检索增强生成中的挑战详解:哪些因素影响了检索增强生成的质量?需要如何应对?
检索增强生成(Retrieval-augmented Generation,RAG)是一种结合了检索和大模型生成的方法。简单来说,它从一个大型知识库中检索与输入相关的信息,然后利用这些信息作为上下文和问题一起输入给大语言模型,并让大语言模型基于这些信息生成答案的方式。检索增强生成可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,但是,如果文档切分有问题、检索不准确,结果也是不好的。本文总结了检索增强中一些重点考虑的问题和影响因素供大家参考。

检索增强生成的典型流程
如前所述,在详细描述这些提高检索增强生成的方法之前,我们先简单介绍一下典型的检索增强生成的流程。
下图是由DataLearnerAI绘制的一个检索增强生成的典型流程,是基于向量检索的检索增强生成。
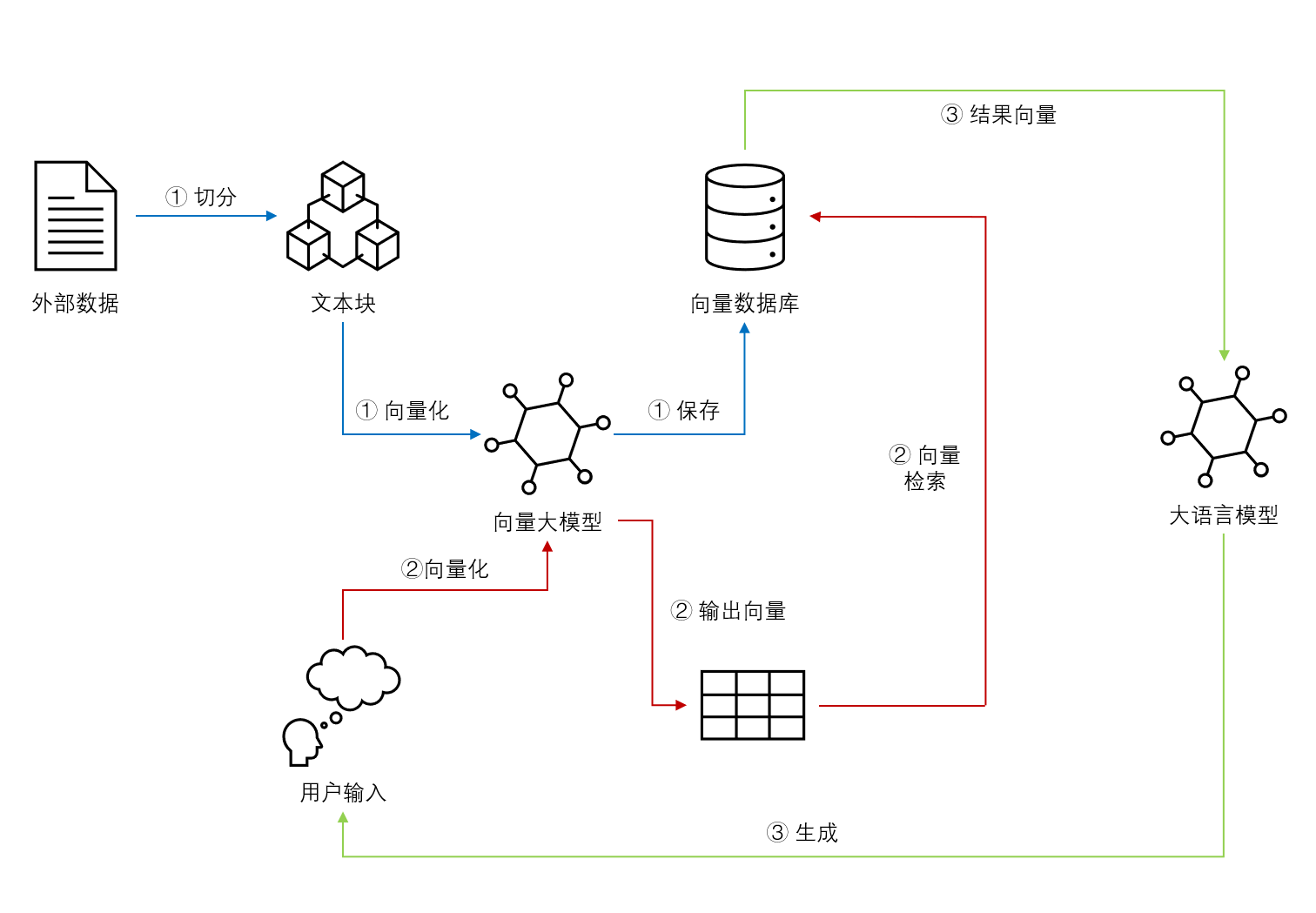
检索增强生成的核心要点就是通过检索相关的数据,将大模型没有的上下文背景知识或者是最新的数据与问题一同输入给大模型,让大模型生成结果。因此,典型的检索增强生成包含2个部分,一个是检索器(retrieval)和一个生成器(generator)。检索器主要负责检索相关的文本,生成器则是基于检索的结果进行生成。
在基于向量检索的检索增强生成中,通常包含3个主要的流程:
- 外部数据向量化:将外部数据按照某种逻辑分块后,对每一个数据块使用向量大模型进行向量化,并保存到向量数据库中。
- 用户查询检索:用户输入的问题,使用向量大模型向量化,然后从步骤1保存的向量数据库中检索最相关的结果。
- 大模型生成:将步骤2中的生成结果与问题一同发给大语言模型,大语言模型根据问题和上下文背景生成答案。
影响检索增强生成的主要因素
通过上面三个步骤,我们可以看到检索增强生成的主要可能产生问题的地方,总结如下:
检索系统质量
其实向量检索只是一种方法。对于检索增强来说,检索系统的好坏直接影响到最终的结果生成。只有检索到相关的内容,大模型才会有好的输出。当然,检索系统的选择也很多,包括传统的全文检索等都是非常好的方式。
我们总结如下:
这个表格提供了一个高层次的视角来看各种检索方法的优劣。在实际应用中,具体的情况可能会有所不同,并且可能需要根据具体的需求和上下文来调整和选择合适的方法。
而当前由于大模型的发展,文本向量的水平有了很大的提升,因此向量检索的方式十分流行。然而,这部分也并不是说完全可以解决我们的问题。
文档分块是否合理
外部数据的分块是否合理直接影响到检索结果,进而影响到最终的答案生成结果。大多数时候,外部知识都是非结构化的文本数据,检索最常见的一种形式就是向量检索。向量检索的第一步是数据向量化。即将数据分块之后用向量大模型转成向量格式存入向量数据库中。
在这里,由于向量大模型的输入长度限制,外部数据通常需要分块之后才能计算。以文本数据为例,如何切分文本数据,让一段文本数据块包含丰富的或者较为完整的逻辑信息,又不能太长就是一个非常复杂的问题。按照句子、段落等方式切分是一个自然的方式,但也可能会产生多样性和准确性的割裂问题。
具体来说可能需要考虑如下因素:
-
块的大小: 选择什么样的块大小是关键。太小可能导致丢失上下文信息,太大可能超出模型的输入限制或导致存储和计算上的挑战。
-
上下文连续性: 如何确保分块时不会丢失重要的上下文信息?例如,如果一个句子被分为两半并分别处于两个块中,这可能会影响向量化的质量。
-
重叠策略: 当分块时,是否应该有重叠,以捕获块之间的上下文信息?这会增加处理的复杂性,但可能会提高结果的质量。
-
块内的连贯性: 确保每个块在语义上都是连贯的。例如,避免仅根据固定长度来切分文本,这可能导致在句子中间断开。
-
多样性和代表性: 如何确保分块后的文本集能够代表整个文档的多样性和核心思想?
-
计算效率: 分块增加了处理的数量,可能会对向量化的计算效率产生影响。
-
块的聚合: 在对每个块进行向量化后,如何聚合这些向量来代表整个文档?简单的方法包括平均或最大化,但可能还需要更复杂的策略。
-
元数据和块信息: 在分块时,可能需要存储与每个块相关的元数据,例如块在原始文档中的位置,以便后续的处理或引用。
-
动态内容和更新: 如果文档经常更新或更改,如何有效地重新分块和向量化?
-
选择合适的向量化模型: 不同的模型可能对文本长度和上下文信息有不同的敏感度。选择一个适合分块策略的模型是很重要的。
考虑到这些问题和挑战,进行文本分块的策略选择和实施是一个需要仔细考虑的步骤,它会直接影响到向量化的效果和后续检索的质量。
向量检索匹配准确性问题
如前所述,基于向量检索增强生成的解决方案中,向量化的下一步的核心就是检索的准确性。当我们将外部知识向量化存入向量数据库中,我们需要以同样的方式来对用户的输入进行向量化,并与向量数据库中的数据进行向量匹配。这里面也会涉及到向量匹配的准确性问题,主要包括如下几个因素:
使用向量检索(例如,通过将文档或查询转化为密集向量并使用近似最近邻查找技术)确实有很多优势,特别是与深度学习模型如BERT、Word2Vec或FastText等一起使用时。但同时,它也带来了一些挑战和问题:
-
向量表示的质量: 不是所有的向量化方法都适用于所有的任务。选择或训练一个合适的模型对于检索质量至关重要。而甚至如果通用的向量大模型没有见过私有数据,甚至可能需要考虑向量大模型的微调才能更好地进行向量化匹配。
-
维度的诅咒: “维度诅咒”(Curse of Dimensionality)是一个在多维数据分析中经常遇到的问题。这个术语最早由Richard Bellman在1960s提出,用来描述随着数据维度的增加,数据分析的困难度也随之增加。在高维空间中,所有点之间的距离都变得非常相近。这使得在高维空间中区分“近”和“远”的点变得非常困难。例如,欧氏距离在高维空间中的区分度变差。因此,在高维空间中,所有的点对于其他点来说都看起来差不多“远”。这可能导致近似最近邻搜索的效果不佳。
-
查询和文档的不匹配: 有时,即使查询和文档的向量在空间中很接近,它们的含义也可能不匹配。
-
稀疏性问题: 虽然向量通常是密集的,但某些信息可能在转换过程中丢失,导致某些相关文档被遗漏。
-
冷启动问题: 对于新的或罕见的查询,可能没有足够的历史数据来生成高质量的向量表示。
总的来说,虽然向量检索为高效和语义丰富的检索带来了巨大的机会,但是就算是准确性方面也有很多挑战。
检索增强生成中其它需要考虑的问题
除了上述的向量化与向量检索的准确性问题外,其实还有一些问题也很重要。对于构建一个强大的向量检索增强生成来说也是非常重要的。
-
计算和存储成本: 转换大量文档为向量表示需要时间和计算资源。 存储大量高维度的向量可能会增加存储成本。
-
实时更新: 当数据集经常更新时(例如新的文档加入),需要频繁地重新计算和索引向量,这可能是资源密集型的。
-
Lost in middles问题: 这部分主要是最近有研究发现,检索增强生成通常使用检索结果按照相关性排序发给大模型去生成结果,但是当前主流的大模型很多都更多关注内容的开始与结束部分,中间部分即便是有价值的信息,可能也会忽略,因此,即使传统最自然的相关性排序可能在新的大模型系统下也会出现问题。这部分可以参考前面DataLearnerAI详细的介绍:大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处!
-
多模态数据: 如果数据来源是多模态的(如文本、图像、声音等),将它们整合到一个统一的向量表示中可能会增加复杂性。
总结
从前面的介绍可以看到,检索增强生成虽然是一个非常优秀的解决大模型与外部数据连接的方案,但是实际应用中有很多的问题需要考虑。而上面所总结的大多数问题还出现在向量检索阶段。只有Lost in middles问题提到了生成部分。原因并不是生成没有问题,而是生成部分的问题可能更多地与大模型自身的能力有关,因此没有详细列举。但其实,检索结果数量、检索的多样性、检索结果的排序等可能也有很多需要实际考虑的。这里不再赘述。
DataLearnerAI还介绍了一些提升当前向量检索增强生成的实际方案供大家参考:https://www.datalearner.com/blog/1051698375259477
