
为什么Python可以处理任意长度的整数运算——Python原理详解
在做LeetCode题目的时候,有一类题目是关于大数运算的。比如,全排列计算或者组合运算,在使用C语言或者Java代码解决这类问题的时候都会遇到变量数值超过阈值的情况。一般来说需要自己构造字符串数组或者是其它数组来存储超过长度的数值。但是,使用Python语言处理这类问题时候却毫无压力,这类题目的计算不会有任何问题。本文将从Python底层实现解释这个问题。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
在做LeetCode题目的时候,有一类题目是关于大数运算的。比如,全排列计算或者组合运算,在使用C语言或者Java代码解决这类问题的时候都会遇到变量数值超过阈值的情况。一般来说需要自己构造字符串数组或者是其它数组来存储超过长度的数值。但是,使用Python语言处理这类问题时候却毫无压力,这类题目的计算不会有任何问题。本文将从Python底层实现解释这个问题。

自从苹果发布M1系列的自研芯片开始,基于ARM架构的电脑处理器开始大放异彩。而强大的M1芯片的能力也让很多Mac用户高兴很久。而就在现在,M1也开始支持PyTorch的深度学习框架了。PyTorch官网刚刚宣布,经过和Apple的Metal工程师队伍的合作,PyTorch支持Mac的GPU加速了。
本周,谷歌的研究人员在arXiv上提交了一个非常有意思的论文,其主要目的就是分享了他们建立能够翻译一千多种语言的机器翻译系统的经验和努力。
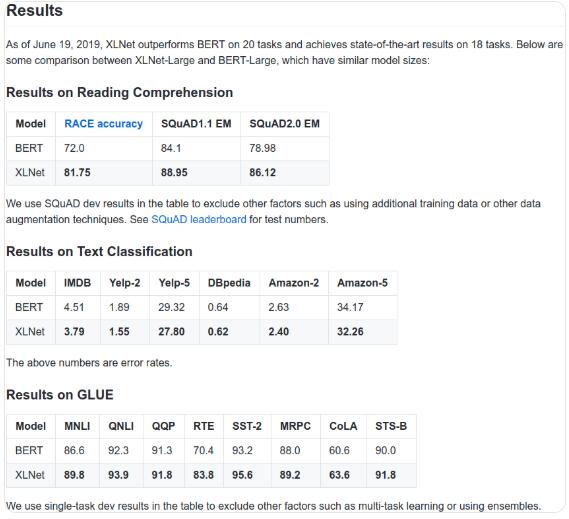
前几天刚刚发布的XLNet彻底火了,原因是它在20多项任务中超越了BERT。这是一个非常让人惊讶的结果。之前我们也说过,在斯坦福问答系统中,XLNet也取得了目前单模型第一的成绩(总排名第四,前三个模型都是集成模型)。
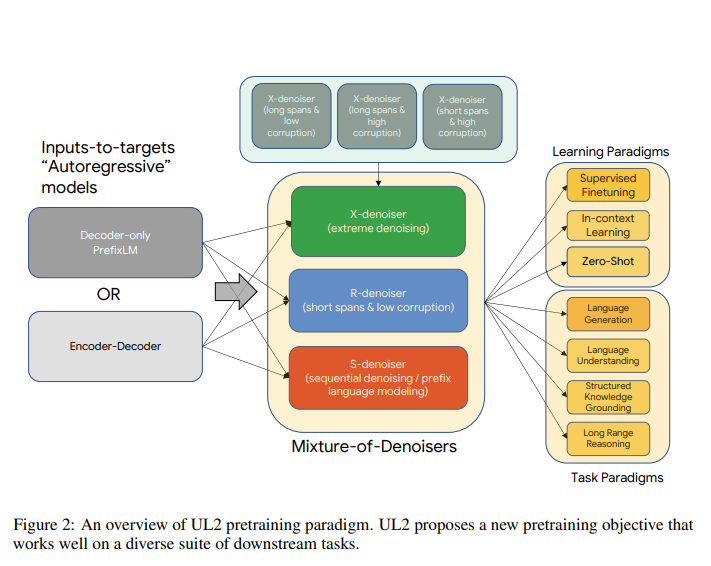
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。 而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。
Python作为目前最流行的编程语言,因为其易用性以及丰富的库成为很多人的工具。它不仅是程序员的编程语言,也是各行各业提升工作效率的工具。本篇博客作为一篇针对完全小白的python语言搭建环境,不会为python语言本身做介绍,完全只考虑搭建python编程环境,目的是让你动手在电脑上写下第一行python程序,并成功运行,为广大童鞋提供一个入门参考。

关注深度学习或者NLP的童鞋应该都知道openAI的GPT-3模型,这是一个非常厉害的模型,在很多任务上都取得了极其出色的成绩。然而,OpenAI的有限开放政策让这个模型的应用被限定在很窄的范围内。甚至由于大陆不在OpenAI的API开放国家,大家几乎都无法使用和体验。而五一假期期间,FaceBook的研究人员Susan Zhang等人发布了一个开源的大预言模型,其参数规模1750亿,与GPT-3几乎一样。

Google旗下自动驾驶公司Waymo的研究人员Mingxing Tan发现了一个可以替代Cross-Entropy Loss的新的损失函数:PolyLoss,这是发表在ICLR 22的一篇新论文。什么都不变的情况下,只需要将损失函数的代码替换成PolyLoss,那么模型在图像分类、图像检测等任务的性能就会有很好的提升!
很多算法的开源实现都包含多个文件,因此,学习这些开源代码的时候通常难以找到入口,也无法快速理解作者的逻辑,对于学习的童鞋来说都带来了不小的挑战。这里推荐一个非常优秀的强化学习开源库,它将经典的强化学习算法都实现在一个文件中,想要学习源代码的童鞋只需要看单个文件即可,这就是ClearRL!
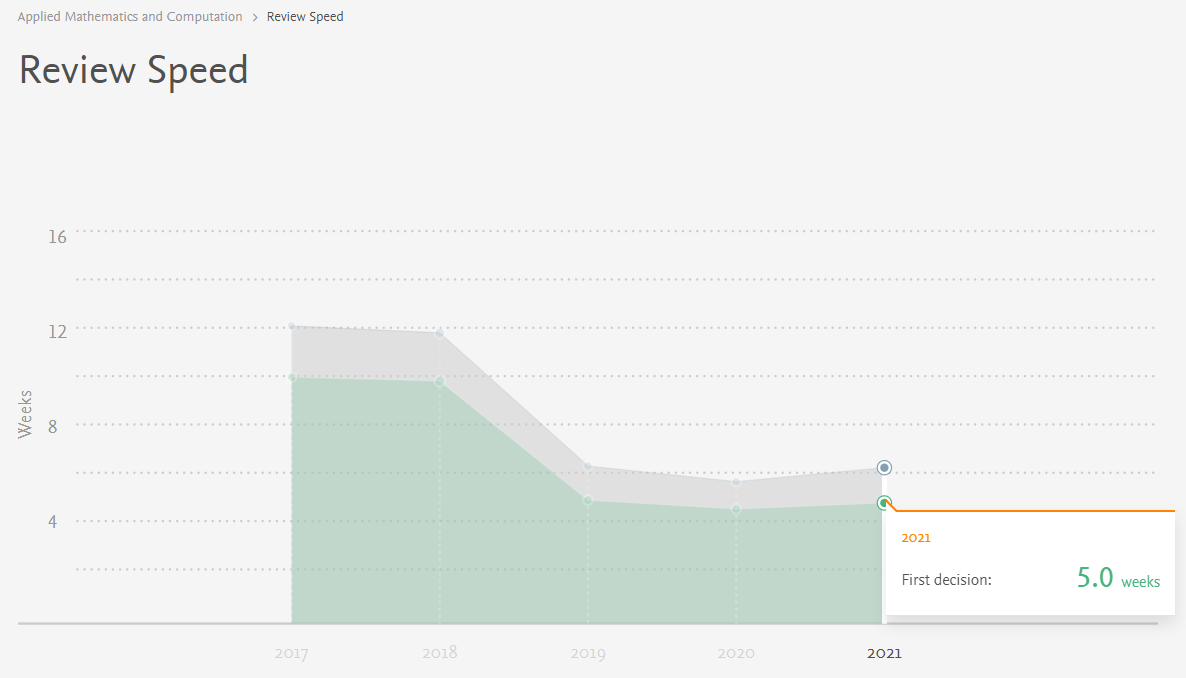
科研成果发表速度对于国内的硕士生和博士生来说非常重要,它涉及了同学们的毕业、出国和奖学金等。很多童鞋在投稿之前都希望了解期刊的审稿周期。虽然大多数期刊没有规定明确的审稿时间,但是,随着大家对学术期刊投稿周期的关注,很多学术期刊也开始就自己的审稿速度开始有所要求,本文针对常见的期刊审稿周期提供一个普遍的分析方法。

开源软件在现代互联网技术的发展中扮演者重要的作用。很多技术的进步和发展都是由开源软件推动的。而开源软件的发展离不开背后强大的开源组织的管理。本文列举最著名的五个开源组织,简述其背景,欢迎大家阅读。

使用AI技术预测未来、对数据进行分类可以解决很多个人或者小企业的问题。然而,对于新手和非行业的小企业来说,学习或者雇佣一个专业人才解决这些问题似乎有些得不偿失。这里给大家推荐一个给新手的可视化的机器学习模型训练网站,可以让大家都能享受到AI技术带来的红利。

Bloomberg在2022年4月开源了Memray,这是一个Python的内存分析器。它可以跟踪Python代码、本地扩展模块和Python解释器本身的内存分配情况。可以看numpy和pandas的运行内存使用。
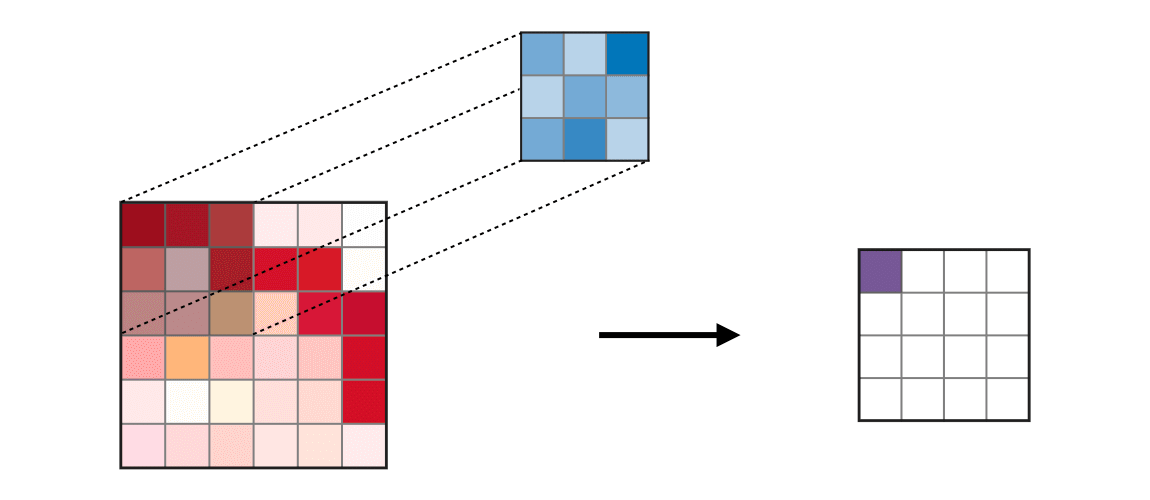
CS 230 ― Deep Learning是斯坦福大学视觉实验室(Stanford Vision Lab)的Shervine Amidi老师开设的深度学习课程,他在课程网站上挂了一个关于深度学习示意图的网站,这里面包含了各种深度学习相关概念的示意图和动图,十分简单明了。

很多童鞋在查询期刊的时候会发现某些期刊不是SCI(SCIE)索引,而是一个叫ESCI的索引。这似乎有点像SCI,但好像又有区别,所以大家会有疑问,本篇博客将解释二者的区别。
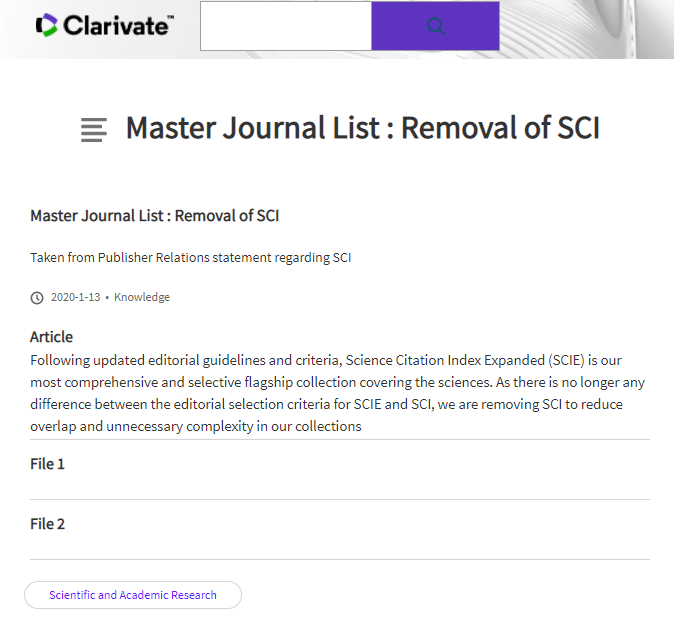
2020年1月13日,Clarivate官网发布声明称SCI索引将被去除。未来全部使用SCIE代替期刊索引。
平时很多时候需要用到SQL,一些常见常用的SQL语句总结,后面可以拷贝使用
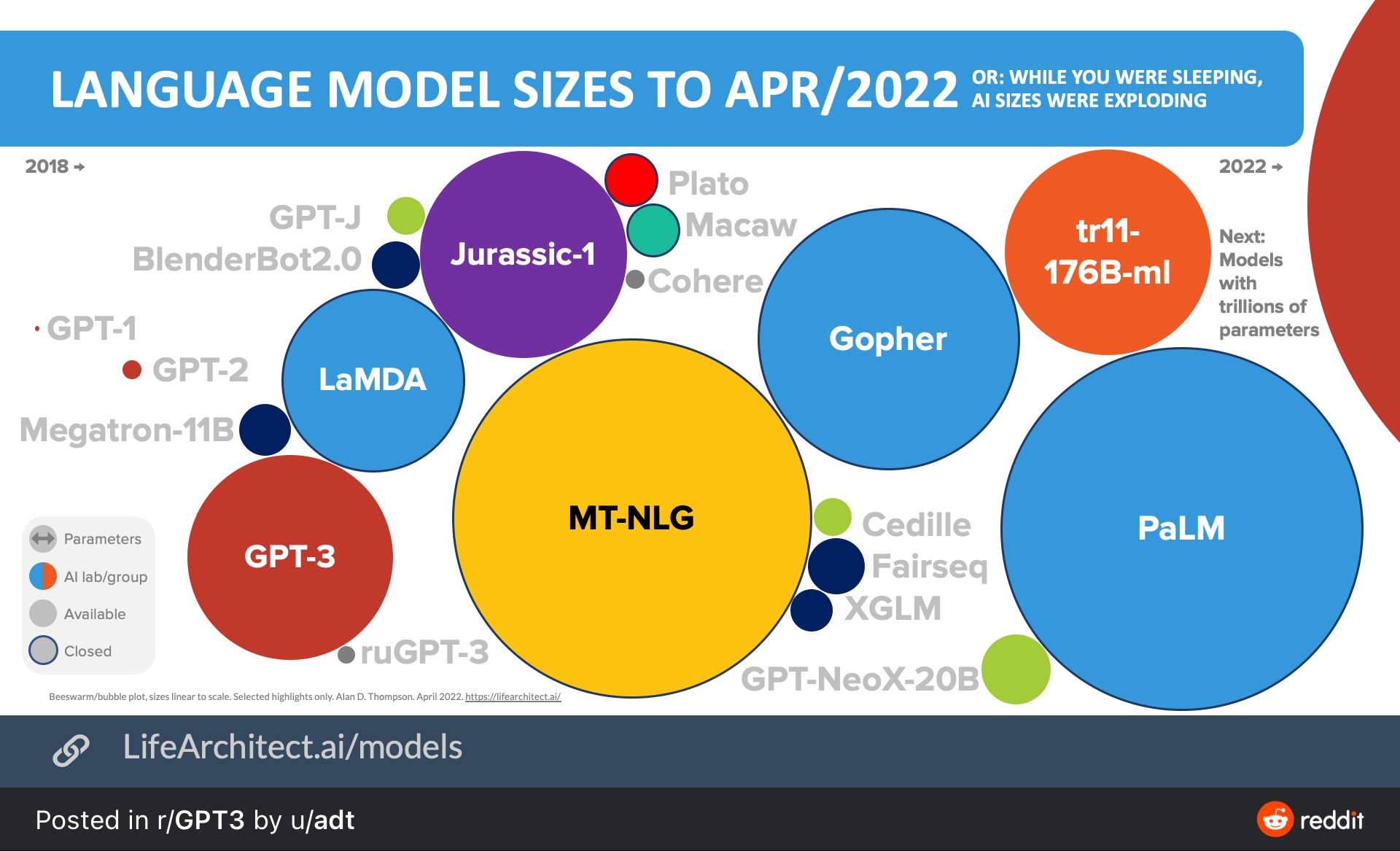
Alan D Thompson博士总结的,截至2022年4月份全球大语言模型一览图。
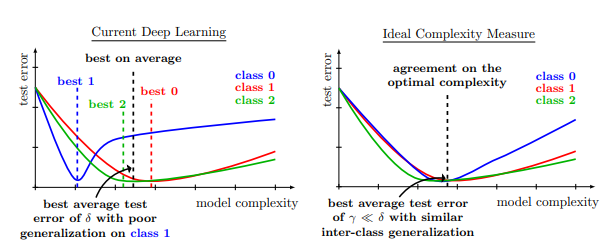
正则化是一种基本技术,通过限制模型的复杂性来防止过度拟合并提高泛化性能。目前的深度网络严重依赖正则化器,如数据增强(DA)或权重衰减,并采用结构风险最小化,即交叉验证,以选择最佳的正则化超参数。然而,正则化和数据增强对模型的影响也不一定总是好的。来自Meta AI研究人员最新的论文发现,正则化是否有效与类别高度相关。

《Python Notes For Professionals》是StackOverflow上的人总结的Python使用方法。
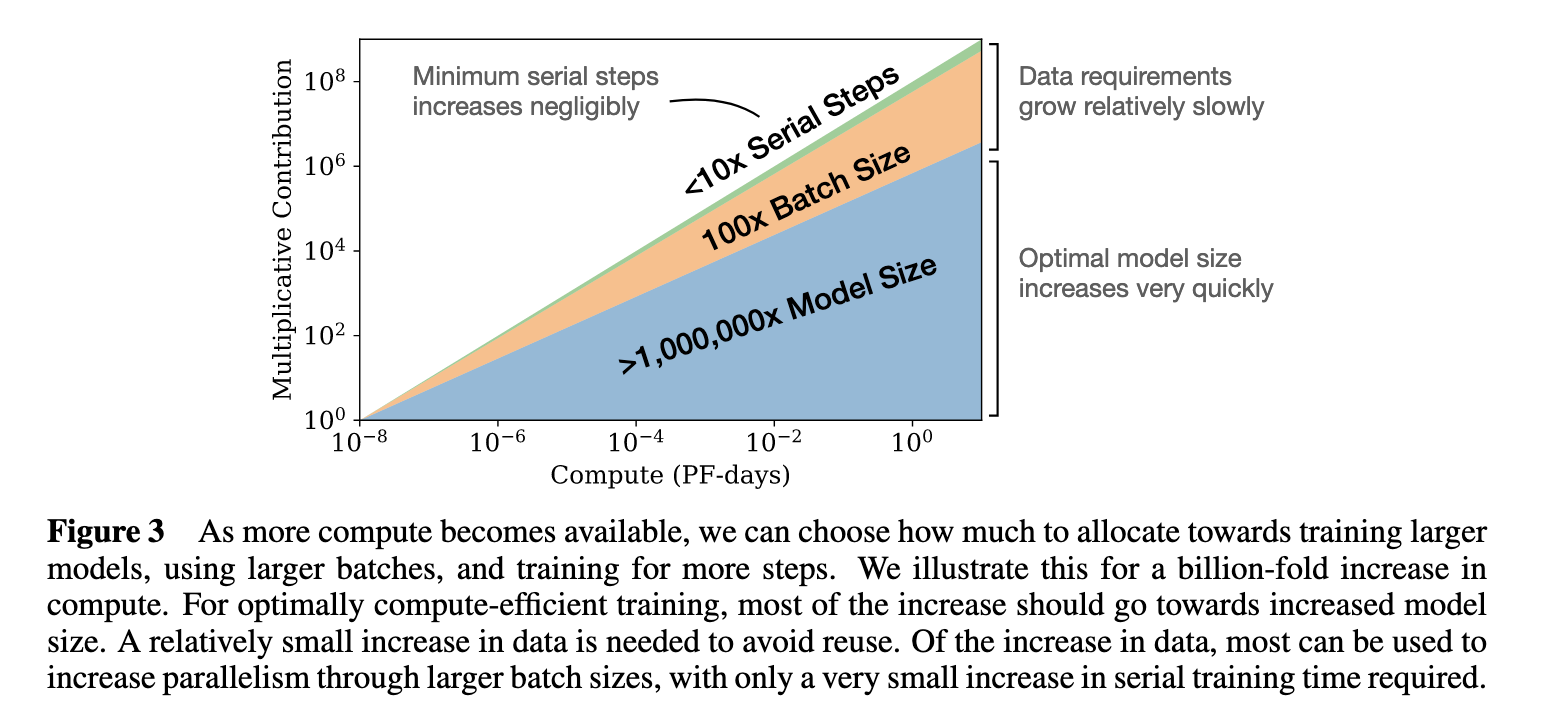
今晚已经是本周的最后一天了,最近的一些深度学习算法方面的进展做个总结吧,感觉都是挺不错的,供大家参考。
Jupyter Notebook虽然在教学等领域有着非常大的优势,但是实际编程中,它的效率、可维护性等方面与python脚本相比的差距到底在哪也一直不那么清晰。就在上个月底,JetBrains的研究人员使用了大量的数据详细对比了二者的差异。这里总结一下其主要结论。