
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



Kiro 是一款AWS刚发布的、具有代理(agentic)能力的集成开发环境(IDE),它的目的是希望通过简化的开发者体验,帮助开发者从概念原型无缝过渡到生产级别的应用。它的核心理念是“规格驱动开发”(spec-driven development),以解决当前 AI 编程从有趣的原型到可靠的生产系统之间存在的鸿沟。

GLM-4.1V-Thinking是智谱AI(Zhipu AI)与清华大学KEG实验室联合推出的多模态推理大模型。这款模型并非简单的版本迭代,而是通过一个以“推理为中心”的全新训练框架,旨在将多模态模型的能力从基础的视觉感知,推向更复杂的逻辑推理和问题解决层面。多模态理解能力接近720亿的Qwen2.5-VL-72B。

OpenAI 正式发布了其最新模型 OpenAI o3-pro,这是其旗舰模型 o3 的专业增强版。o3-pro 专为需要“更长时间思考”的复杂任务而设计,其核心亮点在于极致的可靠性和准确性,尤其在数学、科学和编程等专业领域表现卓越。根据OpenAI引入的全新“4/4可靠性”评测标准,o3-pro 的性能远超前代,OpenAI官方强调o3-pro在处理高难度、高风险任务的能力上实现了质的飞跃。

MiniMaxAI于2025年6月17日正式发布了其新一代大模型——MiniMax-M1。MiniMax-M1的核心亮点在于结合了混合专家(MoE)架构和创新的闪电注意力(Lightning Attention)机制。MiniMax-M1不仅原生支持高达100万Token的上下文长度,推理的tokens也支持最高80K,是当前支持的最多推理长度的大模型。此外,MiniMax-M1在计算效率上也很高,例如在生成10万Token时,其FLOPs消耗仅为DeepSeek R1的25%!

短短两年间,AI技术的进步为软件工程带来了新的可能性。然而,这些模型在真实世界的软件工程任务中究竟能发挥多大的作用?它们能否通过完成实际的软件工程任务来赚取可观的收入?为了验证大模型解决真实任务的能力和水平,OpenAI发布了一个全新的大模型评测基准SWE-Lancer来评测大模型这方面的能力。

StabilityAI是一家全球知名的大模型企业,他们开源的Stable Diffusion可以理解为DALL·E开源替代的第一大模型,最近正在测试Stable Diffusion 3。然而,这家企业最近陷入了和去年年底OpenAI类似的“内部斗争”中!前几天,StabilityAI内部宣布Stable Diffusion底层技术的五个研究人员已经有三个离职了,造成大家很多震撼。而几个小时前,StabilityAI官宣他们的CEO Emad Mostaque辞职!

Mistral AI今天发布了其首个专注于推理能力的系列模型——**Magistral**。这次发布包含两个核心模型:旗舰模型`Magistral Medium`和已开源的`Magistral Small (24B)`。最引人注目的亮点是,Mistral展示了其自研的强化学习(RL)pipeline能够从头开始,仅通过RL训练就将基础模型的推理能力提升到业界顶尖水平,而无需依赖任何其他预先存在的推理模型进行数据蒸馏。这套技术栈非常强大!

“Vibe Coding”(氛围编程)是一种新兴的编程范式,强调通过自然语言与人工智能(AI)协作开发软件。该概念由前 OpenAI 研究员 Andrej Karpathy 于 2025 年提出,旨在让开发者沉浸于创作氛围中,利用 AI 的能力,将自然语言描述转化为实际源代码,从而简化编程过程。
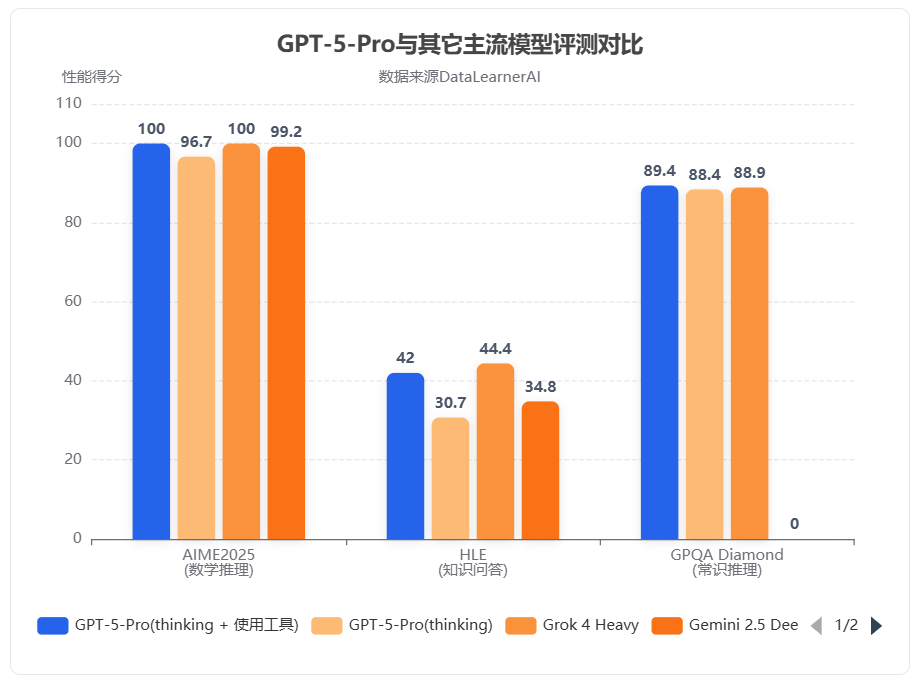
几个小时前,OpenAI发布了全新一代大模型GPT-5系列。本次发布的是一个全新的AI系统,而非一个单独的模型系列。GPT-5背后包含了5个不同的模型系列或者版本,分别是GPT-5-Pro、GPT-5、GPT-5-mini、GPT-5-nano和GPT-5-Chat。
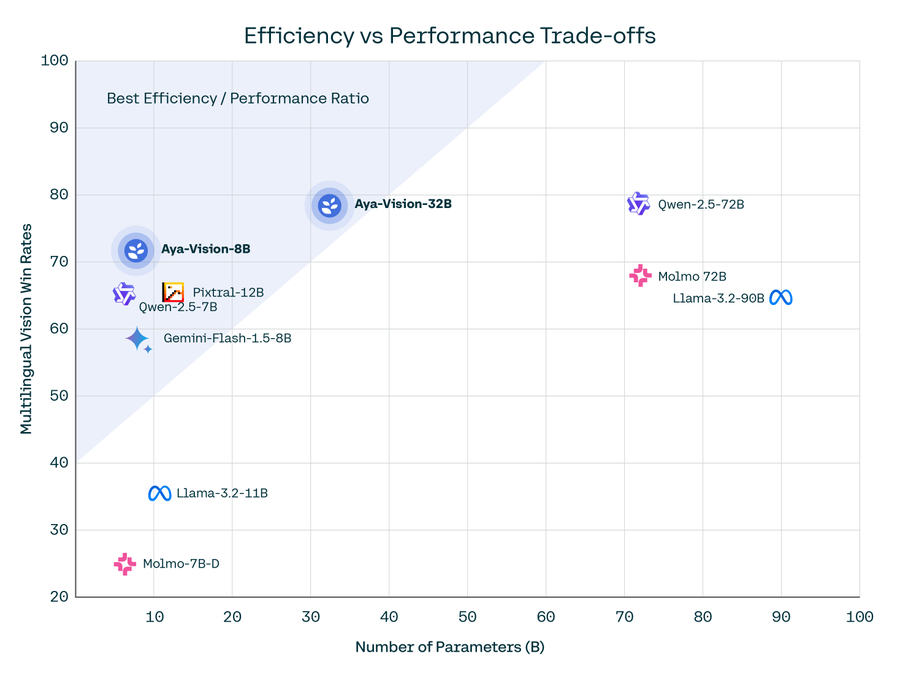
Cohere For AI 推出了 Aya Vision 系列,这是一组包含 80 亿(8B)和 320 亿(32B)参数的视觉语言模型(VLMs)。这些模型针对多模态AI系统中的多语言性能挑战,支持23种语言。Aya Vision 基于 Aya Expanse 语言模型,并通过引入视觉语言理解扩展了其能力。该系列模型旨在提升同时需要文本和图像理解的任务性能。

就在刚才,阿里开源了Qwen Image大模型,这是阿里千问团队开源的高质量图片生成和编辑的大模型。这份发布迅速在AI社区引起了广泛关注,其核心并非又一个单纯追求图像美学或真实感的模型,而是直指一个长期存在的行业痛点:在图像中进行复杂、精准、尤其是高保真的多语言文本渲染。

The Information最新消息透露OpenAI正在抓紧准备GPT-4多模态版本的发布,可能称为GPT4-Vision。
最近,一张截图在网络上流传,显示OpenAI安卓客户端的应用字符串文件(strings.xml)中出现了关于GPT-4.5的相关描述。这一发现引发了广泛关注,暗示OpenAI可能即将推出其最新的大型语言模型——GPT-4.5。该信息最早由开发者 @bitbor91 发现并分享,截图内容似乎来自ChatGPT安卓客户端的应用资源文件。

2025年6月26日,阿里达摩院正式发布了全新的Qwen VLo大模型。这是继QwenVL和Qwen2.5 VL后,阿里在多模态大模型领域又一具有里程碑意义的创新。Qwen VLo是一款统一的多模态理解与生成模型,不仅具备深度理解图片与文本内容的能力,更能基于这种理解实现高质量和高度一致的图像生成与编辑,真正跨越了“感知”与“创造”的界限。
Creative Writing v3 是一个用于评估大型语言模型(LLM)创意写作能力的评测基准。该基准采用混合评分系统,旨在更精确地区分不同模型,特别是顶尖模型之间的性能差异。
今日推荐
Sam Altman宣布未来几周将发布GPT-4.5,几个月后发布GPT-5,未来免费用户也可以无限量使用GPT-5!
预训练模型编程框架Transformers迎来重磅更新:Transformers Agents发布,一个完全的多模态AI Agent!
李开复创业公司零一万物开源迄今为止最长上下文大模型:Yi-6B和Yi-34B,支持200K超长上下文
吴恩达再开新课程!如何基于大语言模型实现更强大的语义搜索课程!
可能是史上最强大的AI Agent!OpenAI重磅更新:整合了多模态、外部访问、数据分析后的GPT-4更像是AI Agent了!
A21 Labs宣布开源520亿参数的全新混合专家大模型(Mixture of Experts,MoE)Jamba:单个GPU的上下文长度是Mixtral 8x7B的三倍
MBA与数据分析师危矣?最新内测版本的ChatGPT已经可以针对excel自动做数据分析和异常分析了!
AIME 2025满分,xAI正式发布Grok模型,其中Grok 4 Heavy评测超越当前所有大模型,美国数学竞赛满分!一年3000美元订阅费!