Google DeepMind 发布 EmbeddingGemma:面向端侧的多语言开源向量模型(308M),小体量也能打
EmbeddingGemma 是基于 Gemma 3 架构打造的全新开源多语言向量模型,专为移动端/本地离线应用而生。它以约 308M 参数的紧凑体量,在 RAG、语义搜索、分类、聚类等任务上提供高质量表征,同时将隐私与可用性拉满:无需联网即可在本地生成向量。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
EmbeddingGemma 是基于 Gemma 3 架构打造的全新开源多语言向量模型,专为移动端/本地离线应用而生。它以约 308M 参数的紧凑体量,在 RAG、语义搜索、分类、聚类等任务上提供高质量表征,同时将隐私与可用性拉满:无需联网即可在本地生成向量。
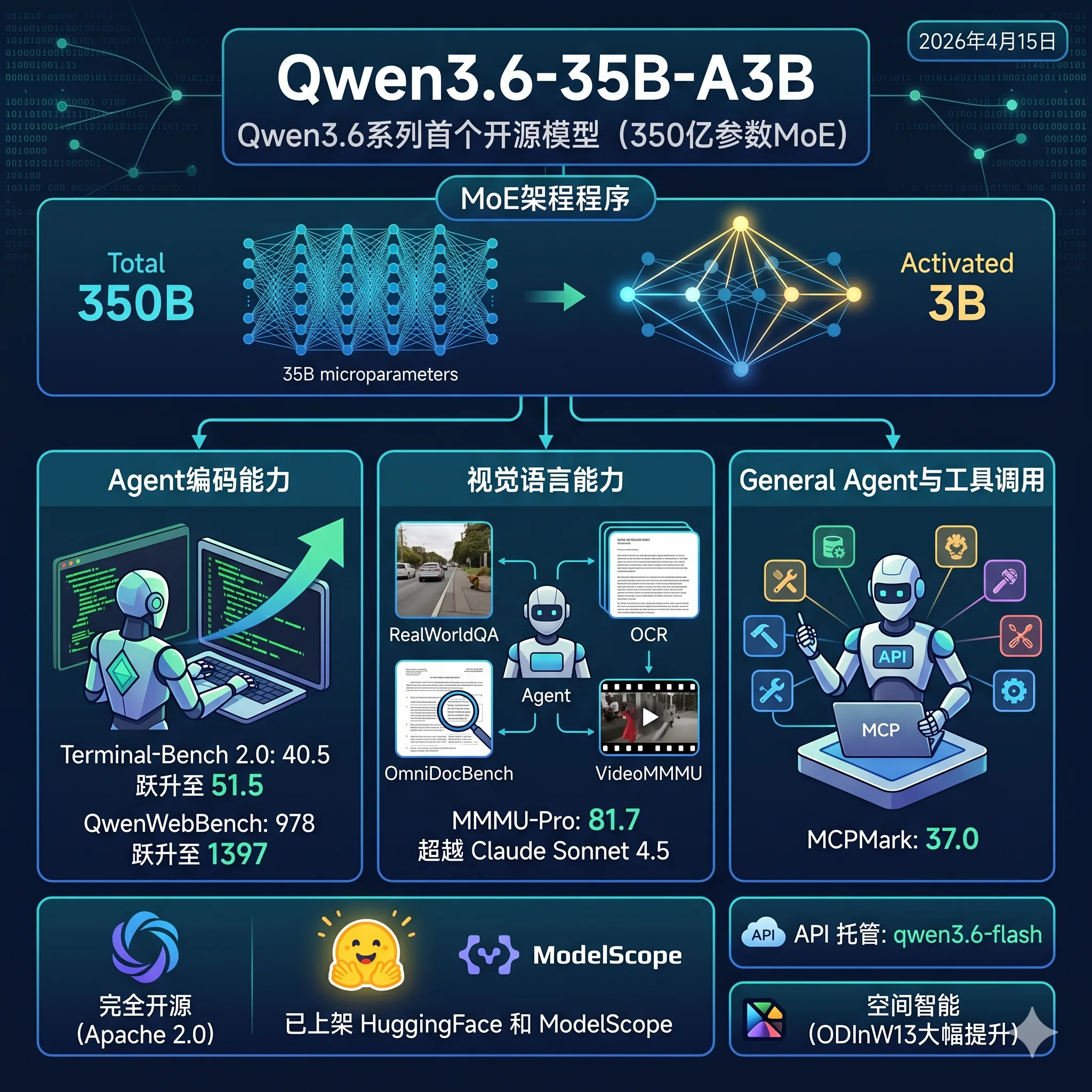
阿里开源Qwen3.6-35B-A3B,350亿总参数仅激活30亿,Terminal-Bench 2.0得分51.5,SWE-bench Verified 73.4,视觉多项超越Claude Sonnet 4.5,Apache 2.0开源。

智谱AI于2025年7月发布了Zread。这款产品能够利用其大模型能力,结合类似Deep Research的Agent技术,对GitHub项目进行深度解读和问答。其价值在于将强大的模型能力通过优秀的工程化设计,变成了一个真正“好用”的工具。它解决的正是那种“代码就在那里,但我就是看不懂”的尴尬,这种体验是单纯聊天机器人无法替代的。

就在刚才,Google宣布发布最新的图像生成和编辑大模型Gemini 2.5 Flash Image Preview。该模型就是最近火爆网络的Nana Banana背后真正的模型。该模型在图片生成和编辑方面目前是断层领先,效果非常好。

人工智能(AI)的通用智能(AGI)发展一直是研究领域的焦点。近期,由 ARC Prize 基金会推出并由 AI 研究者 François Chollet 联合发起的 ARC-AGI-2 评测基准,为衡量大模型在未知情境下的实时推理能力和学习效率提供了新的视角。

上周五,OpenAI董事会突然把Sam开除的事件已经结束,闹了好几天之后Sam回归,董事会改组。而这件事的背后导火索有许多传闻,其中最重要的一个是OpenAI可能在最近有一项重大的技术突破,被认为是Sam和董事会分歧的重要原因。而今天,国外的路透社独家消息提到OpenAI内部一个称为Q\*(Q Star)项目取得了非常重大的突破,使得部分人认为AGI很接近,进而引发了一系列事件。本文将根据目前的信息汇总介绍一下Q\*项目。

尽管各家大模型技术进展神速,但是在复杂任务的推理上,大模型目前依然较弱。在去年底,各方消息透露,OpenAI内部有一个称为Q\*的项目取得了重大的突破,可以大幅提高大模型的推理能力。但是,几个月过去了,这个当时吸引了大量讨论的项目没有任何信息。直到昨天,Reuters披露了Q\*项目的进展,这个项目已经变为Strawberry!并且距离发布时间更近了!
随着大型语言模型(LLM)能力的飞速发展,如何科学、准确地评估其性能,特别是深度的逻辑推理和代码生成能力,已成为人工智能领域的一大挑战。传统的评测基准在面对日益强大的模型时,逐渐暴露出数据污染、难度不足、无法有效评估真实推理能力等问题。在这一背景下,一个旨在检验模型竞赛级编程水平的评测基准——Codeforces应运而生,为我们提供了一个更严苛、更接近人类程序员真实水平的竞技场。

几个小时前,阿里一次更新了3个大模型,分别是开源的全模态大模型Qwen3-Omni、开源的图像编辑大模型Qwen3-Image-Edit和不开源的语音识别大模型Qwen3-TTS。本次发布的3个模型均为多模态大模型,可以说阿里的大模型真的是全面开花,节奏很快!
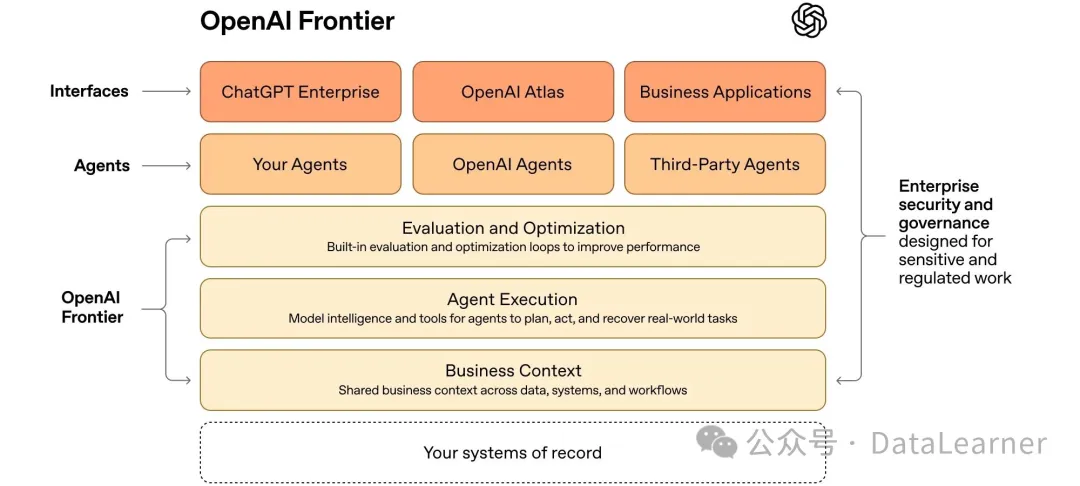
OpenAI 发布了一个全新的帮助企业构建AI Agent的平台:OpenAI Frontier。这个平台不再是一个强大的模型或者单体应用,而是一种“基础设施能力”,是旨在改变企业如何使用 AI 的平台。
随着大型语言模型(LLM)的飞速发展,如何准确、全面地评估它们的能力成为了一个日益重要的课题。在众多评测基准中,Simple Bench 以其独特的定位脱颖而出,它专注于检验模型在日常人类推理方面的能力,而在这些方面,当前最先进的模型往往还不如普通人。本文将详细介绍 Simple Bench 评测基准,探讨其出现的背景、设计理念、评测流程以及当前主流模型的表现。
IMO-Bench 是 Google DeepMind 开发的一套基准测试套件,针对国际数学奥林匹克(IMO)水平的数学问题设计,用于评估大型语言模型在数学推理方面的能力。该基准包括三个子基准:AnswerBench、ProofBench 和 GradingBench,涵盖从短答案验证到完整证明生成和评分的全过程。发布于 2025 年 11 月,该基准通过专家审核的问题集,帮助模型实现 IMO 金牌级别的性能,并提供自动评分机制以支持大规模评估。
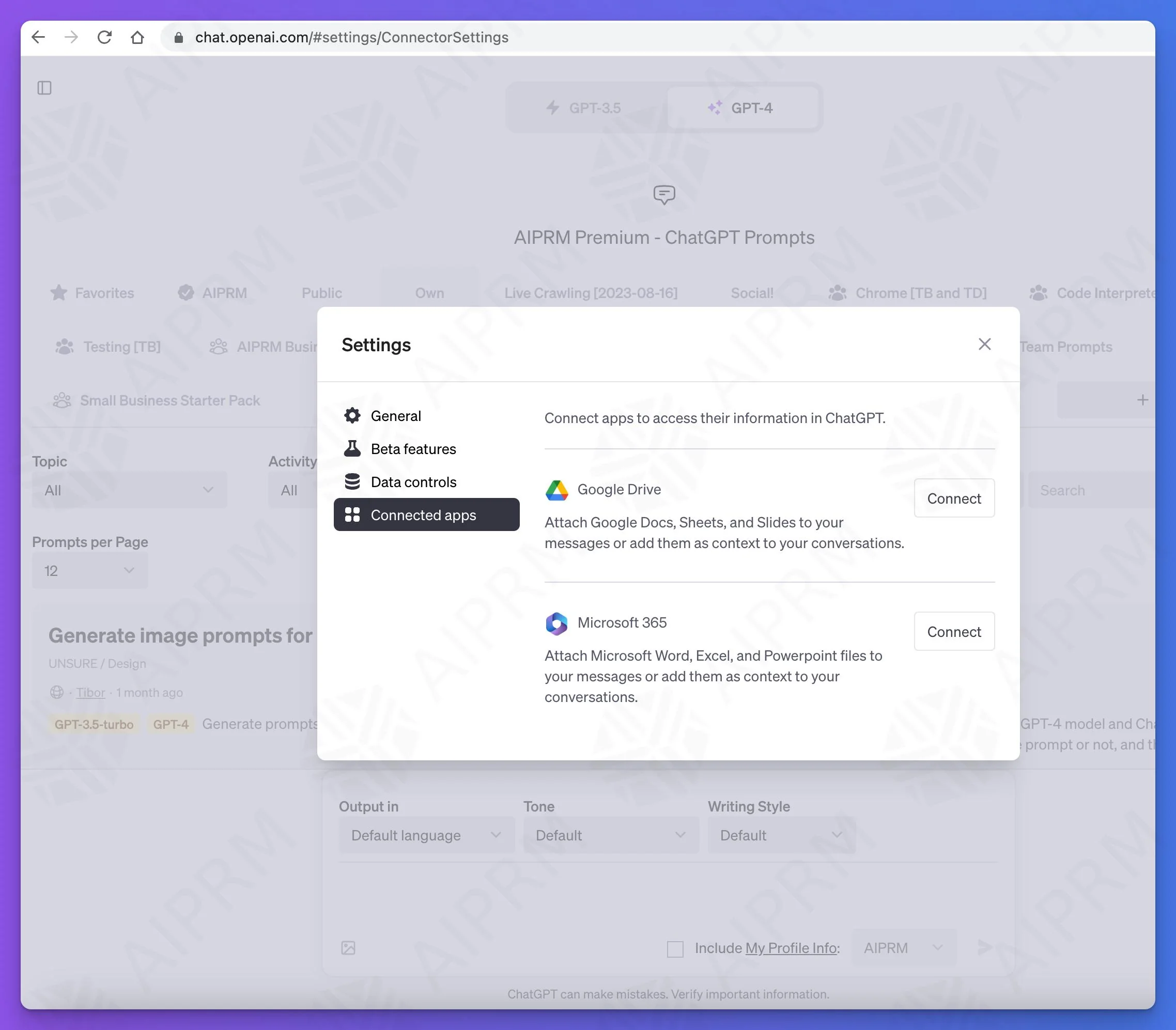
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Drive和Microsoft 365两个。

就在几个小时前,OpenAI 发布了全新的 GPT Realtime 大模型。这是一个 Speech-to-Speech(S2S)模型,能通过单个模型与 API完成从音频输入到音频输出的全流程,显著降低交互延迟并充分保留语音细节。 GPT Realtime 以“端到端语音理解—推理—合成”为核心路径,解决了传统“识别—推理—合成”多阶段带来的延迟与风格割裂问题。
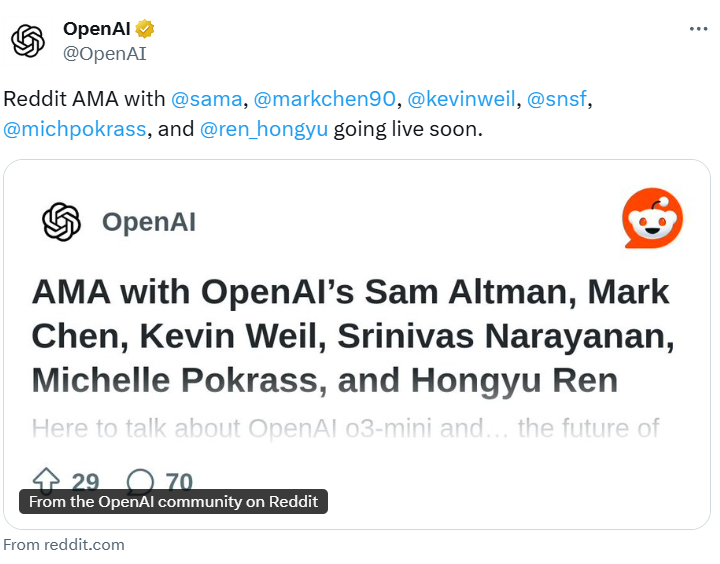
2025年1月31日,OpenAI在Reddit上举办了一场AMA(Ask Me Anything)活动,参与者包括Sam Altman、Mark Chen、Kevin Weil、Srinivas Narayanan、Michelle Pokrass和Hongyu Ren。他们分享了关于模型更新、未来功能、定价策略以及OpenAI对AI和AGI(通用人工智能)的宏观愿景。以下是此次问答的关键内容,并附有相关解释。这里最重要的信息可能是Sam透露认为当前OpenAI的闭源方式可能是历史错误的一方!

MLOps的主要目标是创建一个更有效、可重复和可靠的机器学习工作流程。现在,随着大语言模型的流行,LLMOps概念也随之提出。即如何高效地开发大模型应用,包括自动化管理升级如prompt、模型评估等。为此,吴恩达联合Google的研发人员推出了最新的大模型短课LLMOps,帮助大家学习大语言模型开发过程中的自动化测试、自动化Prompt管理等一系列实践,提高大模型应用开发的效率和质量。
unyang 是前 Qwen(通义千问)负责人,前段时间他的离职造成了许多人的关注。不过他并未沉寂,就在刚才,Junyang 发表了一篇关于如何训练大模型推理能力、以及未来大模型推理能力训练应该走向何方的深度讨论。

OpenAI正在申请一个新商标Voice Engine,商标的覆盖范围主要是围绕语音识别、语音合成和语音生成几个方面。这暗示着OpenAI可能即将推出围绕语音引擎开发的产品或者服务,很有可能是类似Siri那样的个人助理产品。尽管这是商标申请,但是谷歌前雇员透露的信息以及上个月泄露的OpenAI正在开发的产品都似乎印证着OpenAI要做的事情:开发一个全球最强的个人助理,接管个人设备,以Jarvis那样的形式提供服务!

LiveBench是一个针对大型语言模型(LLM)的基准测试框架。该框架通过每月更新基于近期来源的问题集来评估模型性能。问题集涵盖数学、编码、推理、语言理解、指令遵循和数据分析等类别。LiveBench采用自动评分机制,确保评估基于客观事实而非主观判断。基准测试的总问题数量约为1000个,每月替换约1/6的问题,以维持测试的有效性。

GPT-5 在指令遵循和推理能力上比前代更强,但也因此更“敏感”:如果规则里有冲突或表述过度强硬,模型往往会卡壳或输出异常。为此,OpenAI 发布了面向开发者的 《GPT-5 for Coding》技巧小抄,其中总结了使用 GPT-5 进行编程与代码生成时最实用的六条经验。这些技巧与普通的“写作提示工程”不同,它们专门针对软件开发场景:如何写规则、怎样控制推理强度、如何避免模型“想太多”,以及怎样利用 GPT-5 的新特性把它真正驯化成可靠的结对编程伙伴。本文对这六条技巧逐条进行解释总结。
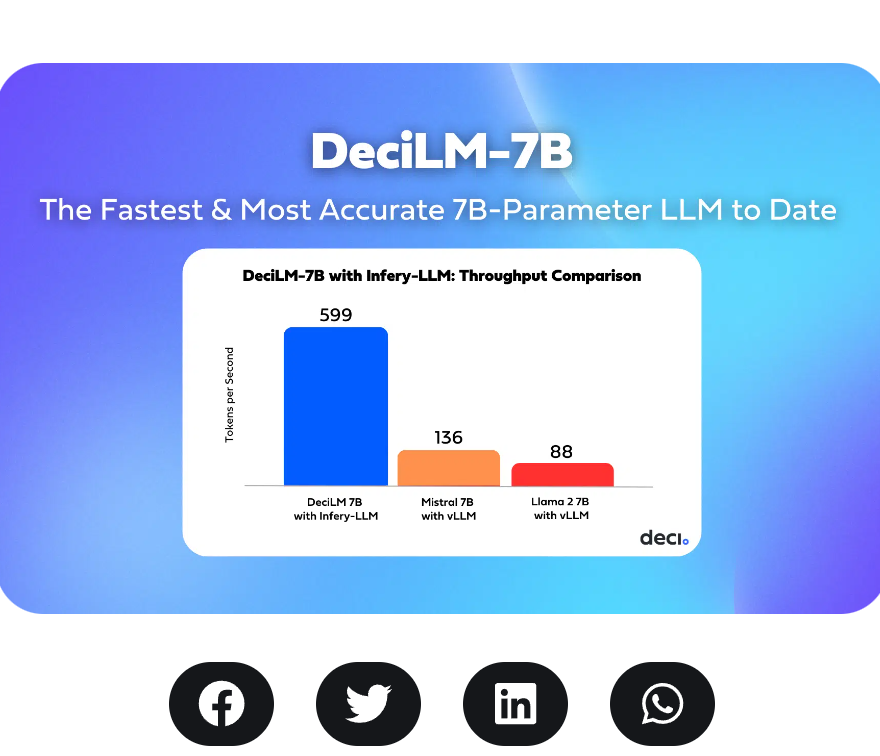
DeciAI是一家成立于2019年的以色列企业,他们最主要的产品是深度学习平台Deci,可以让大家部署运行更快、更准确的模型。包括Adobe、HPE等都是他们的客户。在昨天,他们开源了截止目前可能是Open LLM Leader综合评分最高的大语言模型DeciLM-7B以及指令优化版本的DeciLM-7B-Instruct。最重要的是,这个模型以Apache2.0的协议开源,可以免费商用。
BrowseComp是一个用于评估AI代理网页浏览能力的基准测试。它包含1266个问题,这些问题要求代理在互联网上导航以查找难以发现的信息。该基准关注代理在处理多跳事实和纠缠信息时的持久性和创造性。OpenAI于2025年4月10日发布此基准,并将其开源在GitHub仓库中。

就在今日,Google 正式推出 Veo 3.1 和 Veo 3.1 Fast,这两款升级版视频生成模型以付费预览形式登陆 Gemini API。Veo 3.1的核心亮点是:更丰富的原生音频(从自然对话到同步音效)、更强的电影风格理解与叙事控制、以及显著增强的图生视频(Image-to-Video)质量与一致性。