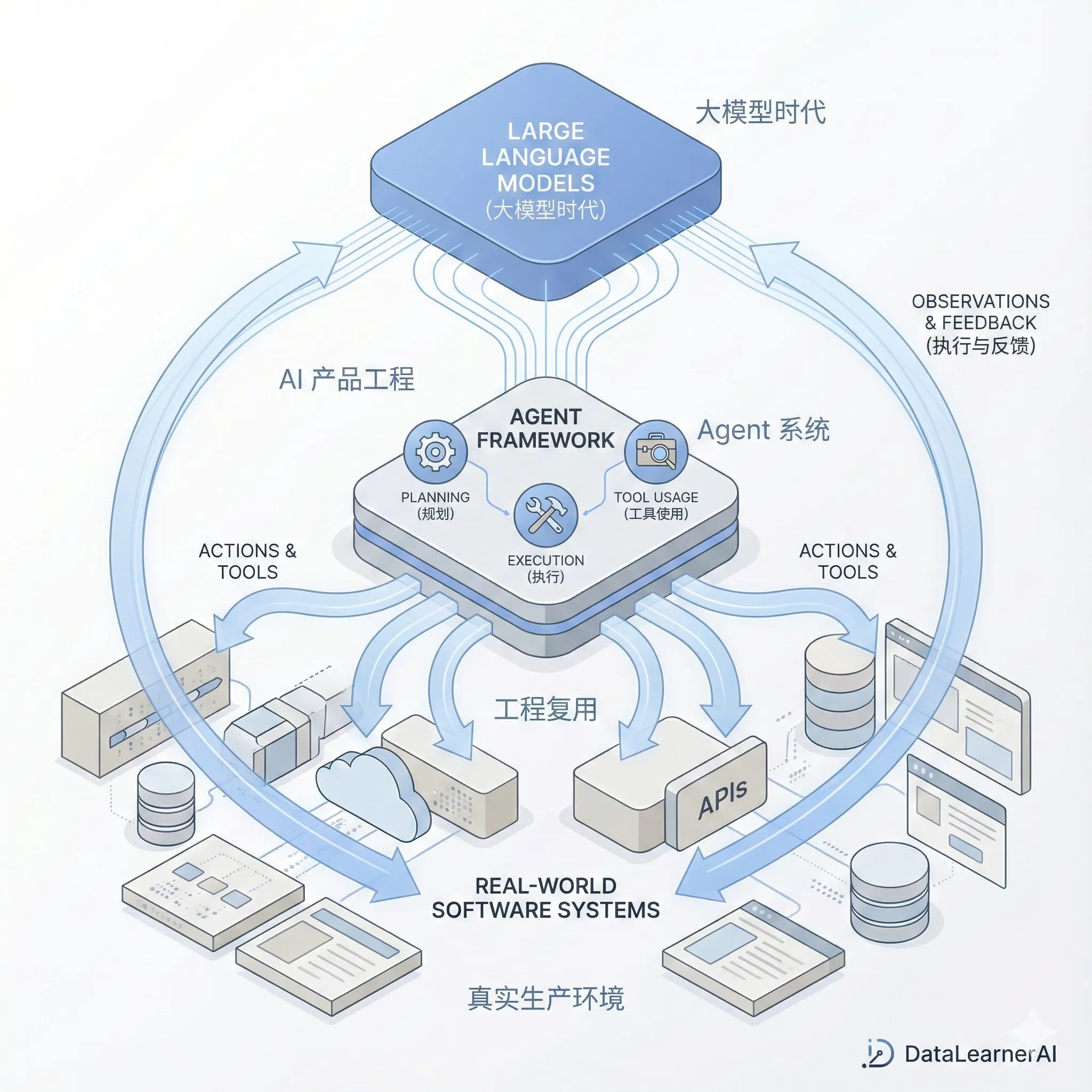
本文基于 Manus 一线工程成员的真实实践,总结并分析了 大模型时代 AI 产品在工程与复用层面发生的关键变化。文章并不关注模型参数或算法细节,而是聚焦于真实生产环境中的工程问题:功能交付的责任边界如何变化、为何原型验证比完整规划更重要,以及在 Agent 系统中个人角色与系统边界如何被重新定义。这些经验揭示了一个趋势——在大模型具备“执行能力”之后,AI 产品的可用性越来越依赖工程体系本身,而非模型能力本身。本文适合关注 AI 工程实践、Agent 架构以及大模型落地问题的技术读者参考。