
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




阿里宣布开源第三代编程大模型Qwen3-Coder-480B-A35B,该模型是Qwen3编程大模型中第一个开源的版本,同时官方还基于Google的Gemini CLI改造并开源了阿里自己的命令行编程工具Qwen Code,完全免费使用。

昨天,Anthropic公布了一项引人注目的实验——Project Vend。他们让旗下的大模型Claude Sonnet 3.7在一个真实的办公环境中,自主经营一家小型自动化商店,为期约一个月。这个实验的目标是探索,在不久的将来,AI模型在真实经济体中自主运行任务的可行性、潜在的成功模式以及那些出人意料的失败方式。实验结果非常强大,也充满了令人深思的细节!
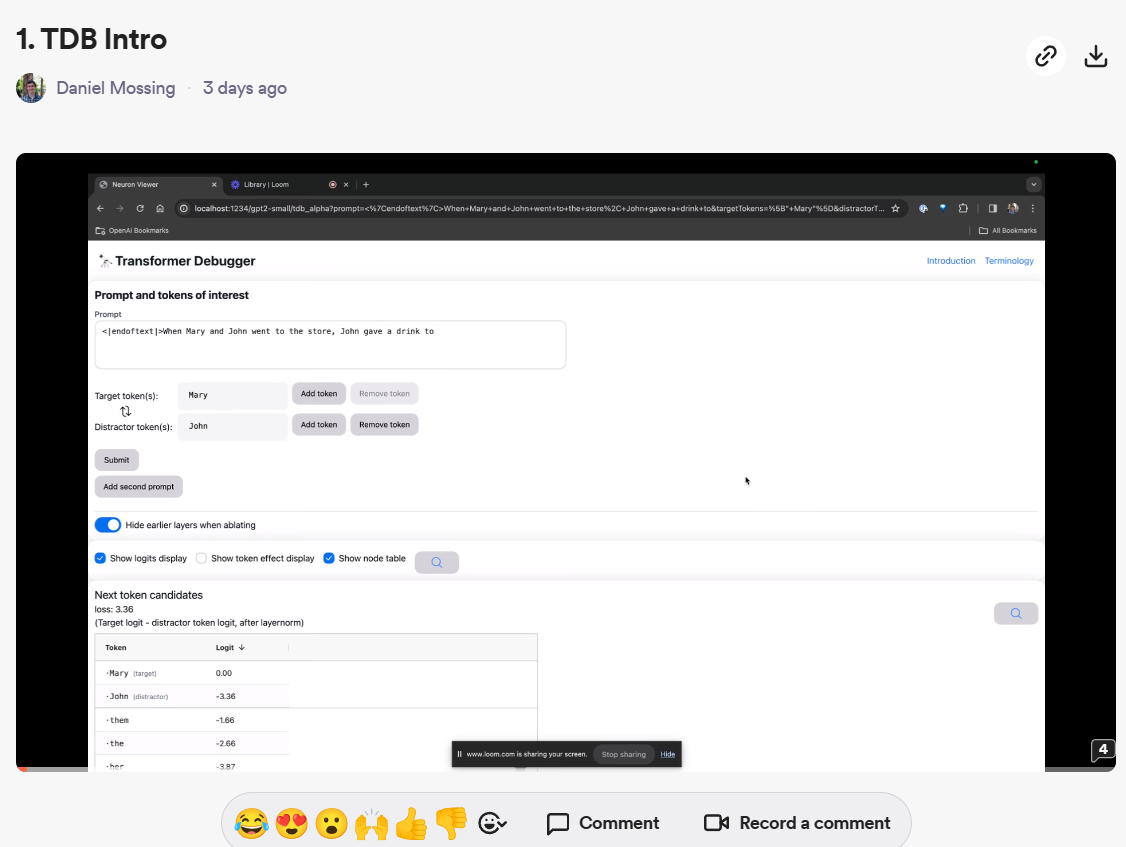
自从OpenAI转向盈利化运营之后,很少再开源自己的技术。但就在刚才,OpenAI开源了一个全新的大模型调测工具:Transformer Debugger。这个工具可以帮助开发者调测大模型的推理情况,帮助我们理解模型的输出并提供一定的解释支持。

继Gemma系列模型发布并迅速形成超过1.6亿次下载的繁荣生态后,Google再次推出了其在端侧AI领域的重磅力作——Gemma 3n。这款模型并非一次简单的迭代,而是基于全新的移动优先(mobile-first)架构,旨在为开发者提供前所未有的设备端多模态处理能力。Gemma 3n的定位是成为一款高效、强大且灵活的开源模型,直接与设备端AI领域的其他先进模型(如Phi-4、Llama系列的小参数版本)竞争,其核心特性在于原生支持图像、音频、视频和文本输入。

微软发布了全新的Phi-4推理模型系列,是小型语言模型(SLM)在复杂推理能力上的一种新的尝试。本次发布包含三个不同规模和性能的推理模型,分别是Phi-4-reasoning(140亿参数)、Phi-4-reasoning-plus(增强版140亿参数)和Phi-4-Mini-Reasoning(38亿参数)。这三款模型尽管参数规模远小于当前主流大型语言模型,却在多项推理基准测试中展现出与甚至超越大型模型的能力。

上周,MoonshotAI 发布了 Kimi K2,并宣布 完全开源、允许商用。发布 24 小时内,社区即完成了 MLX 移植、4-bit 量化等后续工作。外网很多人评价说,Kimi K2是另一个DeepSeek R1时刻。本文尝试以第三方视角,把Kimi开发者公开的技术讨论、社区疑问与公开配置里的数字串成一条完整的技术决策链,解释Kimi K2背后的技术决策以及他们眼中大模型创业企业的方向。
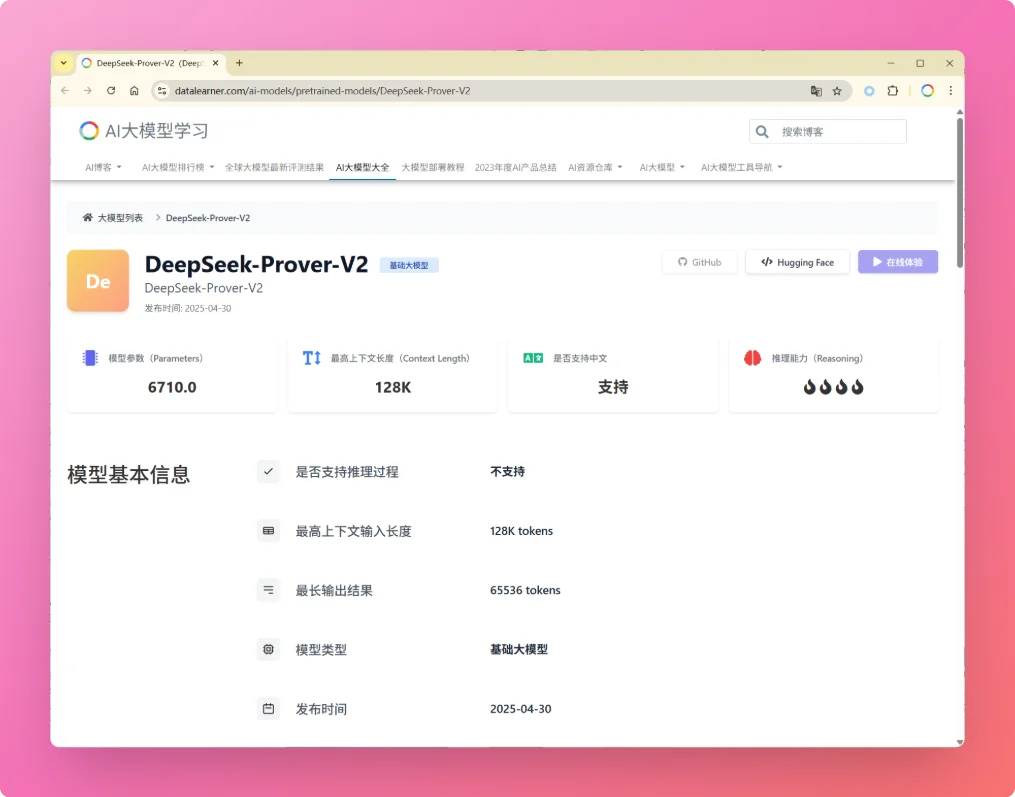
就在刚才,DeepSeek-AI发布了其新一代自动定理证明模型 **DeepSeek-Prover-V2**。尽管官方暂未公开详细报告,但从其前代模型 **DeepSeek-Prover-V1.5** 的技术细节,以及去年底发布的通用推理模型 DeepSeek-R1 的进展来看,V2 很可能在多个关键能力上取得了实质性提升。
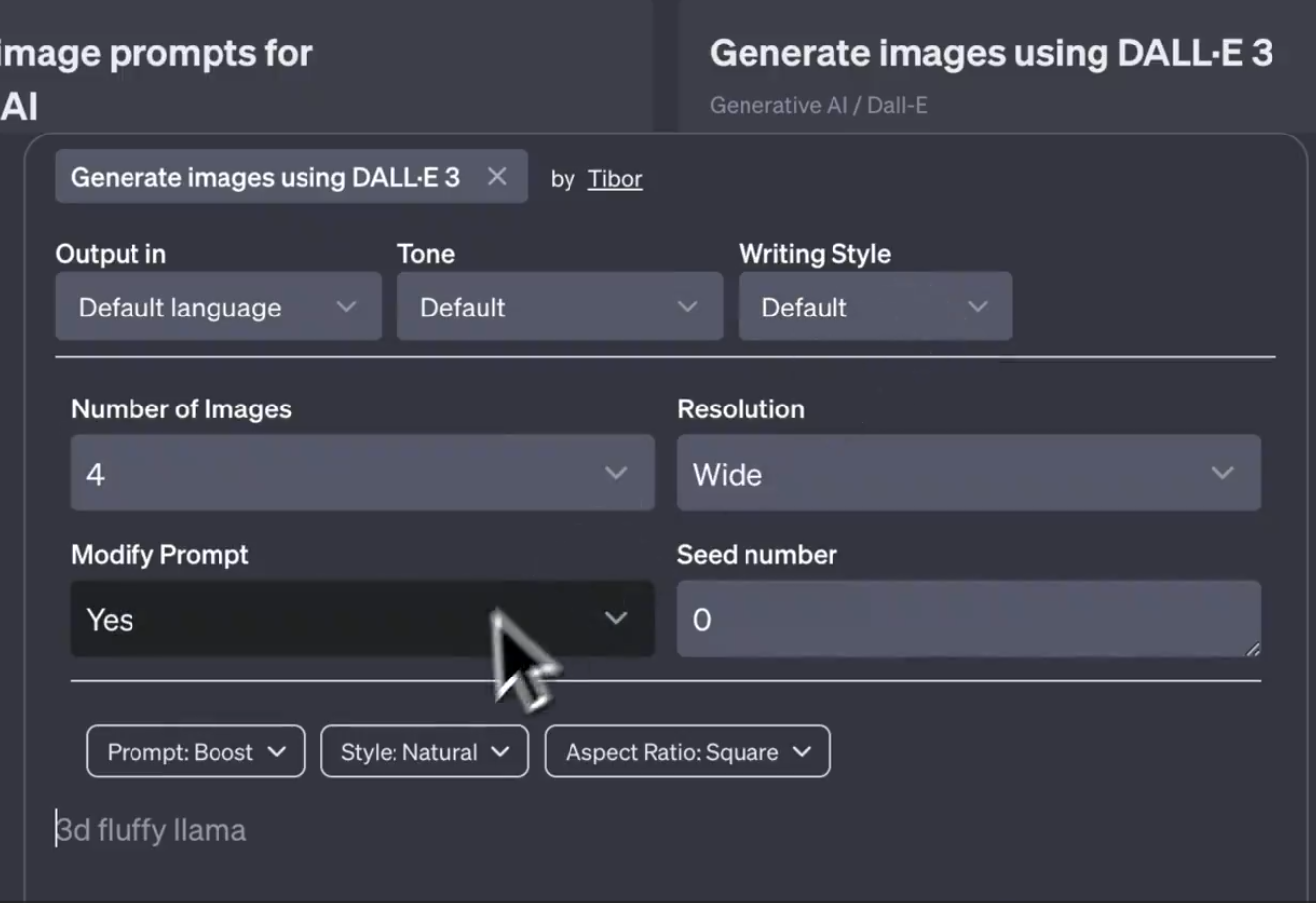
DALL·E3是OpenAI推出的文本生成图片服务,背后也是一个文生图大模型。此前,该模型只能通过对话的方式让模型生成图片结果。无法通过配置信息控制模型输出的效果,包括风格、比例等。而最新的截图显示,OpenAI可能即将推出DALL·E Controls功能,可以从不同的方面来控制图片生成的效果。

今天,Google发布Gemini 2.5 Flash Lite。这是一款专为追求极致速度、超低延迟和高性价比场景打造的轻量级模型。它的发布标志着 Google 正在将旗舰模型的先进能力(如百万级上下文、原生多模态、工具调用等)逐步下放到更轻量、更经济的模型层级。根据 DataLearnerAI 的实测,这款模型的生成速度最高可达 400 tokens/秒,即使在输入达到 18K tokens 的情况下,也依然可以维持在 160+ tokens/秒 的性能表现,令人惊喜。

7月28日,智谱AI(Zhipu AI)向开源社区投下了一枚重磅炸弹,正式发布了其最新的旗舰模型系列:GLM-4.5。该系列包含两个新成员——GLM-4.5和GLM-4.5-Air,两者均以开源权重形式提供。官方技术报告详细阐述了其设计理念、技术细节以及在多项基准测试中的表现。本次发布的核心目标是打造一个能够统一推理、代码和Agent智能体能力的模型,以应对日益复杂的AI应用需求。本文将深入解析这份官方报告,剖析其核心技术、性能表现,并探讨其在当前大模型竞争格局中的战略定位。

盘古大模型是华为自研的大语言模型,基于华为的硬件和技术栈进行训练。此前一直被认为是国产技术占比很高的国产大模型。今天,华为开源了2个盘古大模型,分别是MoE架构的Pangu Pro MoE模型以及70亿参数规模的Pangu Embedded模型。

今天,百度正式宣布开源其最新的旗舰级大模型系列——ERNIE 4.5。ERNIE 4.5系列模型当前包含2个多模态大模型,4个大语言模型及其不同变体的庞大家族,还区分了PyTorch版本和paddlepaddle版本,共23个模型,其核心采用了创新的异构多模态混合专家(MoE)架构,在提升多模态理解能力的同时,实现了文本处理性能的同步增强。每个版本的模型都开源了基座(Base)版本和后训练版本(不带Base)。
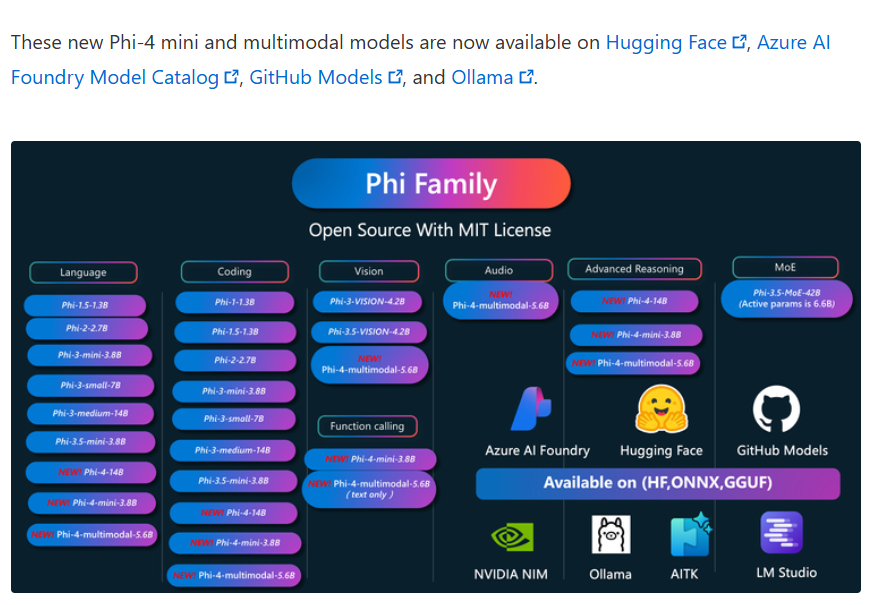
2025年2月27日,微软正式发布了其全新系列的大型语言模型——Phi-4系列。这一系列包含了三个创新性的模型:Phi-4-Mini、Phi-4-Multimodal和一款经过推理优化的Phi-4-Mini。此次发布的模型不仅在性能上展现出色,更在多模态能力与推理任务中实现了显著突破。其中,Phi-4-Multimodal是一个仅仅包含56亿参数规模的多模态大模型,但是支持文本、语音、图片的输入,十分强大。

阿里今天开源了一个Qwen3-235B-A22B模型的小幅更新版本,命名为Qwen3-235B-A22B-Thinking-2507,这是一个只支持带推理过程的模型,而四天前,阿里还开源了Qwen3-235B-A22B-Instruct-2507,一个不支持推理过程的模型。这2个版本模型去除了Qwen3此前的一个模型的混合架构模式(即一个模型同时支持thinking和non-thinking),而是拆分成2个不同的版本。阿里官方说这是从社区获得了反馈之后决策的。
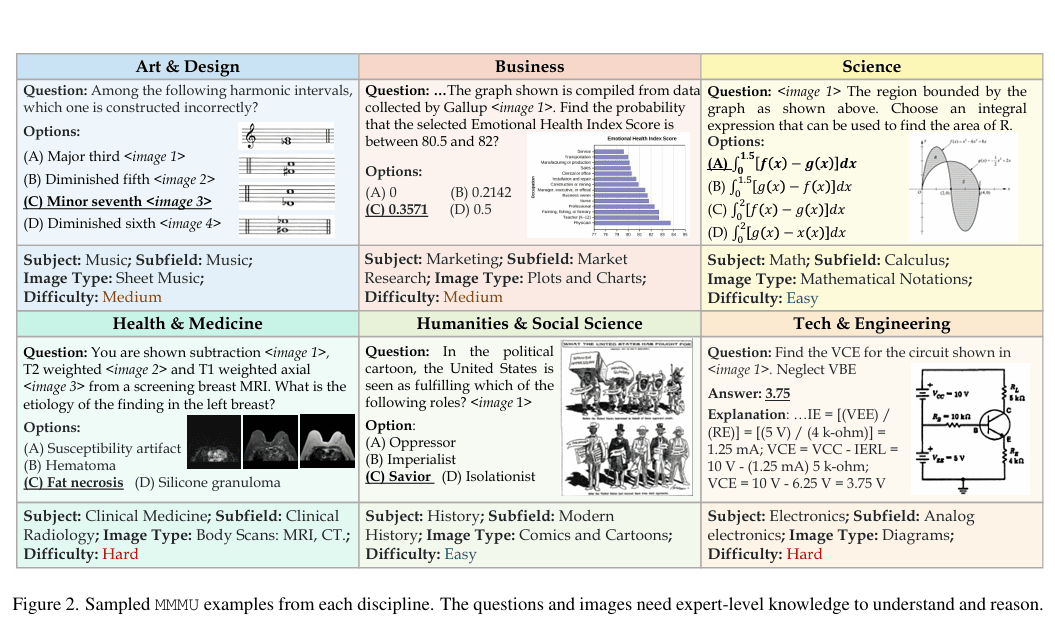
大规模多学科多模态理解与推理基准(MMMU)于2023年11月推出,是一种用于评估多模态模型的复杂工具。该基准测试人工智能系统在需要大学水平学科知识和深思熟虑推理的任务上的能力。与之前的基准不同,MMMU强调跨多个领域的先进感知和推理,旨在衡量朝专家级人工智能通用智能(AGI)的进展。
今日推荐
重磅数据集公布!LAION-400-Million Open Dataset免费的4亿条图像-文本对数据( LAION-400M:English (image, text) pairs)
微软发布大语言模型与传统编程语言的集成编程框架——Python版本的Semantic Kernel今日发布
Dirichlet Process and Stick-Breaking(DP的Stick-breaking 构造)
SWE-bench大模型评测基准介绍:测试大模型在真实软件工程任务中的能力
大模型企业宫斗连续剧:刚刚发生!StabilityAI重要技术人员出走后CEO辞职!HuggingFace CEO说考虑收购StabilityAI
重磅!百度文心一言开源,包含2个多模态大模型,4个大语言模型,最大参数量4240亿!完全免费商用授权!
Author Topic Model[ATM理解及公式推导]
Grok3发布!马斯克旗下大模型企业xAI发布Grok3、Grok3-mini,支持Deep Research、语音交互和“思考”模式的推理大模型,推理模式评测结果全球最强