OpenAI发布全新文本生成视频大模型Sora,可以生成无比逼真的最长60秒的视频,且生成的视频尺寸可以任意指定
OpenAI宣布发布全新的Diffusion大模型Sora,这是一个可以生成最长60秒视频的视频生成大模型,最大的特点是可以生成非常逼真的电影画面版的视频。
汇总「R」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
OpenAI宣布发布全新的Diffusion大模型Sora,这是一个可以生成最长60秒视频的视频生成大模型,最大的特点是可以生成非常逼真的电影画面版的视频。
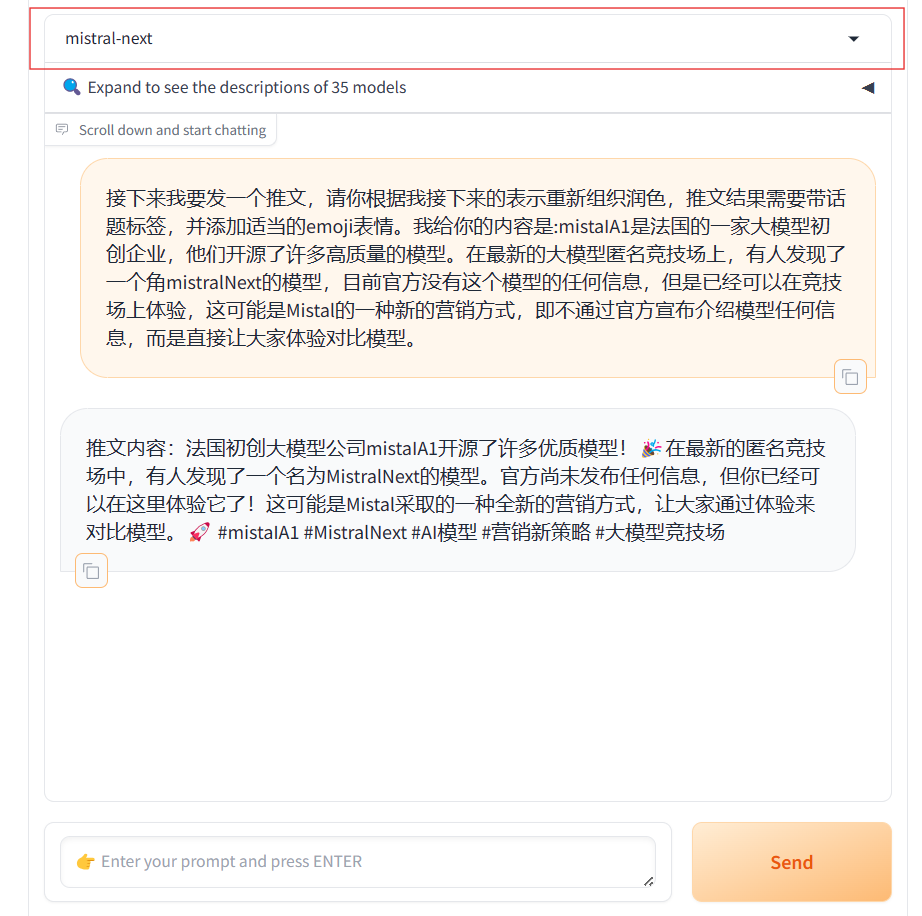
MistralAI又悄悄地上线了另一个模型,即Mistral Next。相比之前的发布预训练种子引起大家猜测的方式,本次MistralAI又把模型发布玩出了花,他们没有公布任何信息,选择直接上架LM-SYS的大模型竞技场Chat Arena,让大家直接体验对比。
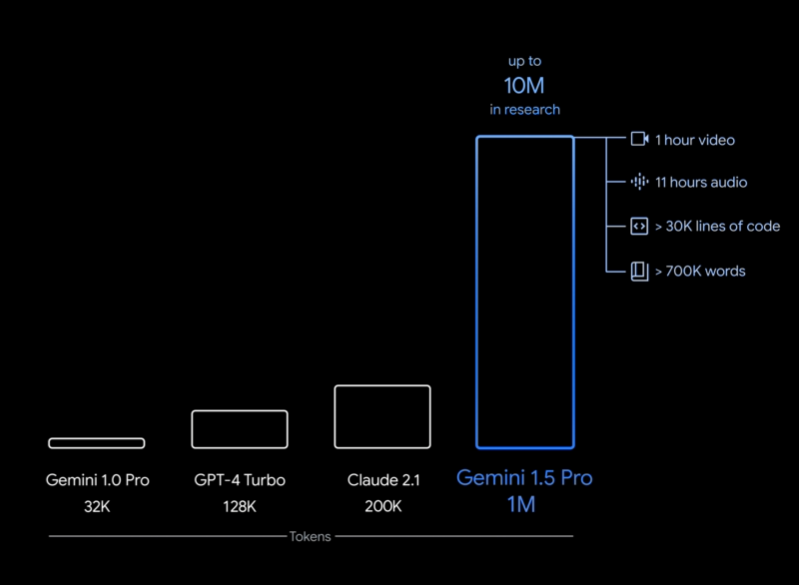
在2023年12月份,Google发布了Gemini系列大模型(参考:谷歌发布号称超过GPT-4V的大模型Gemini:4个版本,最大的Gemini的MMLU得分90.04,首次超过90的大模型),包含3个不同参数规模的版本。其中,Gemini Ultra号称在MMLU评测上超过了GPT-4,并且在月初也将Bard更名为Gemini,开放了Gemini Ultra的付费使用。刚刚,Google的CEO劈柴哥宣布发布了Gemini 1.5 Pro,这意味着仅仅一个半月,Gemini有了重大更新。
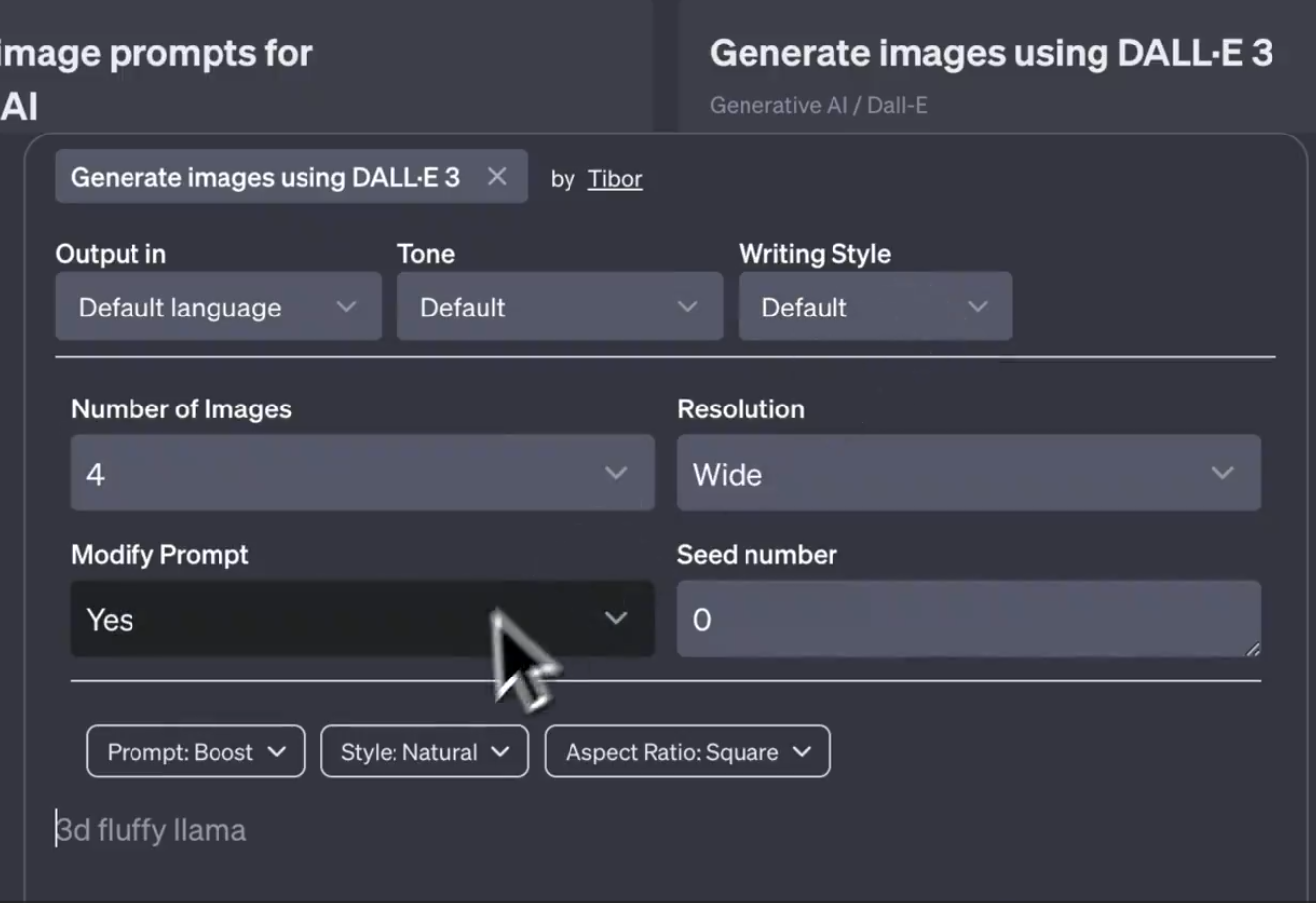
DALL·E3是OpenAI推出的文本生成图片服务,背后也是一个文生图大模型。此前,该模型只能通过对话的方式让模型生成图片结果。无法通过配置信息控制模型输出的效果,包括风格、比例等。而最新的截图显示,OpenAI可能即将推出DALL·E Controls功能,可以从不同的方面来控制图片生成的效果。
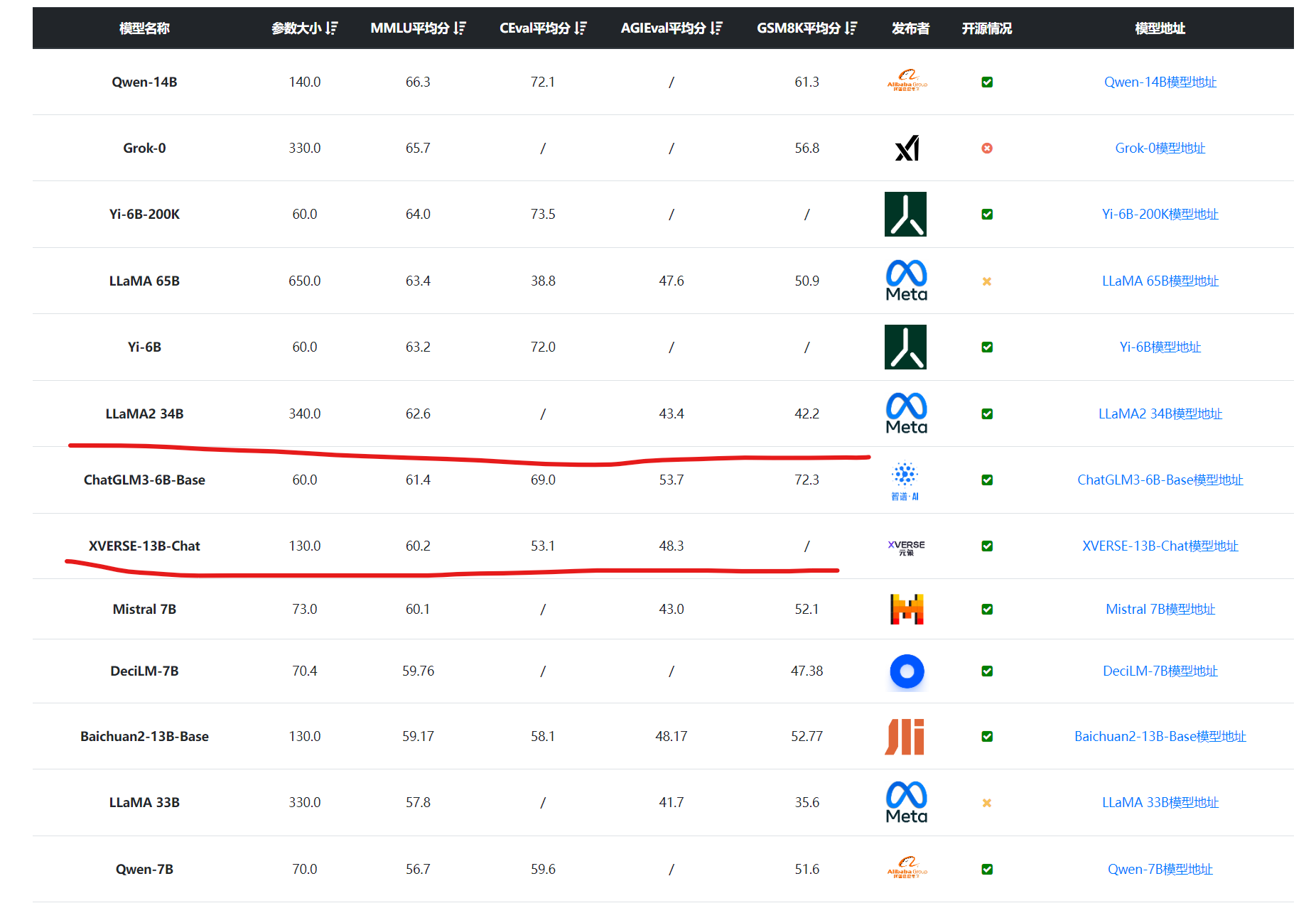
深圳的元象科技开源了一个最高上下文256K的大语言模型XVERSE-13B-256K,可以一次性处理25万字左右,是目前上下文长度最高的大模型,而且这个模型是以Apache2.0协议开源,完全免费商用授权。

在人工智能快速发展的今天,创新型模型如Mixtral 8x7B的出现,不仅推动了技术的进步,还为未来的AI应用开辟了新的可能性。这款基于Sparse Mixture of Experts(SMoE)架构的模型,不仅在技术层面上实现了创新,还在实际应用中展示了卓越的性能。尽管一个月前这个模型就发布,但是MistralAI今天才上传了这个模型的论文,我们可以看到更详细的信息。
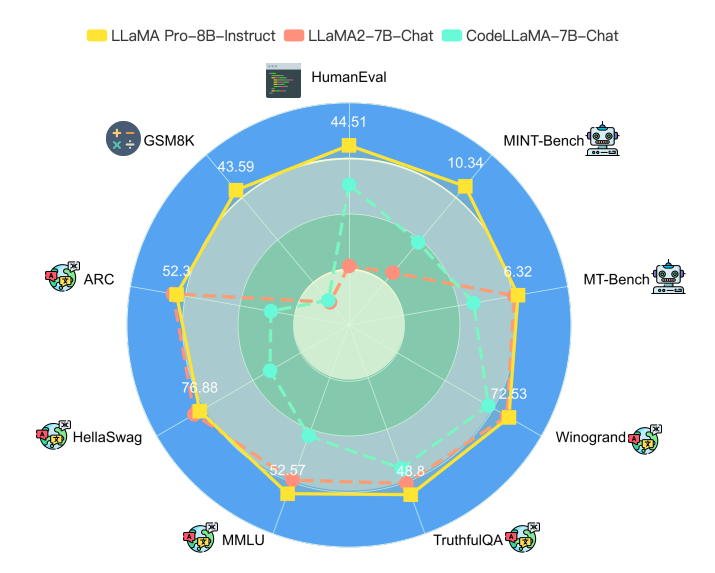
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。

GPTs是OpenAI推出的用户自定义的GPT功能,这里的GPTs可以认为是specific GPT。用户创建GPTs主要是通过OpenAI提供的GPT Builder完成。GPT Builder提供的最基本的能力就是基于对话的方式来帮助用户创建GPTs。那么,这个对话式的GPT背后的指令是什么?官方设置了什么样的Prompt来让GPT帮助普通用户建立GPTs呢?本文基于官方最新的博客介绍一下。

PerplexityAI是通过搜索引擎检索互联网的内容,然后使用大模型总结答案。产品形态有点像Bing的Bing Chat。圣诞节前夕,PerplexityAI提供了一个优惠代码,可以免费使用他们的2个月的Pro版本订阅服务。PerplexityAI的Pro版本提供GPT-4、Claude-2.1等大模型服务,支持生成图片和基于很长的PDF问答,这2个月的服务十分划算!

MistralAI开源的混合专家模型Mistral-7B×8-MoE在本周吸引了大量的关注。这个模型不仅是稍有的基于混合专家技术开源的大模型,而且有较高的性能、较低的推理成本、支持法语、德语等特性。昨天MistralAI发布的不仅仅是这个混合专家模型,还有他们的平台服务La plateforme。在这里他们透露了MistralAI还有更加强大的模型。

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。

MistralAI是一家法国的大模型初创企业,其2023年9月份发布的Mistral-7B模型声称是70亿参数规模模型中最强大的模型,并且由于其商用友好的开源协议,吸引了很多的关注。在昨晚,MistralAI突然在推特上公布了一个磁力下载链接,而下载之后大家发现这是一个基于混合专家的大模型这是由8个70亿参数规模专家网络组成的混合模型(Mixture of Experts,MoE,混合专家网络)。
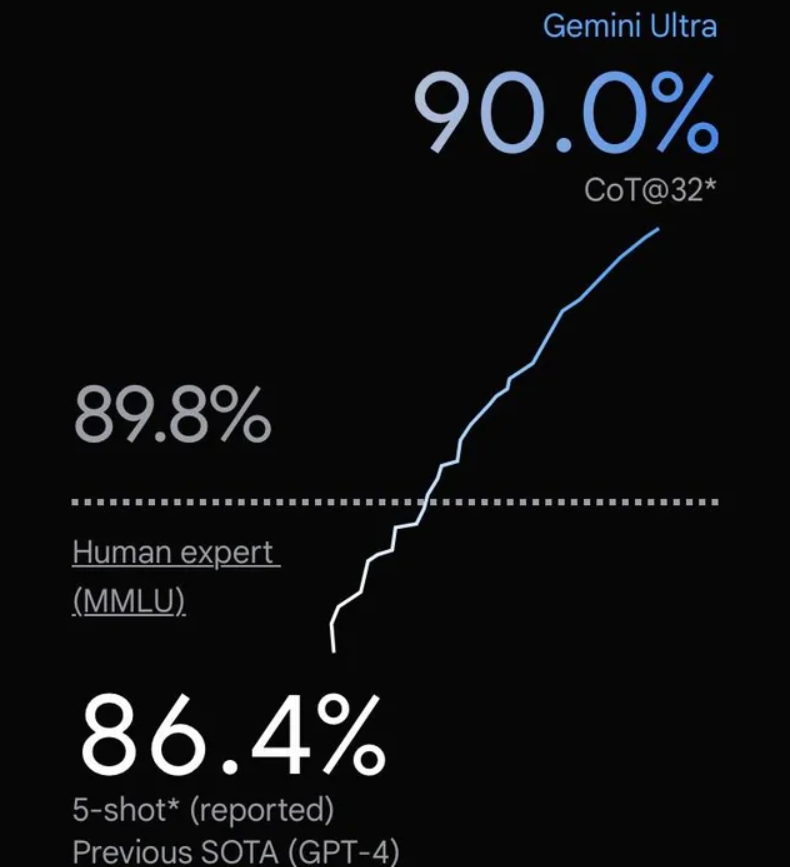
谷歌在几个小时前发布了Gemini大模型,号称历史最强的大模型。这是一系列的多模态的大模型,在各项评分中超过了GPT-4V,可能是目前最强的模型。
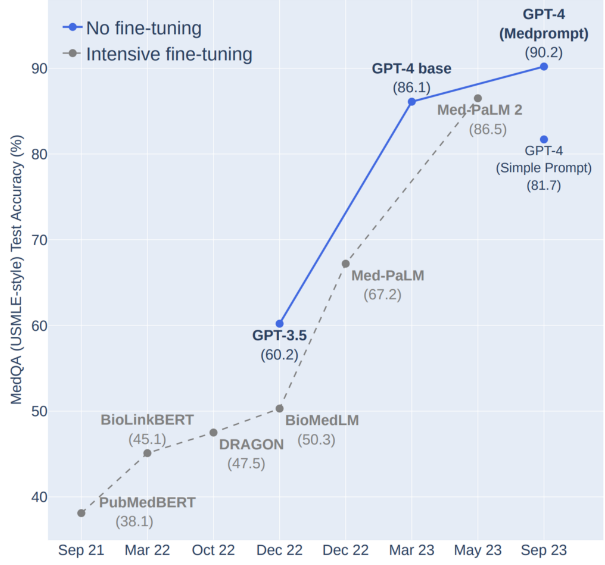
在GPT-4这种超大基座模型发布之后,一个非常活跃的方向是专有模型的发展。即一个普遍的观点认为,基座大模型虽然有很好的通用基础知识,但是对于专有的领域如医学、金融领域等,缺少专门的语料训练,因此可能表现并不那么好。如果我们使用专有数据训练一个领域大模型可能是一种非常好的思路,也是一种非常理想的商业策略。但是,微软最新的一个研究表明,通用基座大模型如果使用恰当的prompt,也许并不比专有模型差!同时,他们还提出了一个非常新颖的动态prompt生成策略,结合了领域数据,非常值得大家参考。

StabilityAI是当前最流行的开源文本生成图像大模型Stable Diffusion背后的公司。这家公司在文本生成图片和文本生成视频方面开源了诸多的大模型。其中,Stable Diffusion是目前使用人数最多的开源文本生成图像大模型。就在刚才,StabilityAI又发布了一个全新的实时的文本生成图像大模型Stable Diffusion XL Turbo,这个最新的模型在A100上生成一张图片只需要0.207秒!

OpenAI的董事会上周五开除Sam Altman,同日其创始人Greg Brockman,这件事引起了轩然大波。周末各方消息显示投资人施压董事会,要求召回Sam。本来大家以为Sam重回OpenAI。但是最新消息,OpenAI找了新的CEO,Sam与Greg等人加入微软成立新的团队。
最近自定义GPTs非常火热,出现了大量的自定义GPT,可以完成各种各样的有趣的任务。DataLearnerAI目前也创建了一个DataLearnerAI-GPT,目前可以回答大模型在不同评测任务上的得分结果。这些回答是基于OpenLLMLeaderboard数据回答的。未来会考虑增加更多信息,包括DataLearner网站上所有的大模型博客和技术介绍。

GPT-4 Turbo是OpenAI最新发布的号称性能超过当前GPT-4的模型。在新版本的ChatGPT中已经可以使用。而接口也在开放。除了速度和质量外,GPT-4 Turbo最吸引人的是支持128K超长上下文输入。但是,实际测试中GPT-4 Turbo对于超过73K tokens文档的理解能力急速下降。
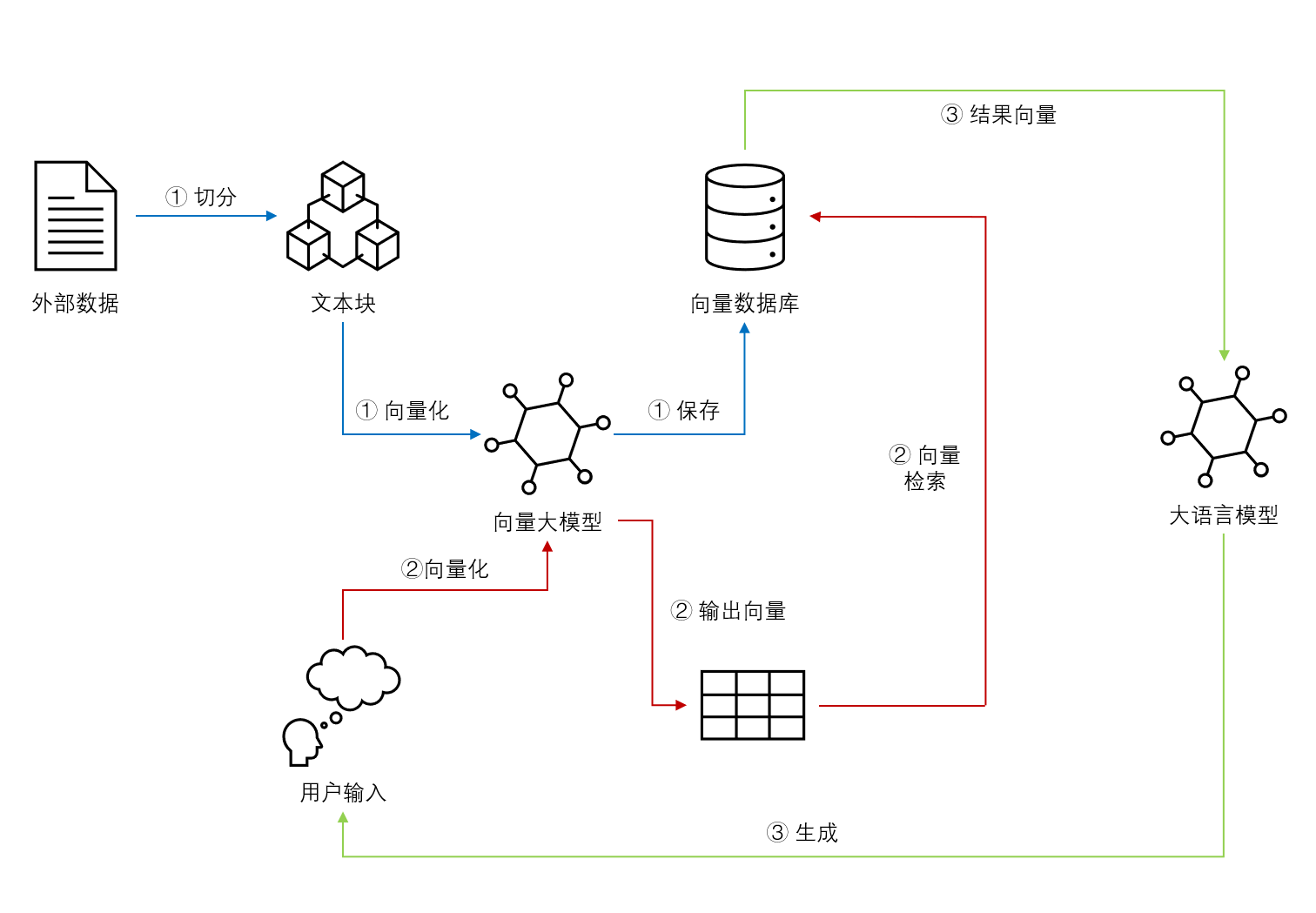
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。

OpenAI在发布了多模态的GPT-4V(GPT-4 with Vision)的接口,可以实现图像理解的功能(`Image-to-Text`)。这是OpenAI的第一个多模态接口,在以前的接口中,OpenAI都是文本大模型,相关的费用计算都是按照输入输出的tokens计算,虽然与一个单词多少钱有一点差异,但是也算直观。而GPT-4V是一个图像理解的接口,这里的费用计算不像文本的tokens那么直观,那么这个接口的费用计算逻辑是什么?这个计算逻辑透露了什么样的模型架构信息?本文将介绍这个问题。
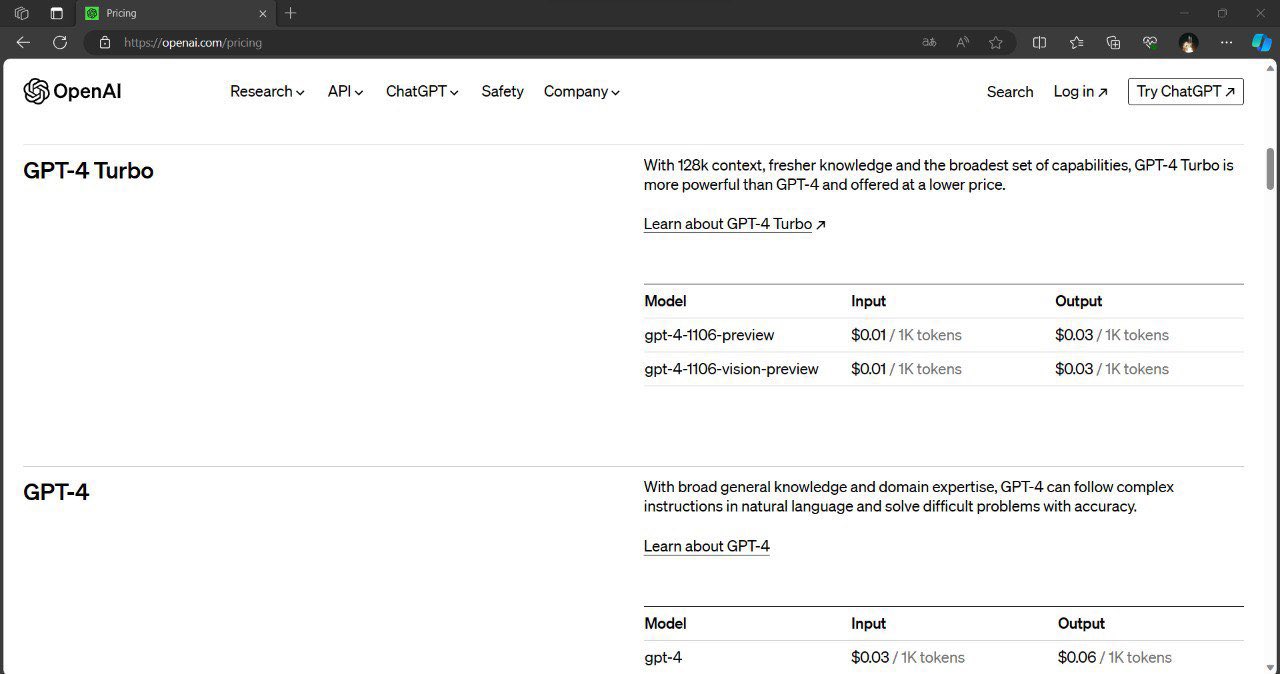
就在刚刚,有网友发现OpenAI的官方的文档接口更新中增加了128K的超长上下文版本,命名为GPT-4-128K-Turbo!

国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。

尽管OpenAI最早也是马斯克和别人一起创立,由于各种原因分道扬镳之后马斯克也没有对相关产品感兴趣,直到ChatGPT风卷全球之后,马斯克与OpenAI的人公开吵了几次之后成立了这家公司。半年后的现在,马斯克透露xAI即将发布它的首个大模型Grōk AI。而一位老哥已经透露了该模型的一些细节。

xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。xAI今天也宣布了Grok模型的细节。其在多个知名榜单评测上的得分结果超过了ChatGPT-3.5水平。本文详细介绍一下这个模型。