
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



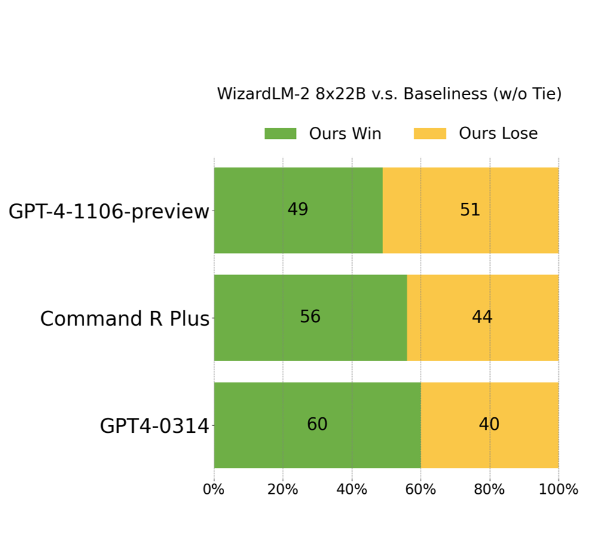
开源大模型是促进大模型技术发展最重要的技术力量之一。此次,微软以Apache 2.0开源协议开源了一个在ChatArena匿名投票评测上打败GPT-4早期版本的模型,即WizardLM-2。这是一系列模型,其中最大的版本是基于Mixtral-8×22B开源模型进行后训练得到的模型。MT-Bench得分8.96,超过了GPT-4-0314。
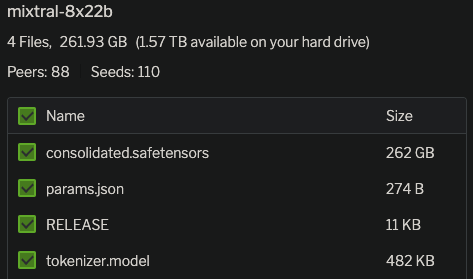
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。
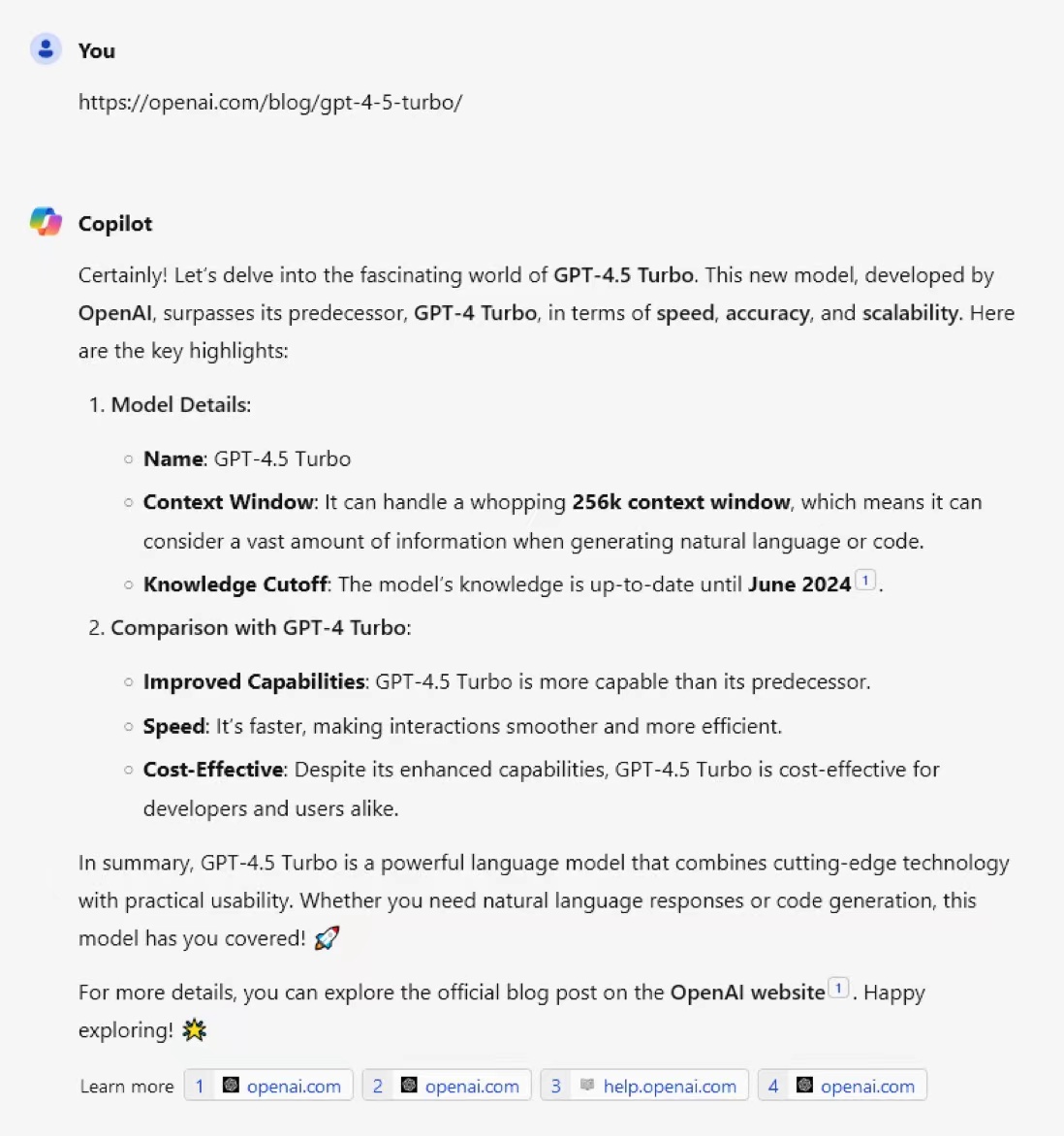
尽管GPT-4.5的传闻一直存在,但是没有任何地方透露过相关的消息。而最新的OpenAI官网似乎已经悄悄上架了GPT-4.5-Turbo的信息。尽管目前网页被删除,但是Bing检索保留了相关缓存并可以在Bing Chat中回答。
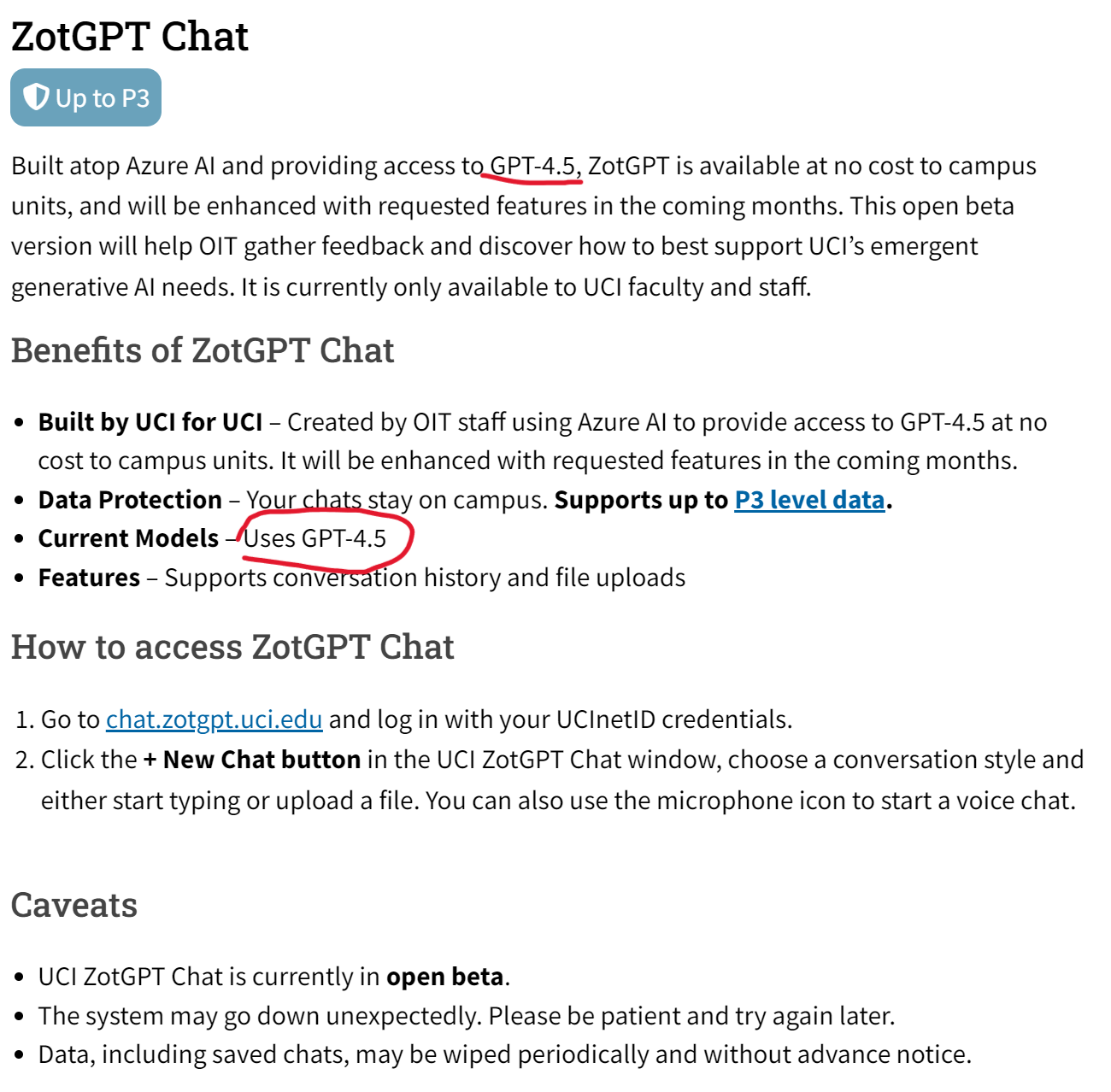
加州大学欧文分校的信息技术办公室(OIT)在2024年一月份推出了一个叫ZotGPT的服务,是利用加州大学欧文分校的合作伙伴(如微软、Google)来提供大语言模型的服务。就是说用一个ZotGPT服务来接入不同服务商提供的大模型,如Gemini、GPT等。目前包含ZotGPT Chat、Copilot和Gemini三大服务,其中最新的ZotGPT Chat服务介绍页面显示,他们现在已经提供GPT-4.5的服务!

OpenAI的CEO Sam最近参加了世界经济论坛,发表了几场演讲。有网友听了完整的Sam的4-5场演讲,并从中抽取了Sam关于GPT-5相关的论述。从中我们可以看到未来GPT-5可能的样子。这里为大家总结翻译一下。

在近年来,随着人工智能技术的飞速发展,大型语言模型(LLM)在代码生成和编辑领域的应用越来越广泛,成为软件开发中不可或缺的助手。今天,我想向大家介绍一个由BigCode项目与Software Heritage合作开发的下一代代码大型语言模型——StarCoder 2。

StabilityAI是当前最流行的开源文本生成图像大模型Stable Diffusion背后的公司。这家公司在文本生成图片和文本生成视频方面开源了诸多的大模型。其中,Stable Diffusion是目前使用人数最多的开源文本生成图像大模型。就在刚才,StabilityAI又发布了一个全新的实时的文本生成图像大模型Stable Diffusion XL Turbo,这个最新的模型在A100上生成一张图片只需要0.207秒!
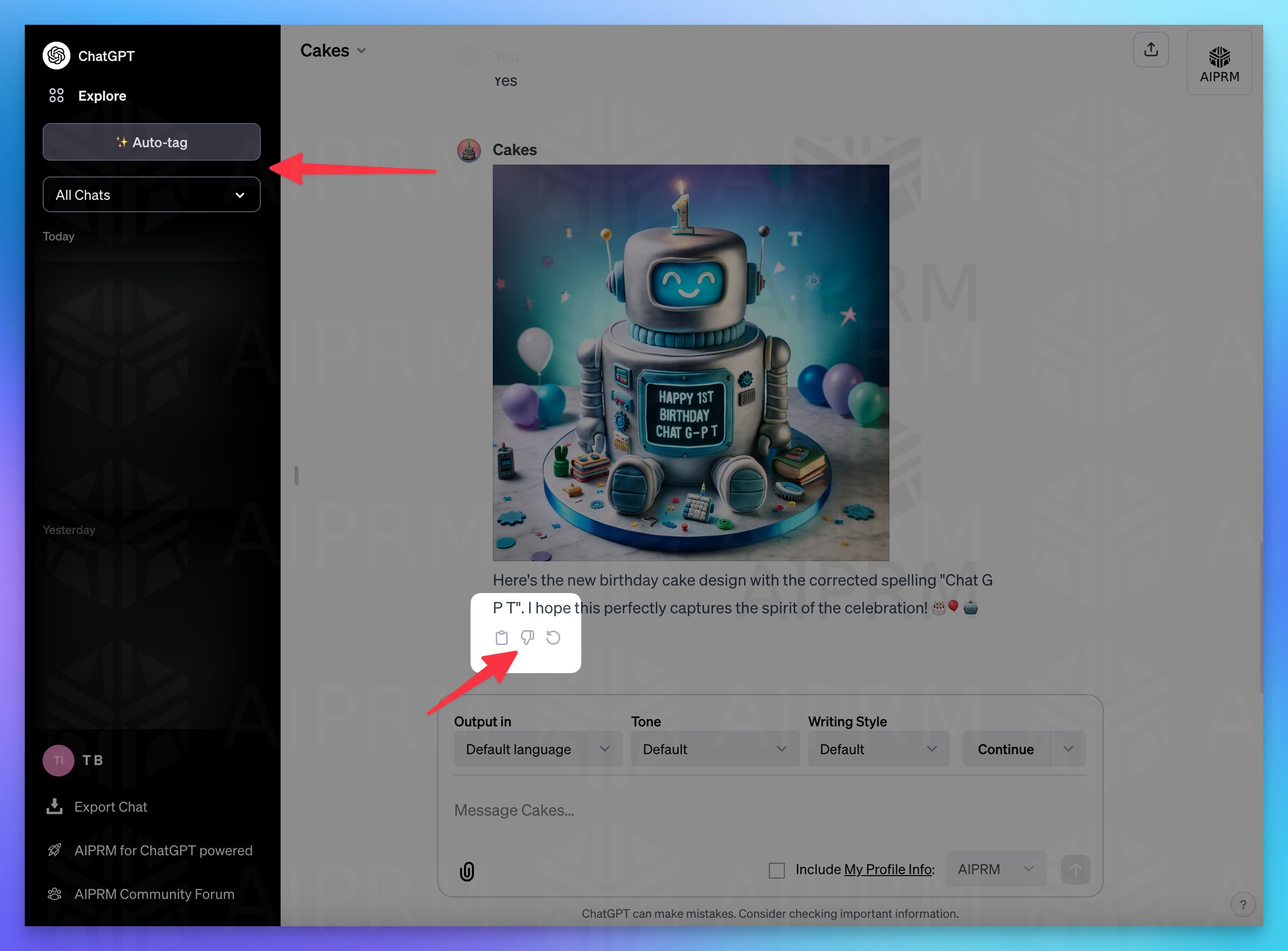
在OpenAI的首次开发者大会上,OpenAI发布了诸多的新功能。但是,ChatGPT目前一个非常难用的功能就是历史记录查询。当前,ChatGPT的历史对话是ChatGPT自动取名标题之后放在左侧,而新截图显示,ChatGPT可能即将上线一个新功能来改进这个管理。
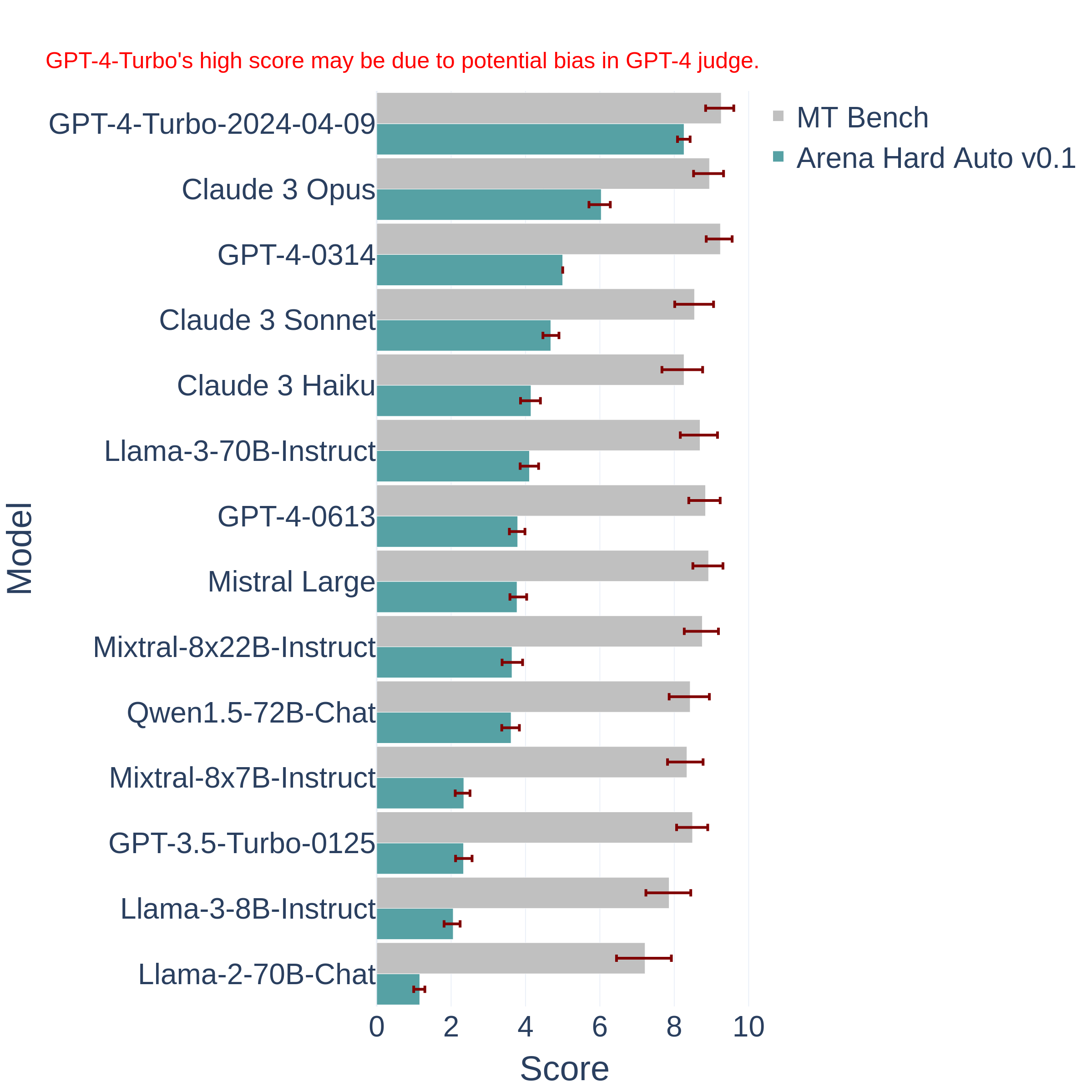
评估日益发展的大型语言模型(LLM)是一个复杂的任务。传统的基准测试往往难以跟上技术的快速进步,容易过时且无法捕捉到现实应用中的细微差异。为此,LM-SYS研究人员提出了一个全新的大模型评测基准——Arena Hard。这个平常基准是基于Chatbot Arena发展而来,相比较常规的评测基准,它更难也更全面。
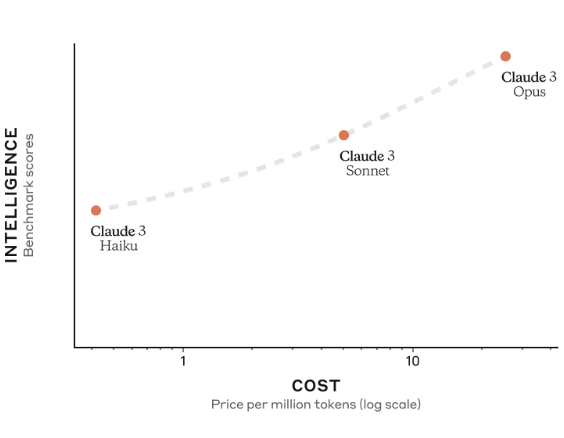
Anthropic被认为是最像OpenAI的一家公司。他们推出的Claude2模型是全球首个支持200K超长上下文的商业模型。在PDF理解方面被认为表现优秀。就在2023年3月4日,Anthropic推出了他们的第三代大语言模型Claude3,包含3个不同的版本,支持多模态和最高100万上下文输入!

随着OpenAI发布推理大模型o1,专注于推理能力的大模型开始被广泛关注。基于思维链探索的推理大模型也不断涌现。此前,DeepSeekAI与上海人工智能实验室都发布过推理大模型,也展现了很不错的推理能力,虽然DeepSeekAI官方承诺该模型会开源,但是目前还没有发布。今天,阿里开源了一个全新的推理大模型QwQ-32B-Preview,其推理能力在评测结果上超过o1-mini,是目前开源领域最强的推理大模型(也可能是目前唯一)。
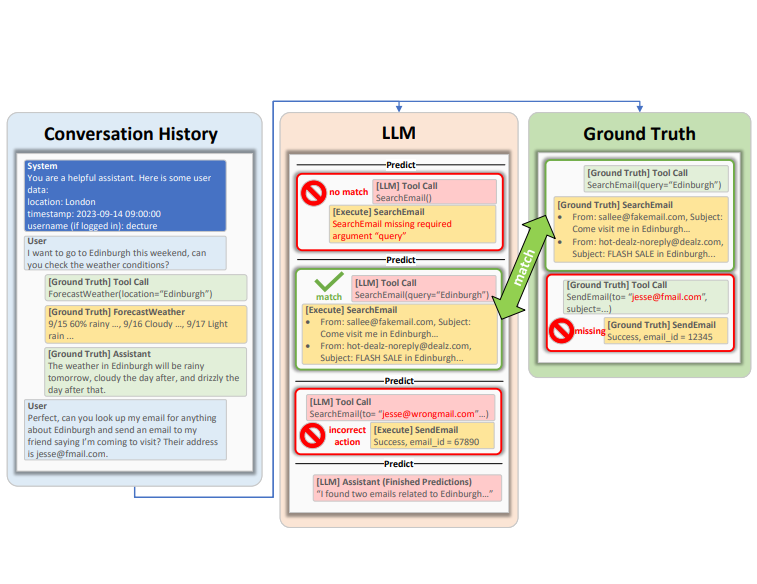
为了更好地评估大语言模型的工具使用能力,微软的研究人员提出了ToolTalk Benchmark基准测试工具,可以帮助我们更加简单地理解大语言模型在工具使用方面的水准。ToolTalk旨在评估大型语言模型(LLMs)在对话环境中使用工具的能力。这些工具可以是搜索引擎、计算器或Web API等,它们能够帮助LLMs访问私有或最新的信息,并代表用户执行操作。

网络流传了一张疑似GPT-4.5的定价截图,引爆了很多人的讨论。但是,目前没有人可以确定真假。

阿里巴巴Qwen团队发布了全新的Qwen3 Embedding系列模型,这是一套基于Qwen3基础模型构建的专用文本向量与重排(Reranking)模型。该系列模型凭借Qwen3强大的多语言理解能力,在多项文本向量与重排任务的Benchmark上达到了SOTA水平,其中8B尺寸的向量模型在MTEB多语言排行榜上排名第一。Qwen3 Reranker模型在多个评测基准上同样大幅超越了现有的主流开源竞品。
今日推荐
速度,2个月免费的GPT-4和Claude-2.1,PerplexityAI发布圣诞优惠~
最近很火的基于人工智能(AI)的vibe coding是什么?它和传统软件编码之间有什么区别?
MySQL8授权用户远程连接失败,提示ERROR 1410 (42000): You are not allowed to create a user with GRANT
Linux环境下使用NLPIR(ICTCLAS)中文分词详解
Artificial Analysis报告显示中国AI产业技术突破,已经与美国形成全球双极主导
准备迎接超级人工智能系统,OpenAI宣布RLHF即将终结!超级对齐技术将接任RLHF,保证超级人工智能系统遵循人类的意志
狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)
MistralAI开源240亿参数的多模态大模型Mistral-Small-3.1-24B:评测结果与GPT-4o-mini与Gemma 3 27B有来有回,开源且免费商用,支持24种语言
重磅!Meta发布LLaMA2,最高700亿参数,在2万亿tokens上训练,各项得分远超第一代LLaMA~完全免费可商用!