
Java读取和操作上G文本数据
在处理文本时,经常遇到超过1g存储的数据,直接简单的读取,可能遇到java空间不足的问题,为解决此问题,可将大文本数据按照行进行切分为很多块,并将每一块存储为一个文本
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
在处理文本时,经常遇到超过1g存储的数据,直接简单的读取,可能遇到java空间不足的问题,为解决此问题,可将大文本数据按照行进行切分为很多块,并将每一块存储为一个文本

AI Playground最近的LLaMA2、Stable Diffusion XL等模型的进展也让大家看到了最新最强大的模型的能力。但是,对于大多数人来说,这些模型的使用依然具有较高的门槛,除了硬件资源消耗大,本身的部署也不容易。而支撑这些模型的一个重要的硬件因素就是英伟达的显卡。显卡已经超越一般理财,变得越来越贵。因此,基于大模型的免费服务成本也很高,而今天,英伟达官方的NGC网站推出了新的几款可以免费使用的大模型,包括聊天大模型LLaMA2、文本生成图片大模型Stable Diffusion等,基于
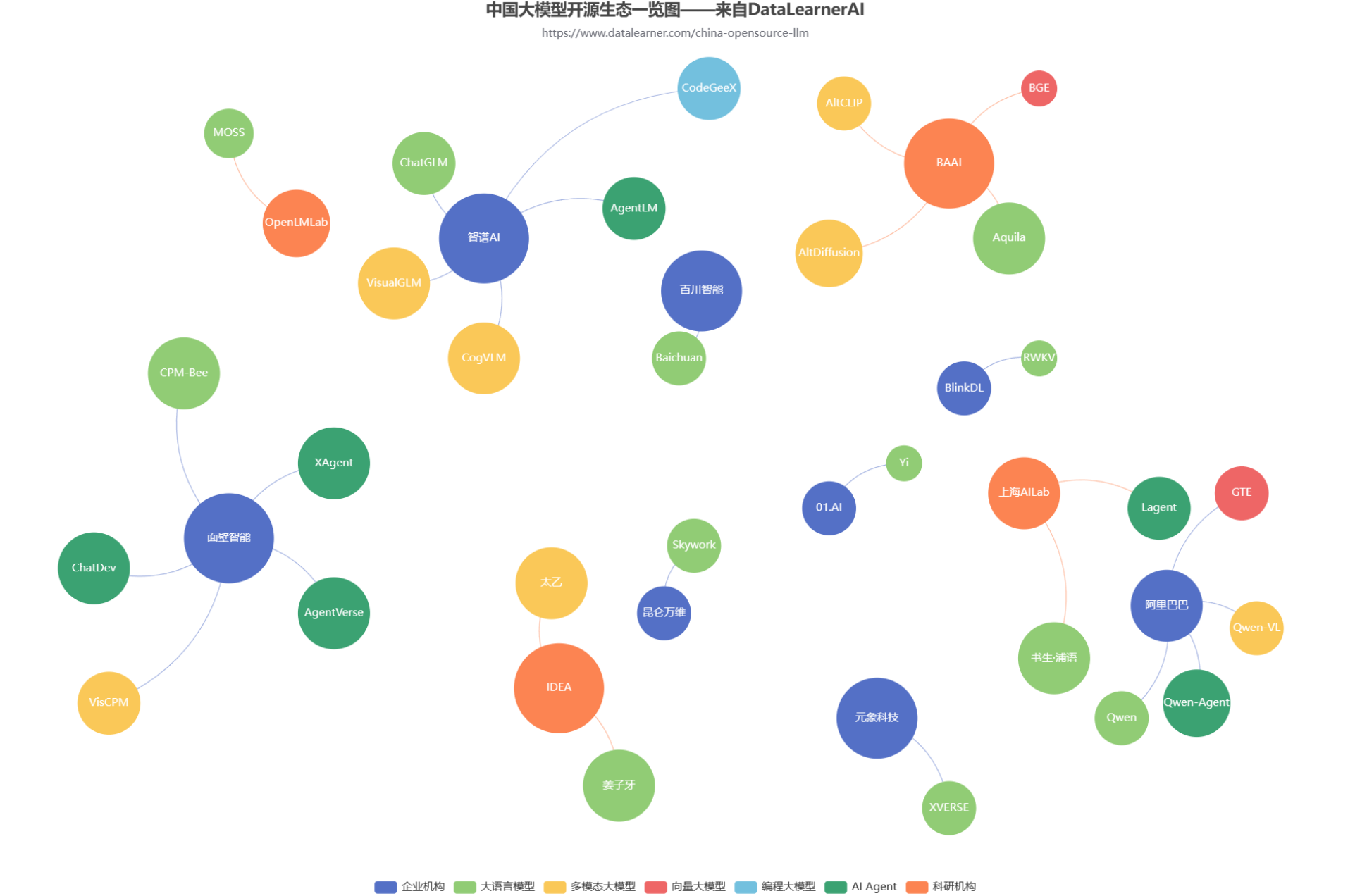
随着GPT的一路爆火,国内大模型的开源生态也开始火热。各大商业机构和科研组织都在不断发布自己的大模型产品和成果。但是,众多的大模型产品眼花缭乱。为了方便大家追踪国产开源大模型的发展情况,DataLearnerAI发布了中国国产大模型生态系统全景统计(地址:https://www.datalearner.com/china-opensource-llm ),本文也将根据这个统计结果简单分析当前国产开源大模型的生态发展情况。
百川智能是前搜狗创始人王小川创立的一个大模型创业公司,主要的目标是提供大模型底座来提供各种服务。虽然成立很晚(在2023年4月份成立),但是三个月后便发布开源了Baichuan系列开源模型,并上架了Baichun-53B的大模型聊天服务。这些模型受到了广泛的关注和很高的平均。而2个月后,百川智能再次开源第二代baichuan系列大模型,其能力提升明显。
基于算法的业务或者说AI的应用在这几年发展的很快。但是,在实际应用的场景中,我们经常会遇到一些非常奇怪的偏差现象。例如,Facebook将黑人标记为灵长类动物、城市图像识别系统将公交车上的董明珠形象广告识别为闯红灯的人等。算法系统出现偏差的原因有很多。本篇博客将总结在数据获取相关方面可能导致模型出现偏差的原因。
Linux权限管理之基本权限
梯度下降、牛顿法、拟牛顿法详细介绍

最近,随着DeepSeek R1的火爆,推理大模型也进入大众的视野。但是,相比较此前的GPT-4o,推理大模型的区别是什么?它适合什么样的任务?推理大模型是如何训练出来的?很多人并不了解。本文将详细解释推理大模型的核心内容。
端到端(end-to-end)学习
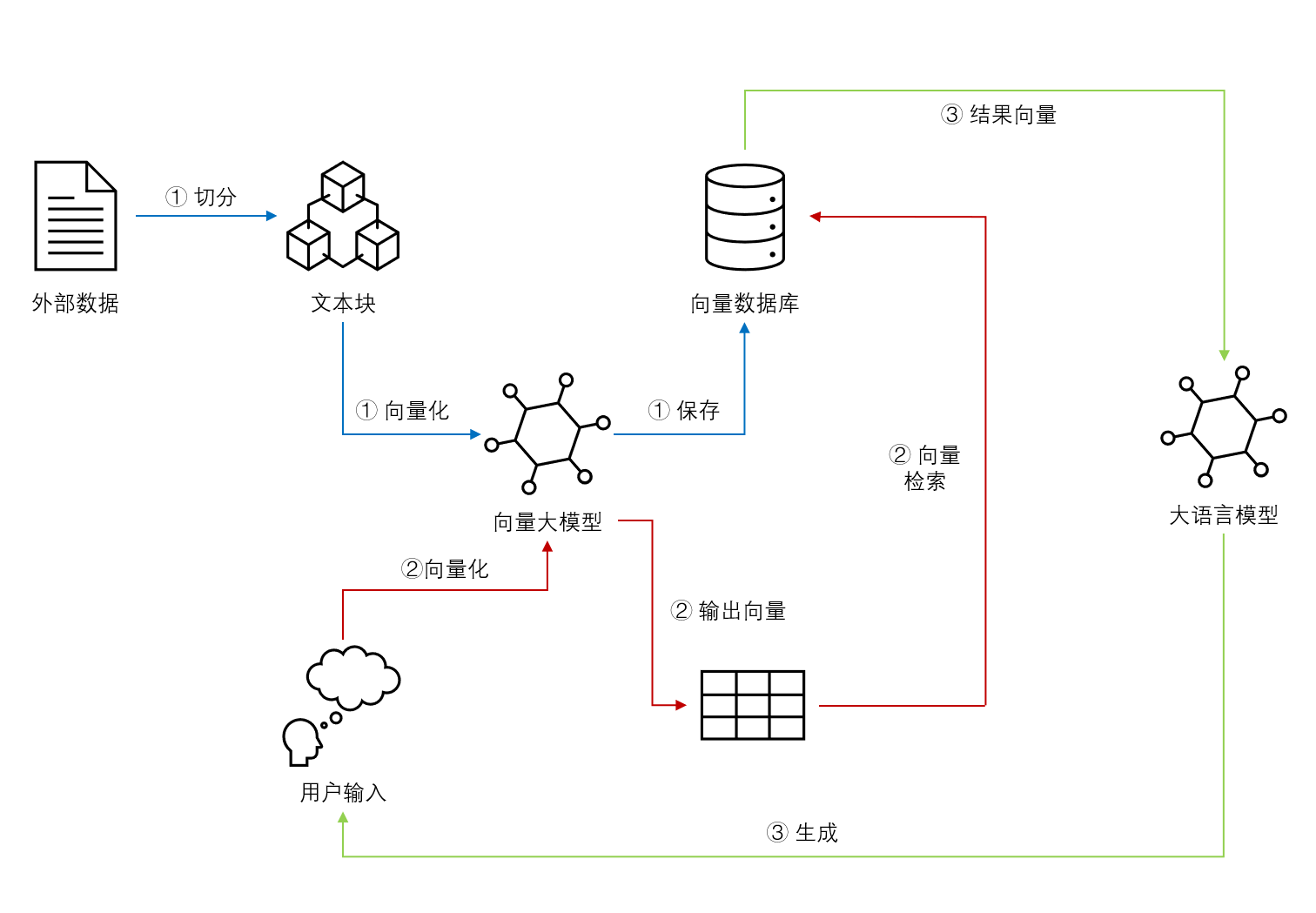
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。
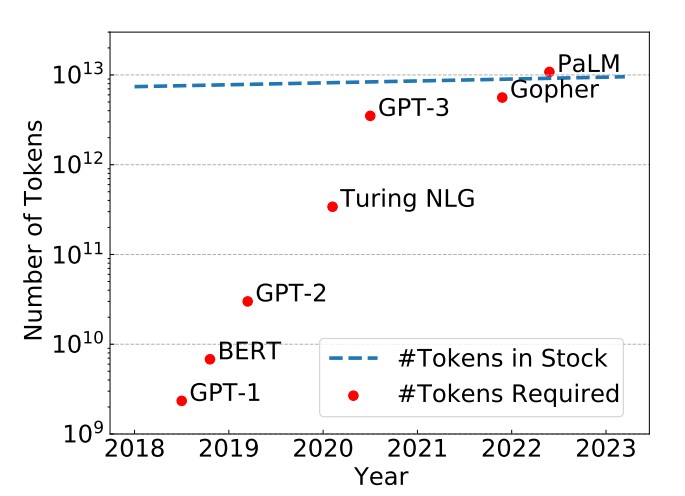
epoch是一个重要的深度学习概念,它指的是模型训练过程中完成的一次全体训练样本的全部训练迭代。然而,在LLM时代,很多模型的epoch只有1次或者几次。这似乎与我们之前理解的模型训练充分有不一致。那么,为什么这些大语言模型的epoch次数都很少。如果我们自己训练大语言模型,那么epoch次数设置为1是否足够,我们是否需要更多的训练?

这是来自AnalyticsVidhya的Pranav Dar的帖子
从问题定义,到数据获取以及模型选择调参,这篇博客指出了每个过程中需要注意的问题

自从Hadoop生态发展以来,基于开源软件提供服务的盈利公司也越来越多。大家这才发现,开源不仅不会削弱企业竞争力,还可以带来生态,增强企业的竞争力。本文总结全球最挣钱的十大开源公司供大家参考。
SVN是Subversion的简称,是一个开放源代码的版本控制系统,相较于RCS、CVS,它采用了分支管理系统,它的设计目标就是取代CVS。互联网上很多版本控制服务已从CVS迁移到Subversion。说得简单一点SVN就是用于多个人共同开发同一个项目,共用资源的目的。

我出生在一个不大不小的南方城市,那里纵横着大大小小的巷子,而通往我记忆深处的是寺巷子。
MySQL支持对文本进行全文检索,全文检索可以类似搜索引擎的功能,相比较模糊匹配更加灵活高效且更快。MySQL5.7之后也支持对中文的全文检索,这里描述如何启用MySQL的中文全文检索。
221
这篇博客主要翻译自Gregor Heinrich的技术博客Parameter estimation for text analysis,介绍极大似然估计、极大后验估计和贝叶斯参数估计的原理和案例
看过很多书,都说了神经网络的进展,但总有一些小问题没有明白。这次基本上都明白了,记录一下。
Java多线程网络爬虫(时光网为例)
