使用kaggle房价预测的实例说明预测算法中OneHotEncoder、LabelEncoder与OrdinalEncoder的使用及其差异
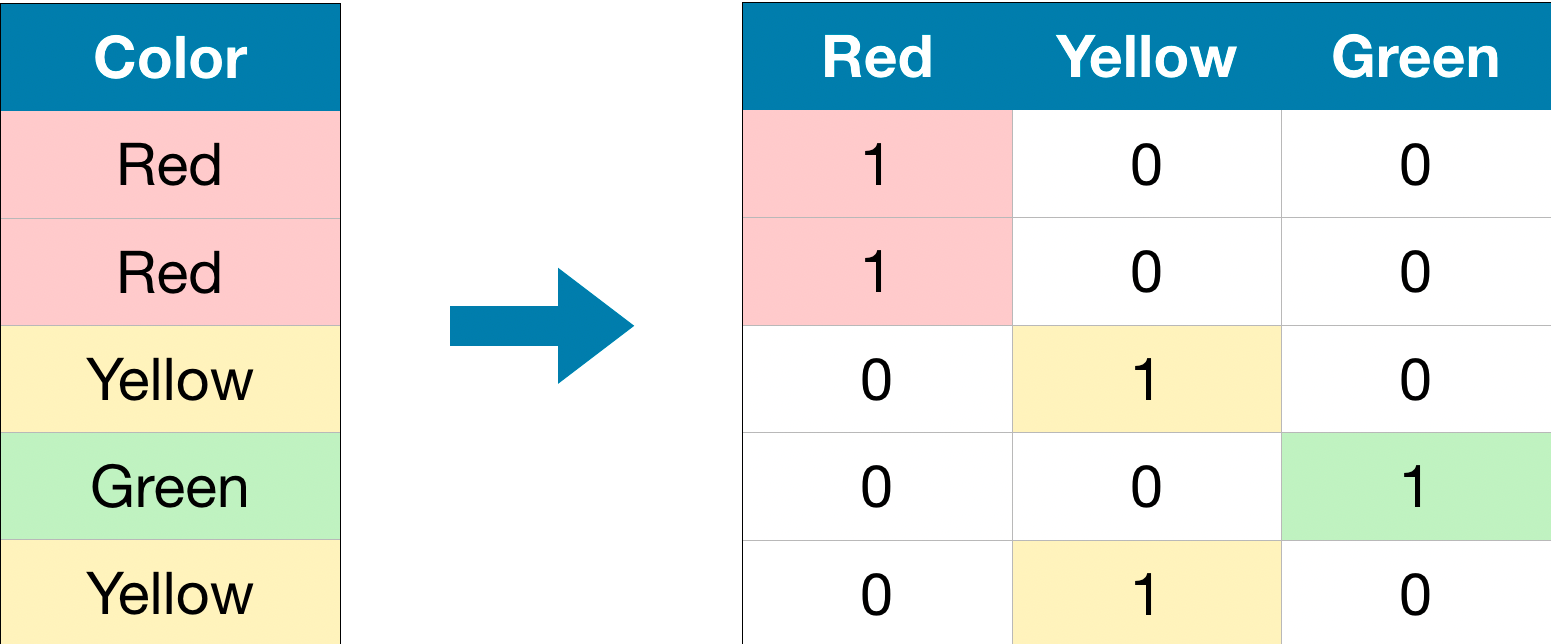
对于分类特征的处理,sklearn中常见的方法有两种,一种是OneHotEncoder,另一种很多人说是LabelEncoder,其实不对。sklearn中,还有一个OrdinalEncoder,二者似乎一样,但其实并不相同,差别很大。本文将用Kaggle的房价预测的实例来描述如何这些差异以及不同处理对预测算法的影响。
汇总「A」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
对于分类特征的处理,sklearn中常见的方法有两种,一种是OneHotEncoder,另一种很多人说是LabelEncoder,其实不对。sklearn中,还有一个OrdinalEncoder,二者似乎一样,但其实并不相同,差别很大。本文将用Kaggle的房价预测的实例来描述如何这些差异以及不同处理对预测算法的影响。

pandas.get_dummies是pandas中一种非常高效的方法。它最主要的作用是可以将分类变量转变成dummy变量,也就是虚拟变量。这篇博客将简要的介绍一下pandas.get_dummies()方法,并描述其在机器学习中的应用的一些注意事项。

对于刚接触使用Python的同学来说,Python强大的生态与优秀的开源工具应该印象十分深刻。同时对于一些已经在使用Python解决问题的童鞋来说,使用pip来安装一些别人提供的工具应该已经熟悉了。当然,也有一些同学应该也听说可以使用conda来安装一些第三方的开源包。那么,python的包管理工具pip是一个什么样的东西?conda作为一个替代者或者补充,与pip有什么区别,二者分布适合什么情况下使用呢?本文将根据我的个人经验与观点为大家做一个简单的说明。

影响者营销将是极好的机会,可以使你的形象更加完善,并接触到新的受众,是一个人性化的宏伟机会?的确如此。它是否充满了影响者和品牌宁愿不管理的问题?同样地,是的。
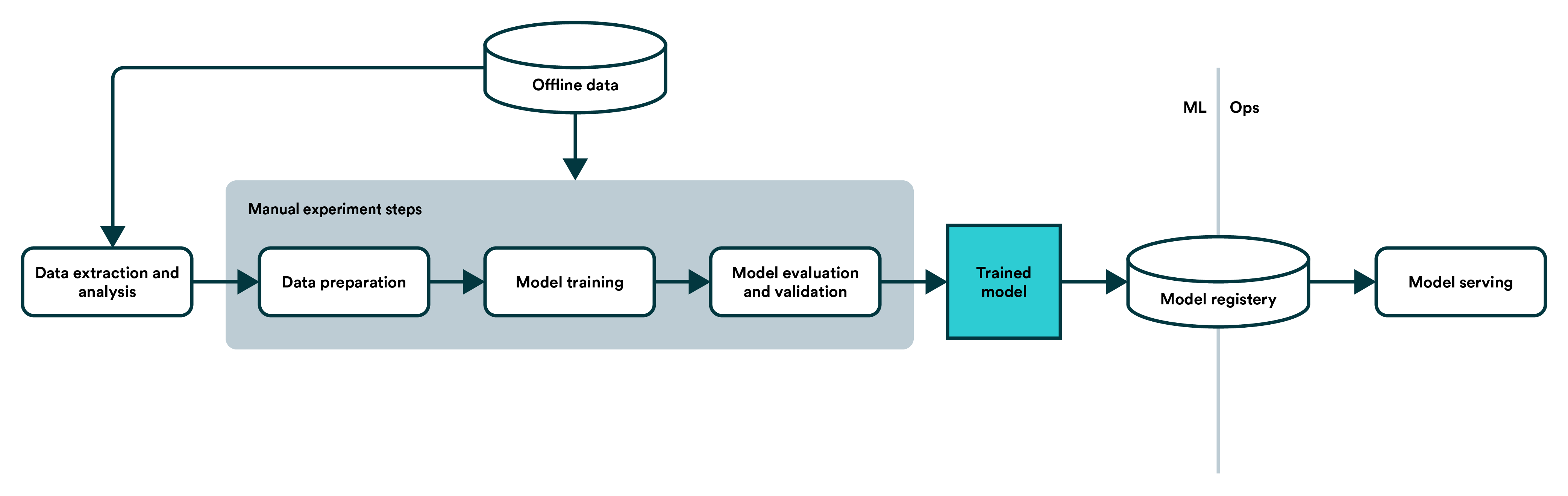
基于算法的业务或者说AI的应用在这几年发展的很快。但是,在实际应用的场景中,我们经常会遇到一些非常奇怪的偏差现象。例如,Facebook将黑人标记为灵长类动物、城市图像识别系统将公交车上的董明珠形象广告识别为闯红灯的人等。算法系统出现偏差的原因有很多。本篇博客将总结在数据获取相关方面可能导致模型出现偏差的原因。

Batch Normalization(BN)是一种深度学习的layer(层)。它可以帮助神经网络模型加速训练,并同时使得模型变得更加稳定。尽管BN的效果很好,但是它的原理却依然没有十分清晰。本文总结一些相关的讨论,来帮助我们理解BN背后的原理。
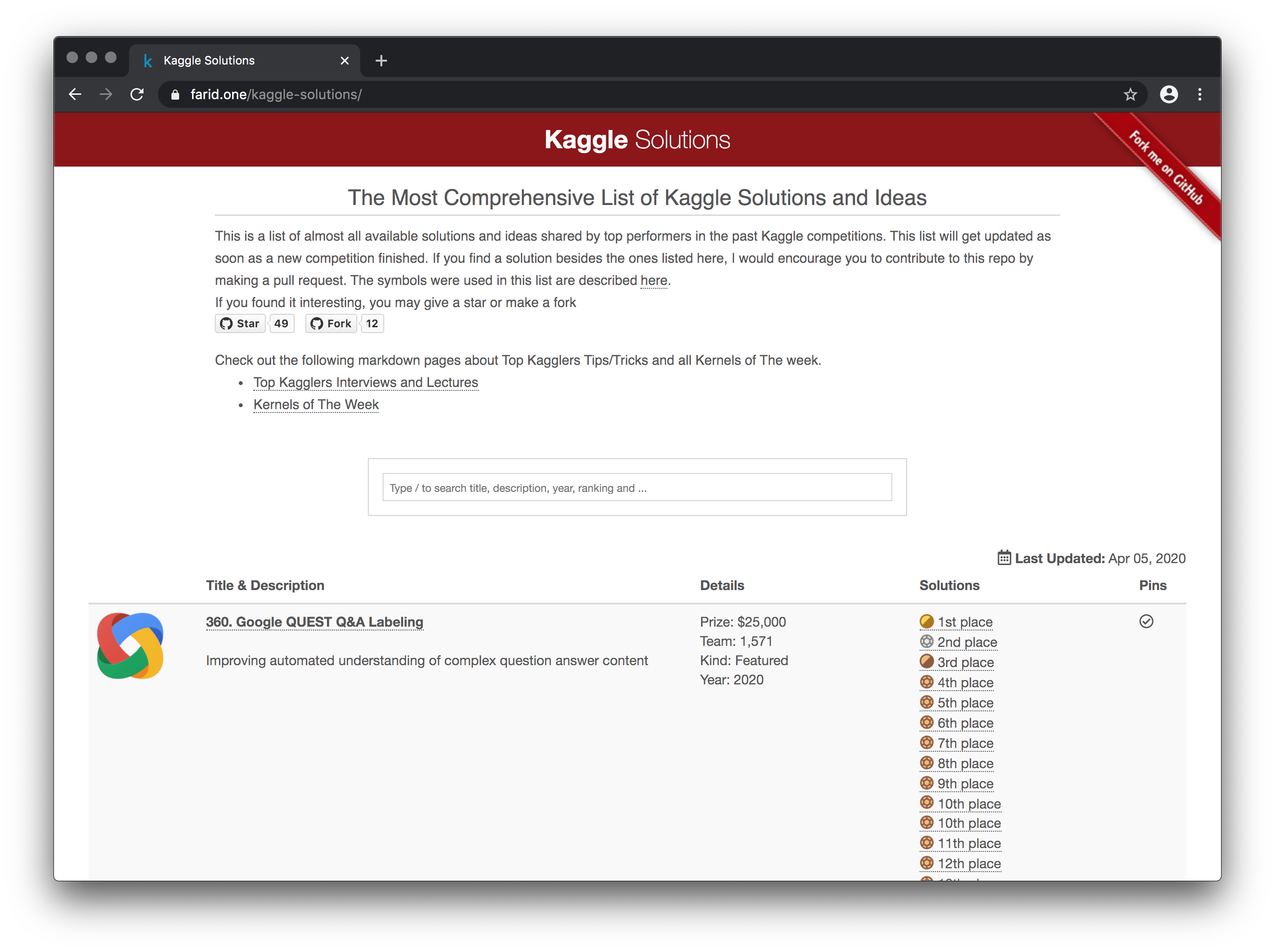
这是一位热心网友(faridrashidi)收集的Kaggle竞赛的解决方案。这是在过去的Kaggle竞赛中表现最好的选手所分享的几乎所有可用的解决方案和想法的列表。一旦有新的比赛结束,这个列表就会更新。

Python最新正式版本3.10在10月4日已经发布。这个版本从2020年5月开始开发,经历差不多一年半的时间终于正式发布。当然每一个新版本都有很多新功能。我们将持续关注新功能,在这篇文章中,我们将简述3.10中新功能中的语法——结构模式匹配(structural pattern matching)。
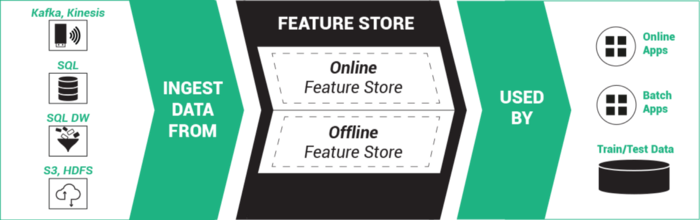
在2020年的亚马逊reInvent发布会上,亚马逊正式发布了一项新的服务,即Amazon SageMaker Feature Store,中文简介是适用于机器学习特征的完全托管的存储库。 Feature Store是这两年兴起的另一个关于人工智能系统的基础设施,应该也是未来几年最重要的人工智能基础设施之一。本文将介绍一下Feature Store是什么以及为什么很多企业开始推广这个东西。
运行本地dask集群的时候出错Task exception was never retrieved的解决方法
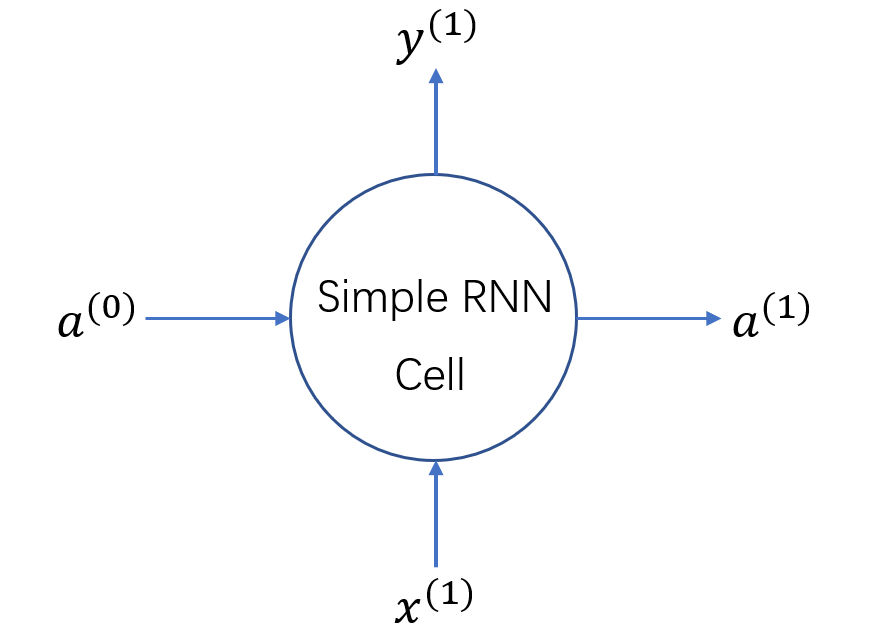
RNN的应用有很多,尤其是两个RNN组成的Seq2Seq结构,在时序预测、自然语言处理等方面有很大的用处,而每个RNN中一个节点是一个Cell,它是RNN中的基本结构。本文从如何使用RNN建模数据开始,重点解释RNN中Cell的结构,以及Keras中Cell相关的输入输出及其维度。我已经尽量解释了每个变量,但可能也有忽略,因此可能对RNN之前有一定了解的人会更友好,本文最主要的目的是描述Keras中RNNcell的参数以及输入输出的两个注意点。如有问题也欢迎指出,我会进行修改。
在使用Dask进行两个dataframe的concatenate操作的时候抛出ValueError,本文记录这个错误以及解决方案。
在前面的博客中,我们已经对`Dask`做了一点简单的介绍了,在这篇博客中我们来对比一下`Dask`的`DataFrame`在不同条件下的运算性能,主要是连接操作的性能(merge)。
使用Dask进行分布式处理的时候一个最常见的场景是有很多个文件,每个文件由一个进程处理。这种操作经常会遇到一个程序挂起的问题,使得程序永远运行,无法结束。本文描述如何解决。
使用pandas的DataFrame和dask的DataFrame保存数据到csv文件时候会出现两个换行符的情况。本文描述如何解决。
Dask的集群启动创建也很简单,有好几种方式,最简单的是采用官方提供dask-scheduler和dask-worker命令行方式。本文描述如何使用命令行方法建立Dask集群。
当数据量达到一定程度,单机的处理能力会无法达到性能的要求,采用并行计算,并利用多台服务器进行分布式处理可能会提升数据处理的速度,达到性能要求。然而如果使用不当,并行处理可能并不会提升处理的速度。这篇博客介绍了Dask中关于并行处理的一些效率方面的建议,尽管是针对Dask的说明,但对于所有的并行处理来说都是适用的。
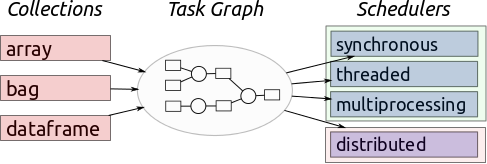
Dask提供了多种分布式调度器,当缺少多台服务器时候,也可以通过本地集群来实现单机分布式的计算。这篇博客主要就是介绍如何实现Dask的单机分布式调度器。第一小节是简介,第二节是单机调度器的简写版本,第三节是单机调度器的完整版本,第四节是使用的一些示例。
Pandas中的DataFrame选择某些行和某些列是有很多中操作和选择的,不太容易记,这里整理一下。

Scikit-Learn有很优秀的机器学习处理思想,包括TensorFlow等新框架都借鉴了它的设计思想。最近的更新也让Scikit-Learn更加强大。在描述这个更新之前我们先简单看一下历史,然后让我们一起看看都有什么新内容吧。