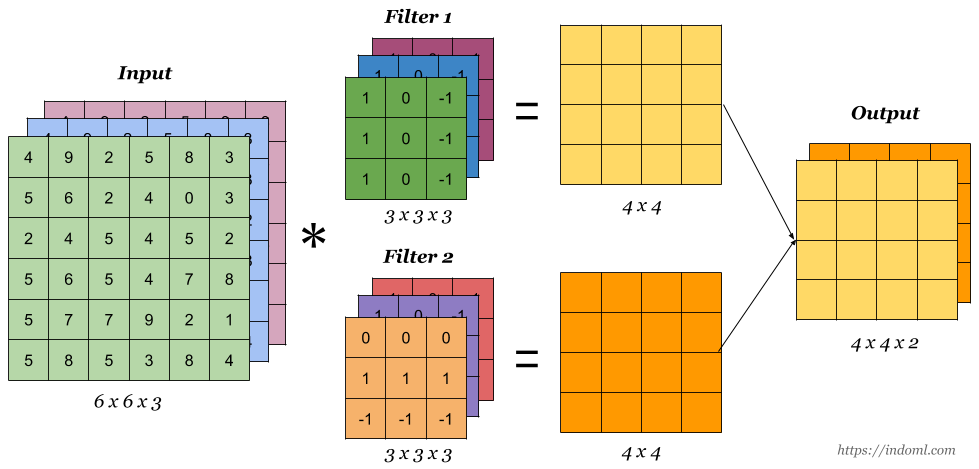
深度学习卷积操作的维度计算(PyTorch/Tensorflow等框架中Conv1d、Conv2d和Conv3d介绍)
卷积操作的维度计算是定义神经网络结构的重要问题,在使用如PyTorch、Tensorflow等深度学习框架搭建神经网络的时候,对每一层输入的维度和输出的维度都必须计算准确,否则容易出错,这里将详细说明相关的维度计算。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
卷积操作的维度计算是定义神经网络结构的重要问题,在使用如PyTorch、Tensorflow等深度学习框架搭建神经网络的时候,对每一层输入的维度和输出的维度都必须计算准确,否则容易出错,这里将详细说明相关的维度计算。

这个系列的博客来自于 Bayesian Data Analysis, Third Edition. By. Andrew Gelman. etl. 的第五章的翻译。实际中,简单的非层次模型可能并不适合层次数据:在很少的参数情况下,它们并不能准确适配大规模数据集,然而,过多的参数则可能导致过拟合的问题。相反,层次模型有足够的参数来拟合数据,同时使用总体分布将参数的依赖结构化,从而避免过拟合问题。
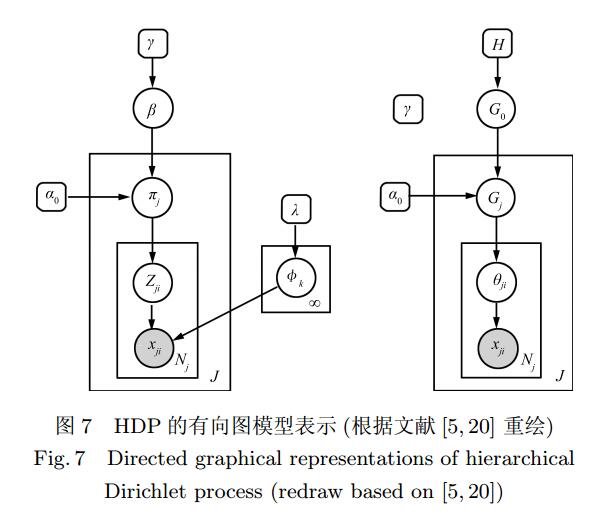
Dirichlet过程是一种重要的非参数模型,它可运用在聚类中,自动发现类别的数量。但很多时候,我们的工作都是具有层次话的。这篇文章介绍的层次狄利克雷模型就是解决这样的问题的。
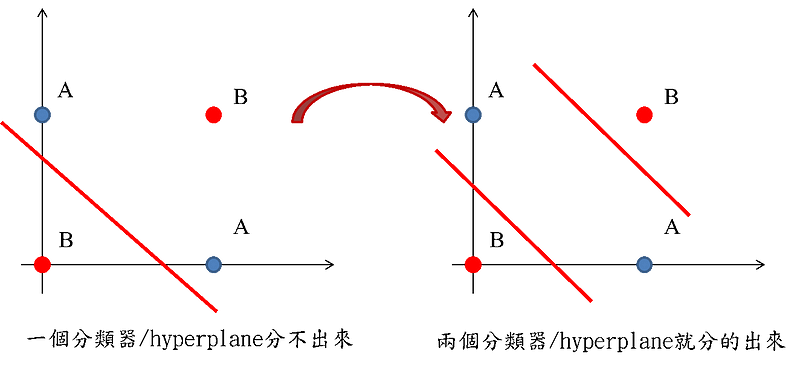
集成学习(Ensemble Learning)是解决有监督机器学习的一类方法,它的思路是基于多个学习算法的集成来获取一个更好的预测结果。本文将介绍相关概念,并对一些注意事项进行总结。
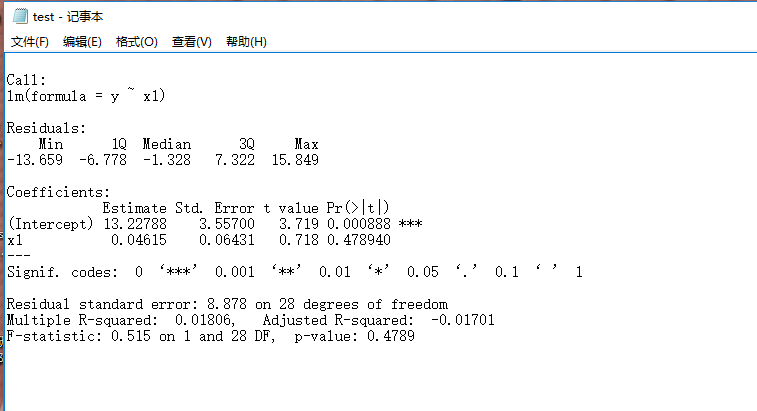
使用R语言进行数据分析时,我们经常会遇到实验结果输出的问题,例如使用summary函数时,变量太多,控制台输出的结果不全,那么怎么将结果导出呢?
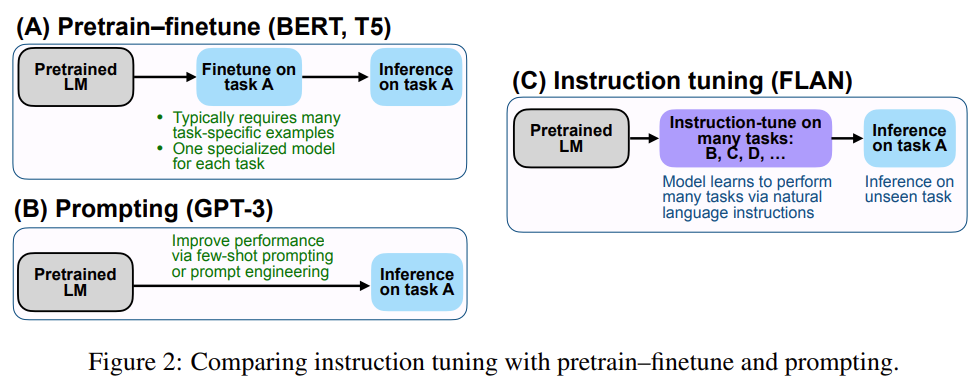
Prompt-Tuning、Instruction-Tuning和Chain-of-Thought是近几年十分流行的大模型训练技术,本文主要介绍这三种技术及其差别。
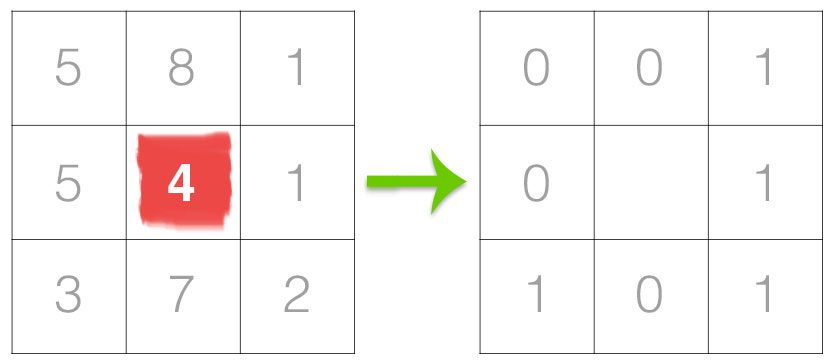
1998年,LeCun提出了LeNet-5网络用来解决手写识别的问题。LeNet-5被誉为是卷积神经网络的“Hello Word”,足以见到这篇论文的重要性。在此之前,LeCun最早在1989年提出了LeNet-1,并在接下来的几年中继续探索,陆续提出了LeNet-4、Boosted LeNet-4等。本篇博客将详解LeCun的这篇论文,并不是完全翻译,而是总结每一部分的精华内容。


深度学习是目前最火的算法领域。他在诸多任务中取得的骄人成绩使得其进化越来越好。本文收集深度学习中的经典算法,以及相关的解释和代码实现。
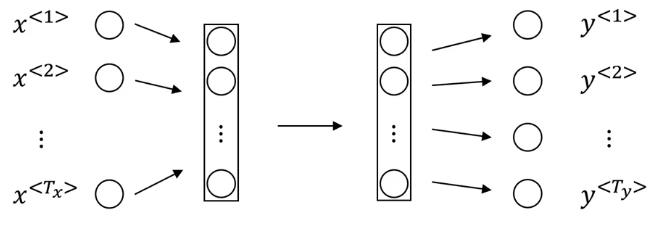
序列数据是生活中很常见的一种数据,如一句话、一段时间某个广告位的流量、一连串运动视频的截图等。在这些数据中也有着很多数据挖掘的需求。RNN就是解决这类问题的一种深度学习方法。其全称是Recurrent Neural Networks,中文是递归神经网络。主要解决序列数据的数据挖掘问题。
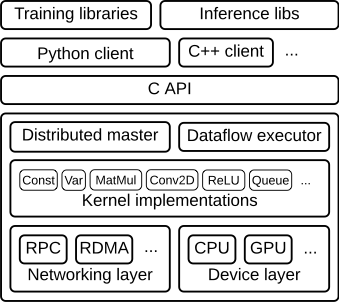
随着深度学习的火热,对计算机算力的要求越来越高。从2012年AlexNet以来,人们越来越多开始使用GPU加速深度学习的计算。 然而,一些传统的机器学习方法对GPU的利用却很少,这浪费了很多的资源和探索的可能。在这里,我们介绍一个非常优秀的项目——RAPIDS,这是一个致力于将GPU加速带给传统算法的项目,并且提供了与Pandas和scikit-learn一致的用法和体验,非常值得大家尝试。
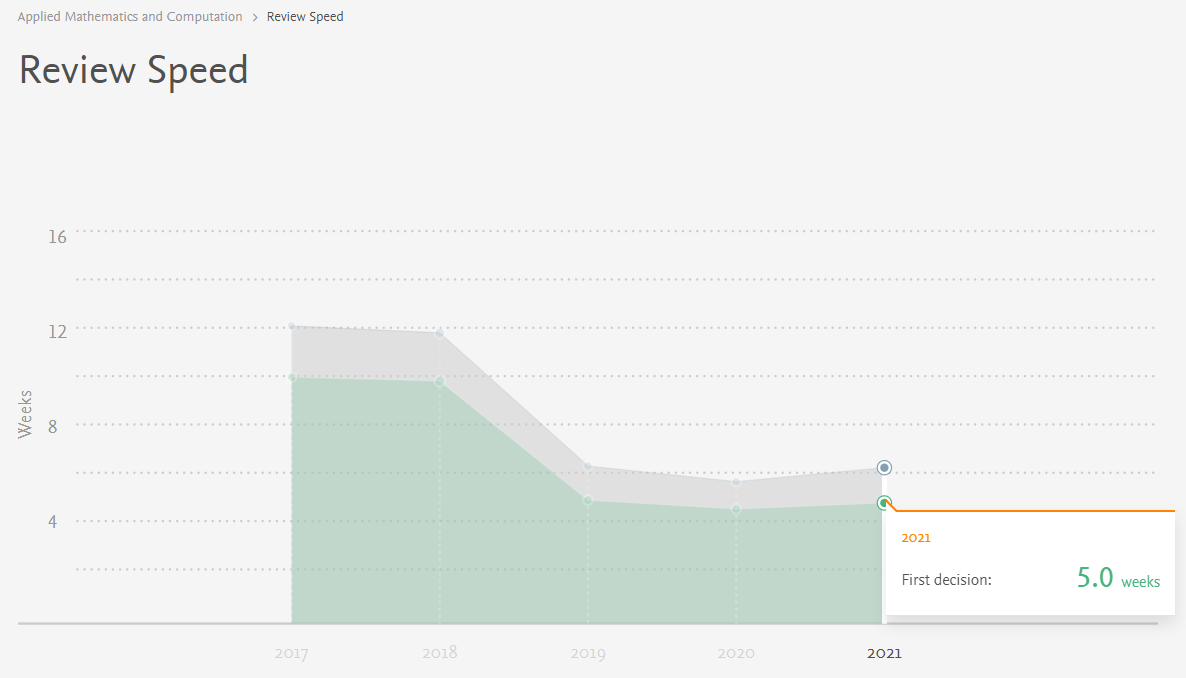
科研成果发表速度对于国内的硕士生和博士生来说非常重要,它涉及了同学们的毕业、出国和奖学金等。很多童鞋在投稿之前都希望了解期刊的审稿周期。虽然大多数期刊没有规定明确的审稿时间,但是,随着大家对学术期刊投稿周期的关注,很多学术期刊也开始就自己的审稿速度开始有所要求,本文针对常见的期刊审稿周期提供一个普遍的分析方法。
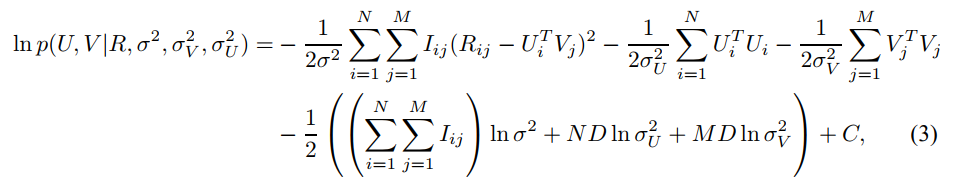
本篇博客详细说明了概率矩阵分解(Probabilistic Matrix Factorization,PMF)的推导过程
文本预处理是一件极其耗费时间的事情,不仅繁琐而且涉及的细节很多,处理不好对后面的事情的影响很大。本文将简要介绍文本预处理的一般步骤和方法。
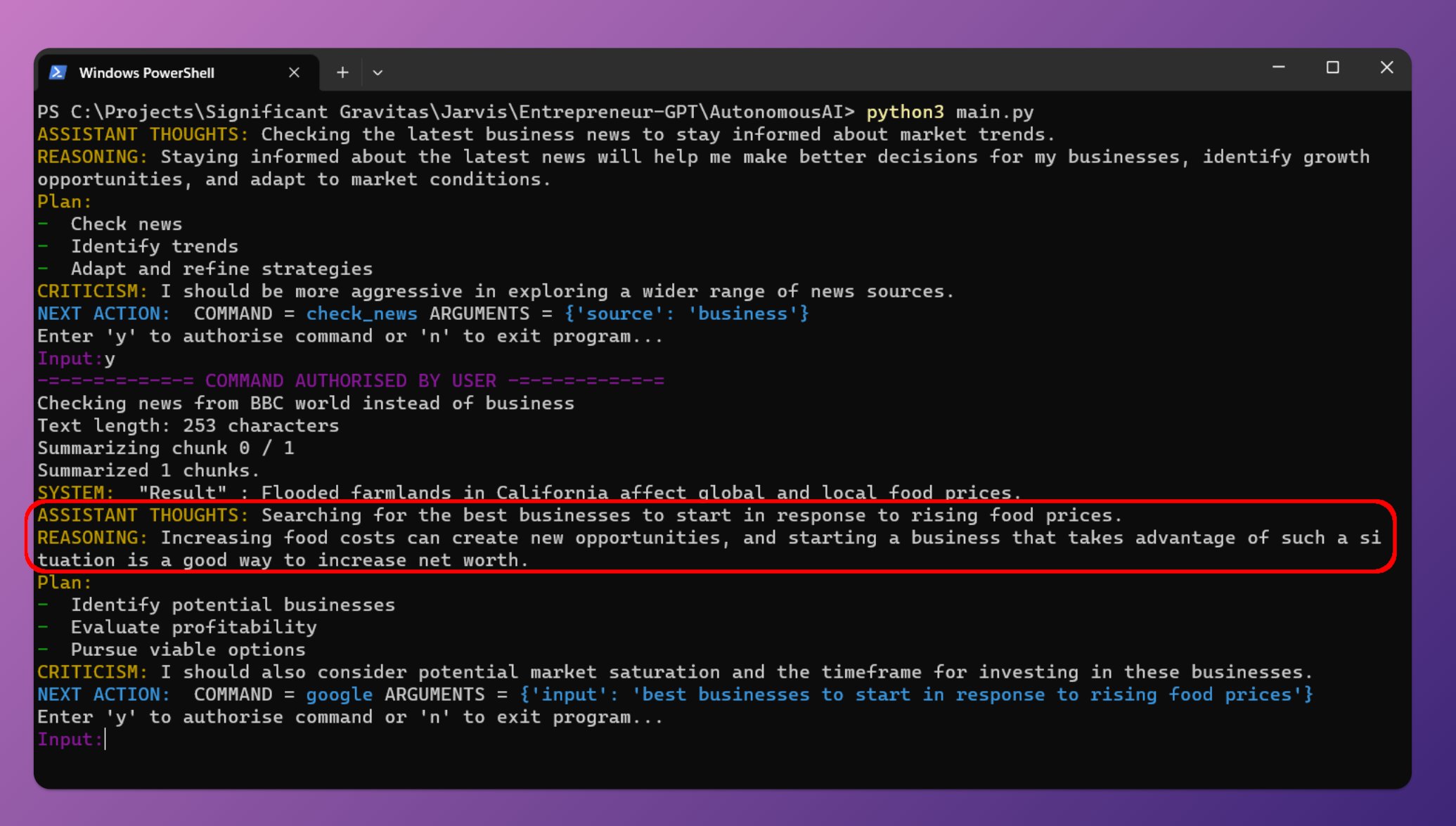
最近几天AutoGPT十分火热,这是由开发者Significant Gravitas推出的项目。该项目可以根据你设置的目标,使用GPT-4自动帮你完成所有的任务。你只要提供OpenAI的API Key,保证里面有钱,那么它就可以根据你设定的目标,采用Google搜索、浏览网站、执行脚本等方式帮你完成目标。
在机器学习或者深度学习中,正则项是我们经常遇到的概念。它对提高模型的准确性和泛化能力非常重要。本文详细描述了正则项的来源以及与其他概念的相关关系。
multi-class classification problem和 multi-label classification problem在keras上的实现
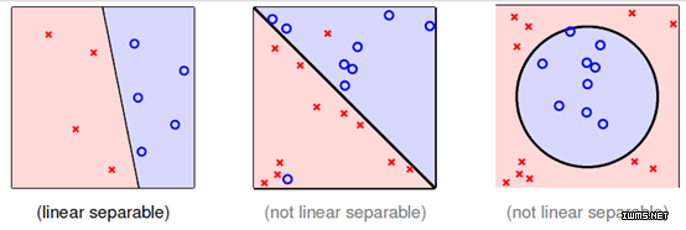
KKT条件(Karush–Kuhn–Tucker conditions)是求解带不等式约束的最优化问题中非常重要的一个概念和方法。这篇博客将解释相关概念和操作。

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。

Tensorflow中tf.data.Dataset是最常用的数据集类,我们也使用这个类做转换数据、迭代数据等操作。本篇博客将简要描述这个类的使用方法。
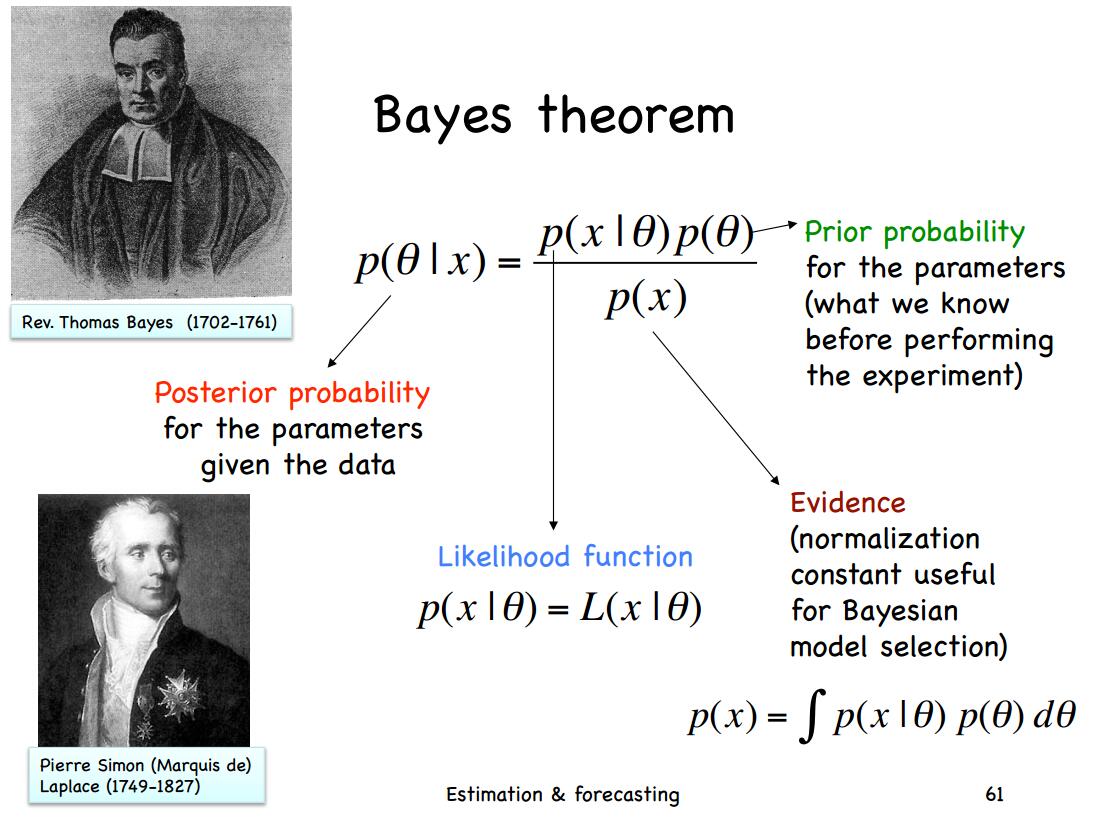
贝叶斯统计非常有用,也有一些基本的概念。这篇博客介绍了各种分布/概率的相关概念,并做了简单的介绍。
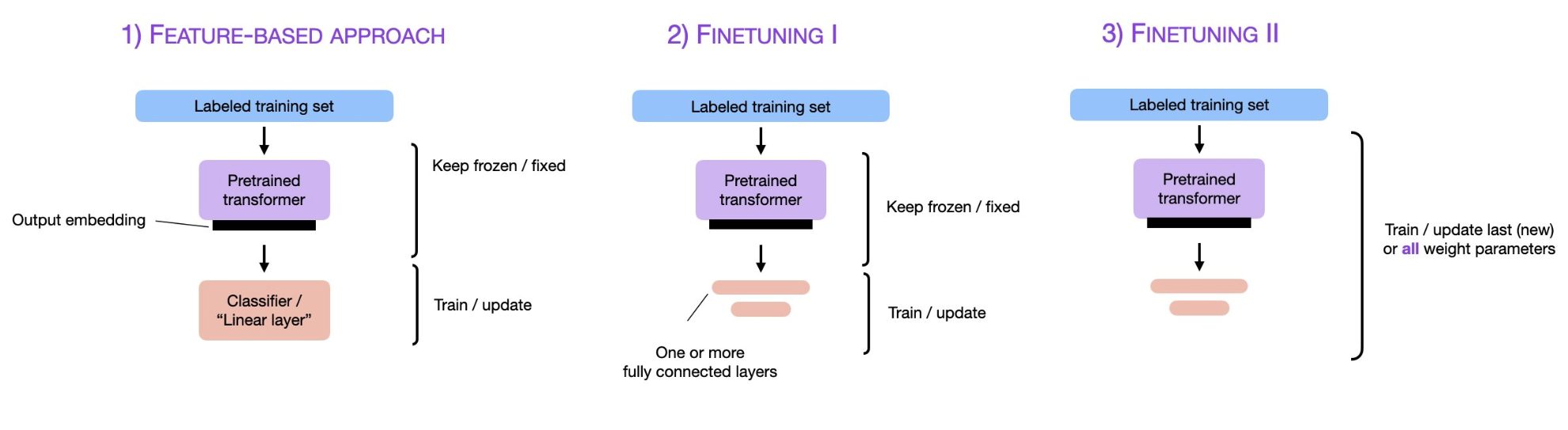
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。
很多童鞋在查询期刊的时候会发现某些期刊不是SCI(SCIE)索引,而是一个叫ESCI的索引。这似乎有点像SCI,但好像又有区别,所以大家会有疑问,本篇博客将解释二者的区别。