ChatGPT即将可以读取谷歌和微软的云盘数据为你管理私有数据!
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Drive和Microsoft 365两个。
汇总「R」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Drive和Microsoft 365两个。
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!
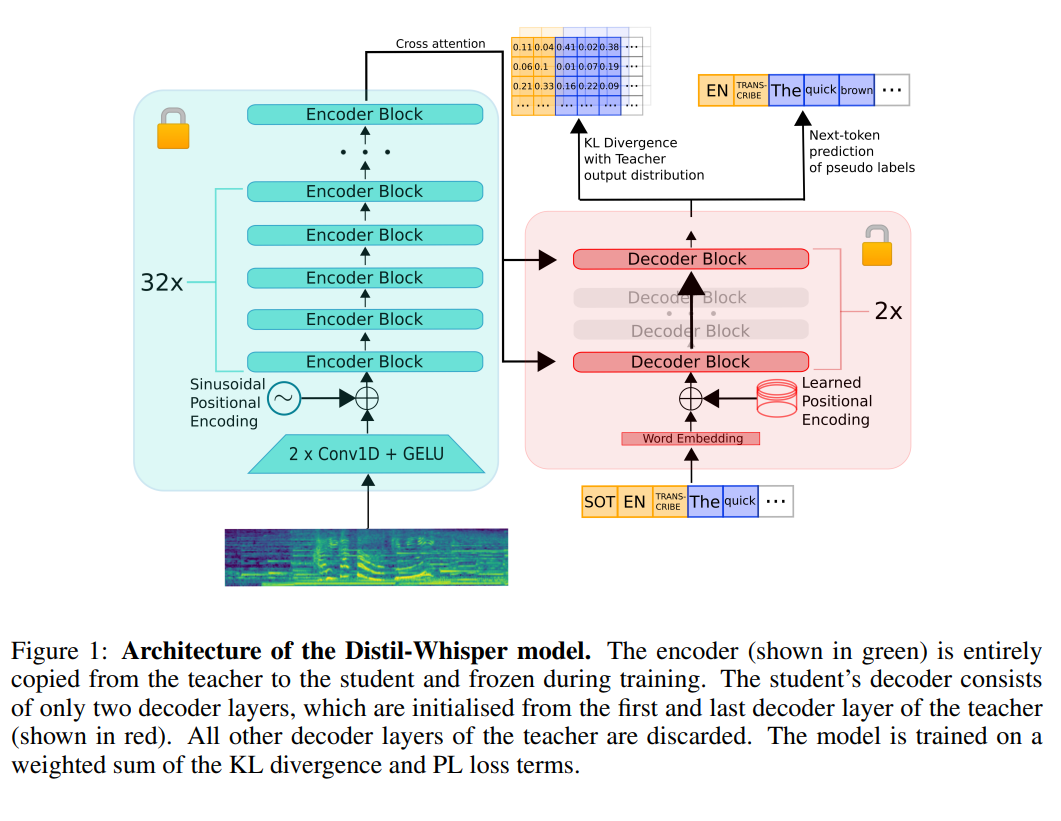
语音识别在实际应用中有非常多的应用。早先,OpenAI发布的Whisper模型是目前语音识别模型中最受关注的一类,也很可能是目前ChatGPT客户端语音识别背后的模型。HuggingFace基于Whisper训练并开源了一个全新的Distil-Whisper,它比Whisper-v2速度快6倍,参数小49%,而实际效果几乎没有区别。

检索增强生成(Retrieval-augmented Generation,RAG)是一种结合了检索和大模型生成的方法。它从一个大型知识库中检索与输入相关的信息,然后利用这些信息作为上下文和问题一起输入给大语言模型,并让大语言模型基于这些信息生成答案的方式。检索增强生成可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,但是,如果文档切分有问题、检索不准确,结果也是不好的。

检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。
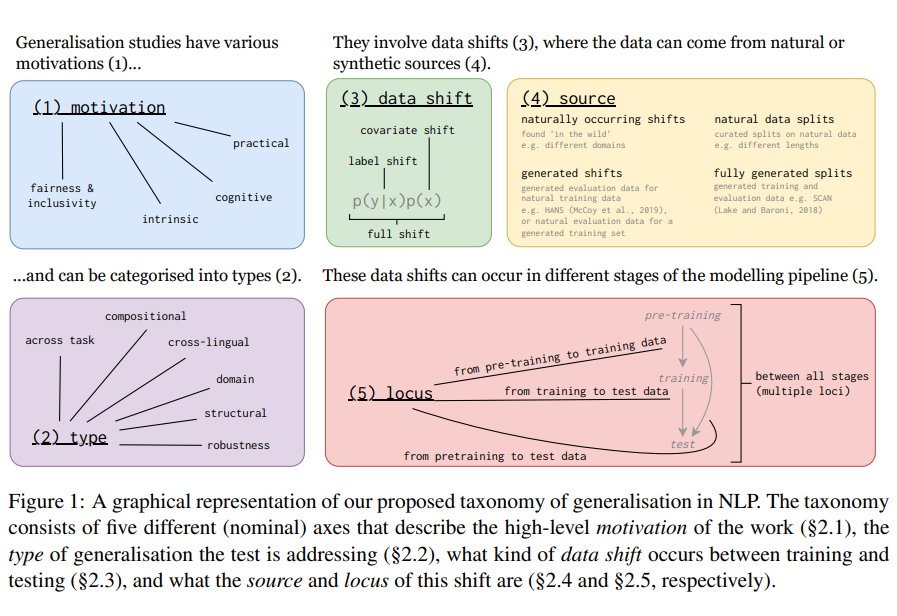
关于什么是好的泛化、存在哪些类型的泛化以及在不同的场景中哪些应该被优先考虑,人们对此了解甚少且意见不一。而MetaAI等机构的研究人员最近发布了一篇关于大模型泛化能力的综述,详细总结了大模型泛化能力的分类等。本篇论文详细总结一下大模型的泛化能力分类以及什么样的泛化是未来的中的重点等问题。

大模型的发展一个重要的基础条件是底层硬件计算能力的大幅提高,特别是GPU的发展,与transformer架构的大模型训练非常契合。当前全球最大的GPU供应商英伟达系列的显卡几乎垄断了大模型训练与推理的所有GPU芯片市场。除了英伟达显卡本身算力强悍外,基于英伟达GPU之上构建的CUDA、PyTorch等平台软件生态也是非常重要的一环。而最新的PyTorch2.1版本发布的一个beta特性中包含了对华为昇腾芯片的原生支持,这也是大模型生态多样性发展的一个很重要的信号。

上海人工智能实验室是国内顶尖的人工智能实验室,此前在大模型领域,他们与商汤科技发布的书生·浦语系列在国内引起了很大的关注。此次,他们又开源了一个全新的200亿参数规模的大语言模型InternLM 20B,应该是截止目前中文领域开源的参数规模最大的一个大模型了。
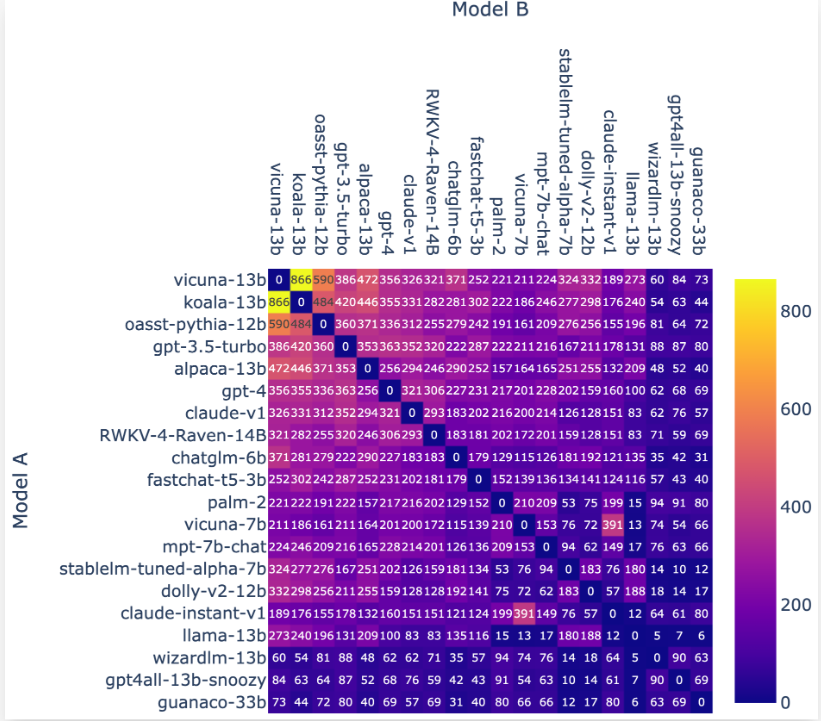
LM-SYS全称Large Model Systems Organization,是由加利福尼亚大学伯克利分校的学生和教师与加州大学圣地亚哥分校以及卡内基梅隆大学合作共同创立的开放式研究组织。该团队在2023年3月份成立,目前的工作是建立大模型的系统,是聊天机器人Vicuna的发布团队。今天开源 了包含3.3万包含真实人类偏好的对话数据集和3000条专家标注的对话数据集:Chatbot Arena Conversation Dataset和MT-bench人工注释对话数据集。

OpenAI最新发布了GPT-3.5-Turbo-Instruct,这是一款强大的指令遵循大模型。尽管官方没有发布官方博客介绍,但我们将在本文中详细探讨这一模型的特点以及其在人工智能领域的价值。
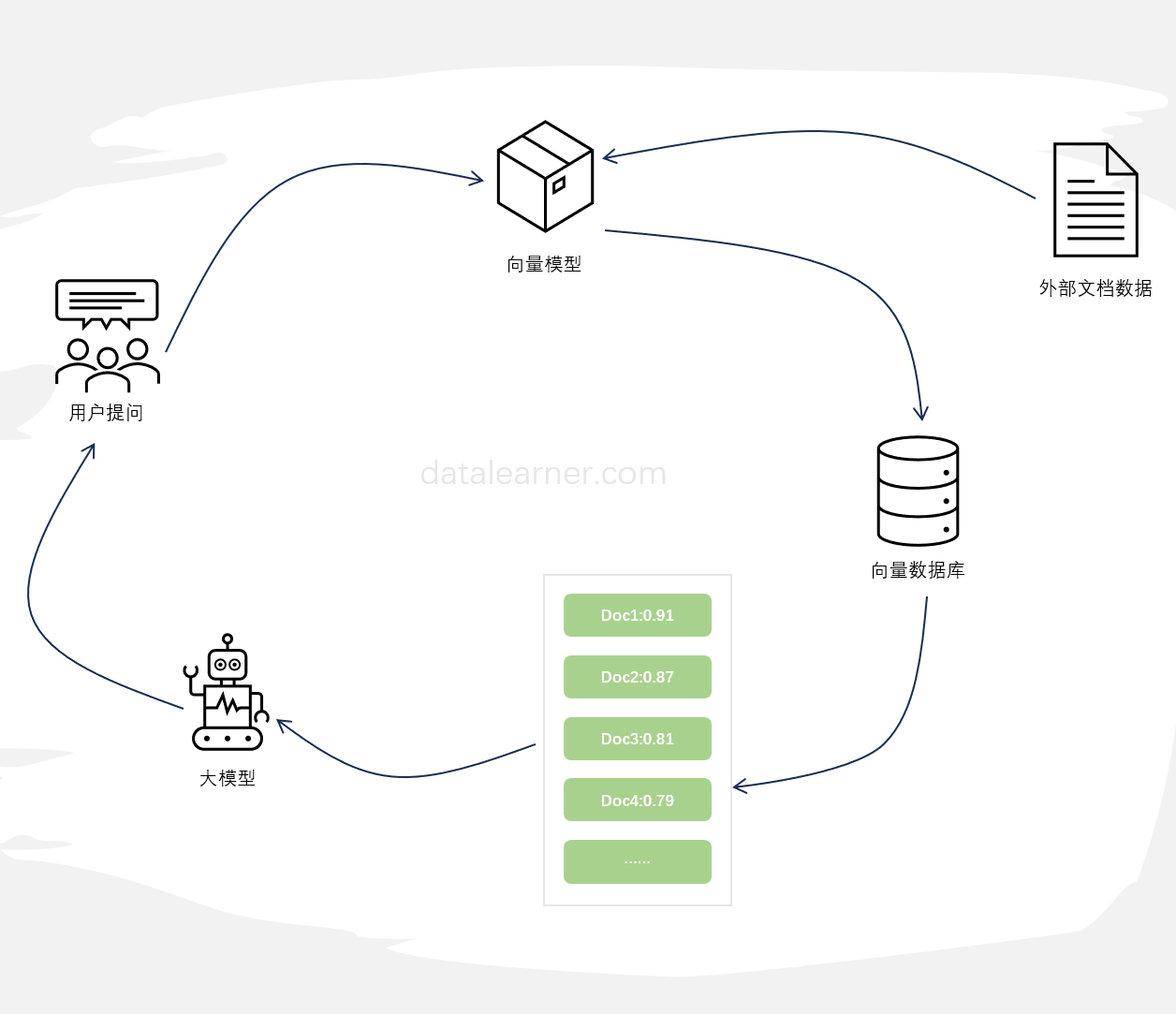
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。
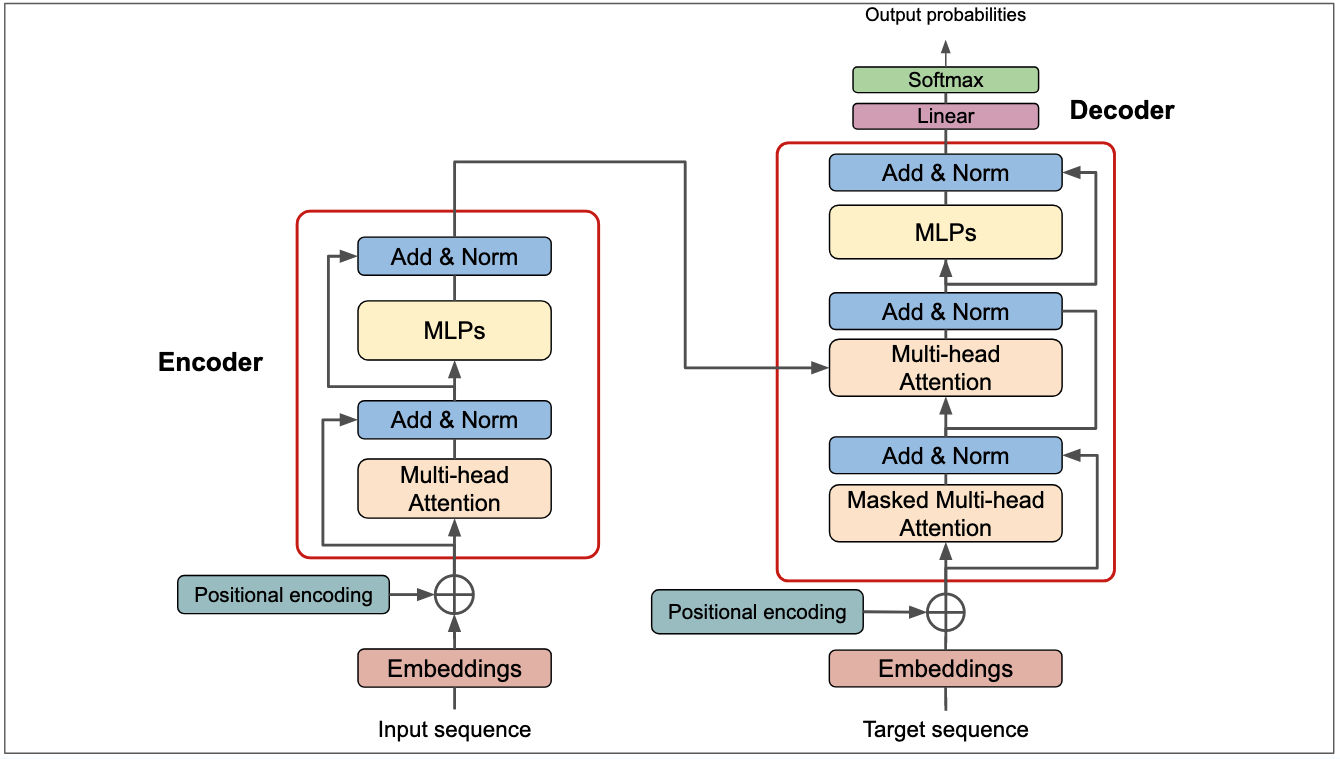
CMU的工程人工智能硕士学位的研究生Jean de Nyandwi近期发表了一篇博客,详细介绍了当前大语言模型主流架构Transformer的历史发展和当前现状。这篇博客非常长,超过了1万字,20多个图,涵盖了Transformer之前的架构和发展。此外,这篇长篇介绍里面的公式内容并不多,所以对于害怕数学的童鞋来说也是十分不错。本文是其翻译版本,欢迎大家仔细学习。
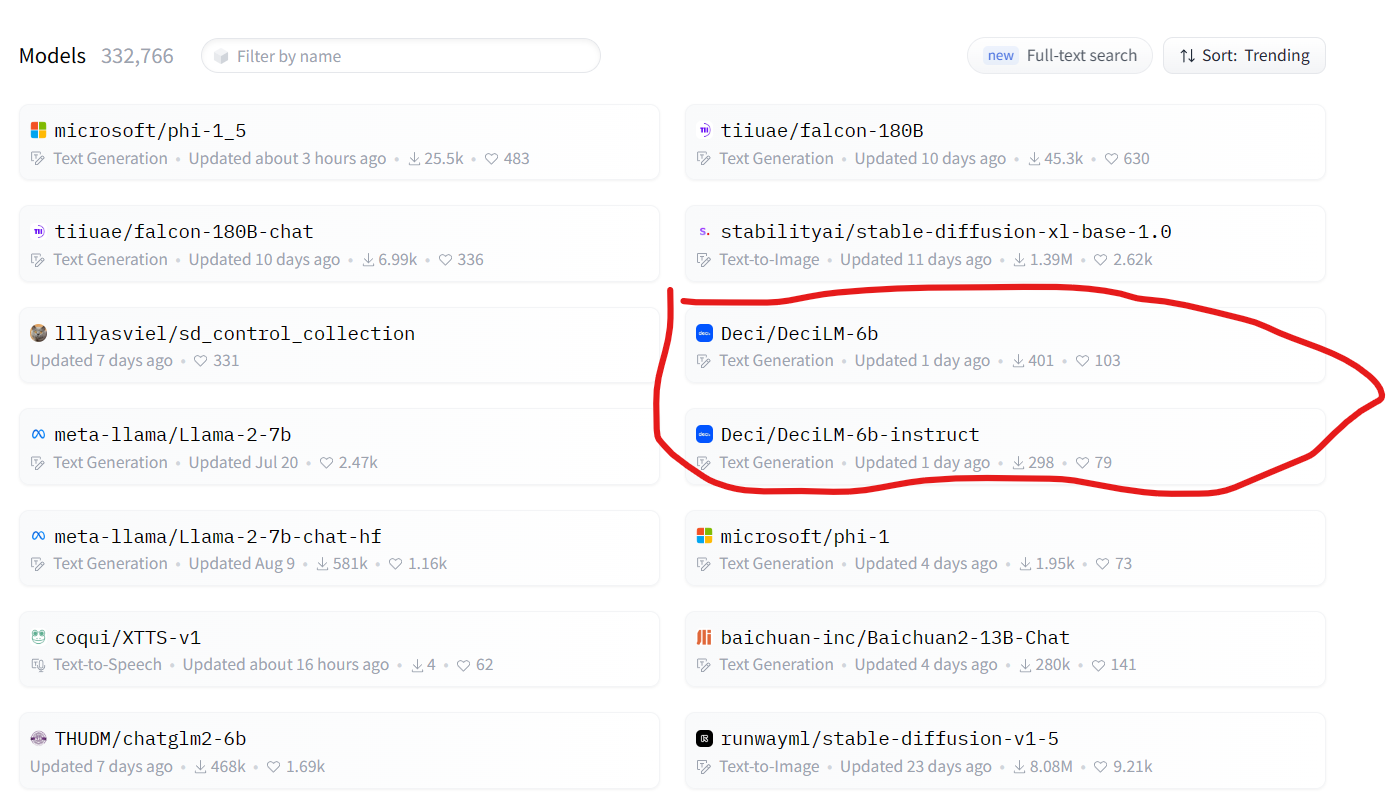
随着大型语言模型(LLMs)的不断发展,它们在训练和推理方面的计算需求已经呈指数级增长。这一趋势不仅带来了高昂的成本和能源消耗,还引入了模型部署和可伸缩性方面的障碍。为此,DeciLM开源了2个全新的DeciLM-6B和DeciLM-6B-Instruct大模型,参数比LLaMA2 7B略低,性能相当,但是推理速度却超过LLaMA2 7B的15倍。
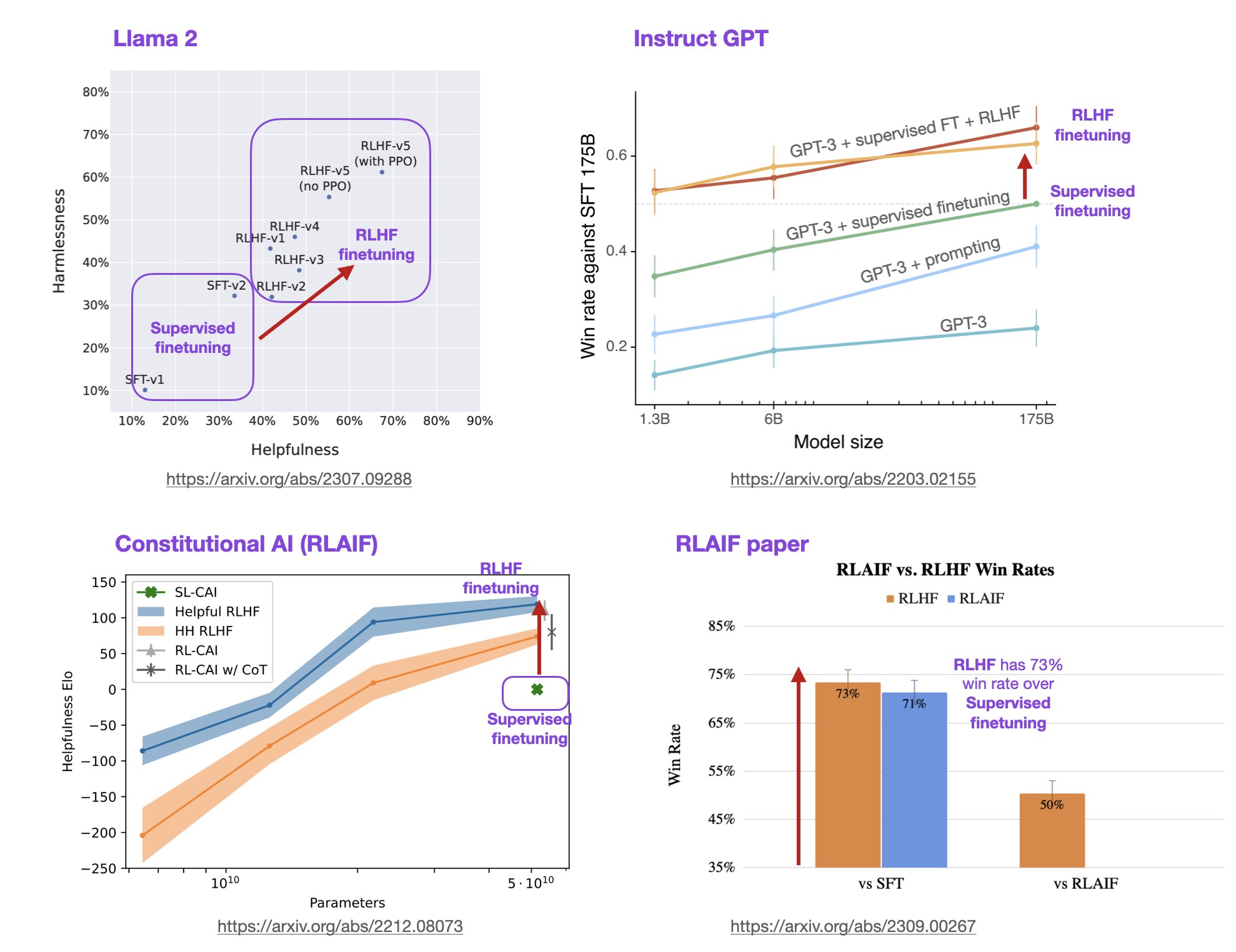
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。

随着大型语言模型(LLM)如 GPT-3 和 BERT 在 AI 领域的崛起,如何在实际应用中高效地进行模型推断成为了一个关键问题。为此,英伟达推出了全新的大模型推理提速框架TensorRT-LM,可以将现有的大模型推理速度提升4倍!
Anthropic公司宣布,其开发的智能助手Claude推出收费订阅服务,命名为Claude Pro,定价20美元一个月(或者18英镑)。免费用户依然可以使用,但是有发送频率限制。本篇博客将解释一下ClaudeAI的Claude服务是否收费以及收费之后的ClaudePro提供的服务等。

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。

Prompt技巧一直是提升ChatGPT等大语言模型使用效率的最重要方法之一。为此,OpenAI官方也在不断地分享官方的Prompt技巧。2023年的8月31日,OpenAI官方最新分享了一个教室使用的Prompt来帮助老师授课的案例。尽管这是针对老师的Prompt教程,但是其中的设计思路其实也可以广泛运用在客服、问答系统、编程等领域。

SQLCoder 是 Defog 团队推出的一款前沿的语言模型,专门用于将自然语言问题转化为 SQL 查询。这是一个拥有150亿参数的模型,其性能略微超过了 gpt-3.5-turbo 在自然语言到 SQL 生成任务上,并且显著地超越了所有流行的开源模型。更令人震惊的是,尽管 SQLCoder 的大小只有 text-davinci-003 的十分之一,但其性能却远超后者。

XVERSE-13B是元象开源的一个大语言模型,发布一周后就登顶HuggingFace流行趋势榜。该模型最大的特点是支持多语言,其中文和英文水平都十分优异,在评测结果上超过了Baichuan-13B,与ChatGLM2-12B差不多,不过ChatGLM2-12B是收费模型,而XVERSE-13B是免费商用授权!
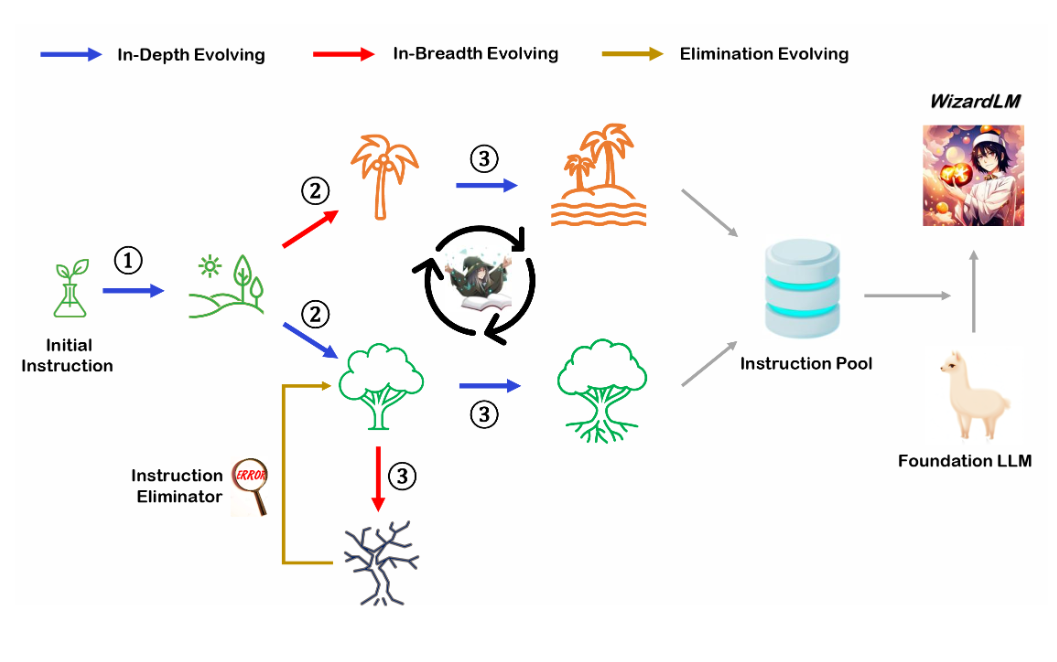
WizardLM是微软联合北京大学开源的一个大语言模型。此前,发布的WizardLM和WizardCoder都是业界开源领域最强的大模型。其中,前者是针对指令优化的大模型,而后者则是针对编程优化的大模型。而此次WizardMath则是他们发布的第三个大模型系列,主要是针对数学推理优化的大模型。在GSM8K的评测上,WizardMath得分超过了ChatGPT-3.5、Claude Instant-1等闭源商业模型,得分十分逆天!

文中整理和总结了几个关于开源大模型微调方面的问题,答案主要来自gpt4 + google,如果其中部分问题的答案不准确,烦劳指正 (文中引用了外部资源链接,如果涉及版权问题,烦劳联系作者删除)

在过去的几年里,我们看到了AI在图像、视频和文本生成方面的巨大进步。然而,音频生成领域的进展却相对滞后。MetaAI这次再为开源贡献重磅产品:AudioCraft,一个支持多个音频生成模型的音频生成开发框架。

ChatGPT是属于生成式AI的一种应用。由于其强大的效果已经变成了当前最主流的一种AI方案。而构建生成式AI应用的一个重要方向是构建友好的web形态的demo让用户能快速体验。Gradio就是这样一种开源方案,也是当前最流行的一种快速构建AI Web应用的方案。昨天吴恩达的DeepLearningAI与HuggingFace共同推出了最新的一期短课程《Building Generative AI Applications with Gradio》,教大家如何使用Gradio快速构建生成式AI的应用。