
深度学习之Encoder-Decoder架构
深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。


当前的大语言模型主要是预训练大模型,在大规模无监督数据上训练之后,再经过有监督微调和对齐之后就可以完成很多任务。尽管如此,面对垂直领域的应用,大模型依然需要微调才能获得更好地应用结果。而大模型的微调有很多方式,包括指令微调、有监督微调、提示工程等。其中,指令微调(Instruction Tuning)作为改进模型可控性最重要的一类方法,缺少深入的研究。浙江大学研究人员联合Shannon AI等单位发布了一篇最新的关于指令微调的综述,详细描述指令微调的各方面内容。

Hugging Face是一家非常活跃的人工智能创业公司。它拥有一个非常强大并且活跃的人工智能社区。有超过5000多家机构都在Hugging Face的社区发布内容,包括Google AI、Facebook AI、微软等。自从2016年成立以来,这家企业经历了5轮融资,总共募集了6000万美金。本文将简要介绍这家企业相关的信息。
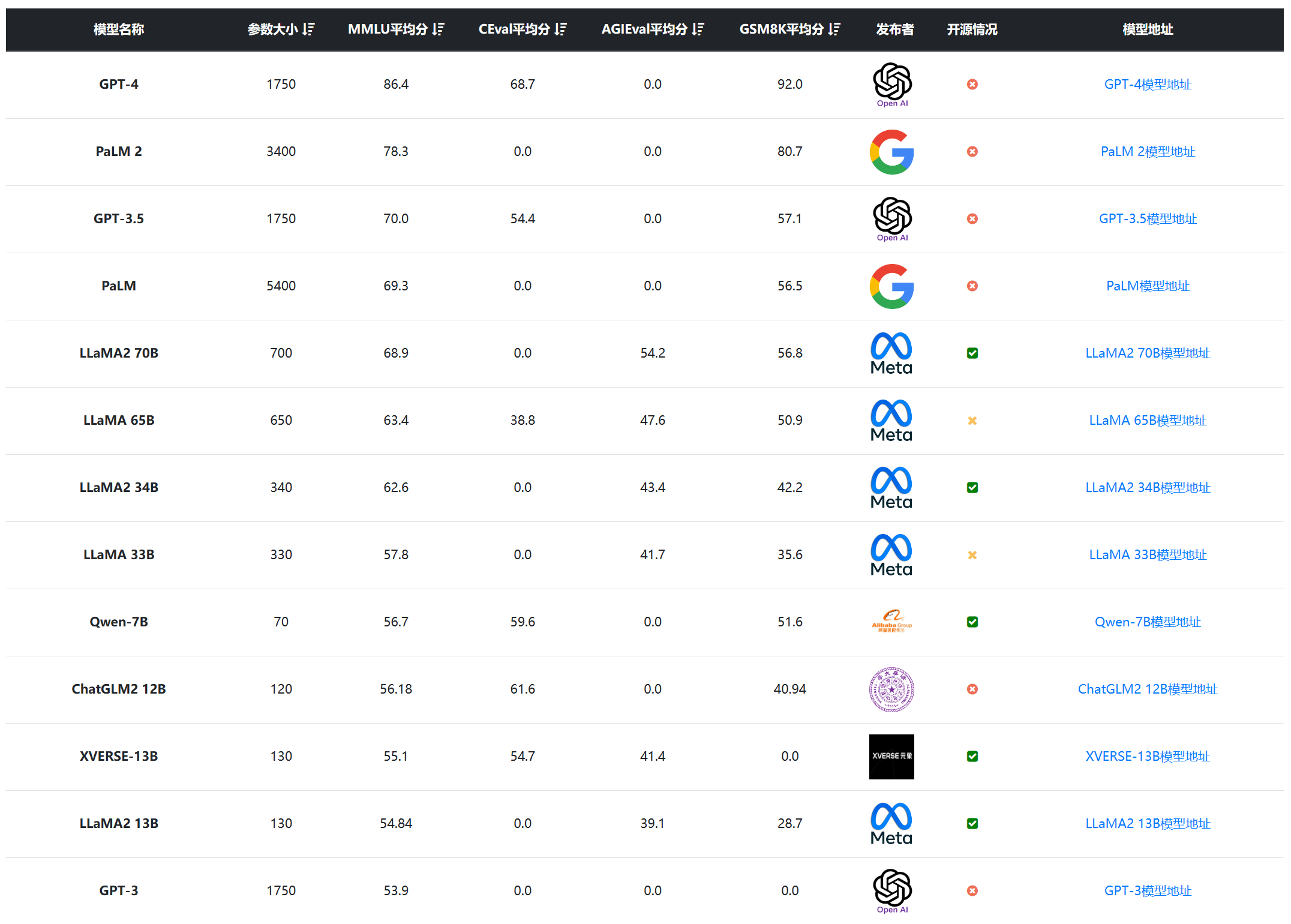
随着各种AI模型的快速发展,选择合适的模型成为了研究和开发的一大挑战。最近一段时间,国产模型不断涌现,让人应接不暇。尽管开源的繁荣提供了更多的选择,实际上也造成了选型的困难,尽管业界提供了很多评测基准,但是,**很多模型在公布的评测结果中对比的模型基准和选择的测试基准都很少,甚至只选择对自己有利的结果**。为了更加方便大家对比相关的结果,DataLearner上线了大模型评测综合排行对比表,给大家提供一个更加清晰的对比结果。我们主要关注的是国内开源大模型和一些全球主流模型的对比结果。

pandas.get_dummies是pandas中一种非常高效的方法。它最主要的作用是可以将分类变量转变成dummy变量,也就是虚拟变量。这篇博客将简要的介绍一下pandas.get_dummies()方法,并描述其在机器学习中的应用的一些注意事项。
多元正态(高斯)分布分布是我们最常用的分布之一,这篇博客的主要内容来自Will Penny的文章的翻译。主要讲述关于多元正态分布的贝叶斯推导

在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,可以提高模型效果。
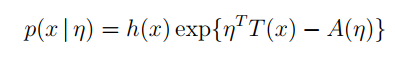
指数分布族(Exponential Family)相关公式推导及在变分推断中的应用
大规模的text-to-image模型没有公开预训练结果,OpenAI的意思就是我这玩意太厉害,随便放出来可能会被你们做坏事,而谷歌训练这个应该就是为了云服务挣钱,所以都没有公开可用的版本供大家玩耍。虽然业界有基于论文的实现,但是训练模型需要耗费大量的资源,没有开放的预训练结果,我们普通个人也很难玩起来。但是,大神Sahar提供了一个免费使用开源实现的text-to-image预训练模型的方式。

使用预训练模型处理NLP任务是目前深度学习中一个非常火热的领域。本文总结了8个顶级的预训练模型,并提供了每个模型相关的资源(包括官方文档、Github代码和别人已经基于这些模型预训练好的模型等)。
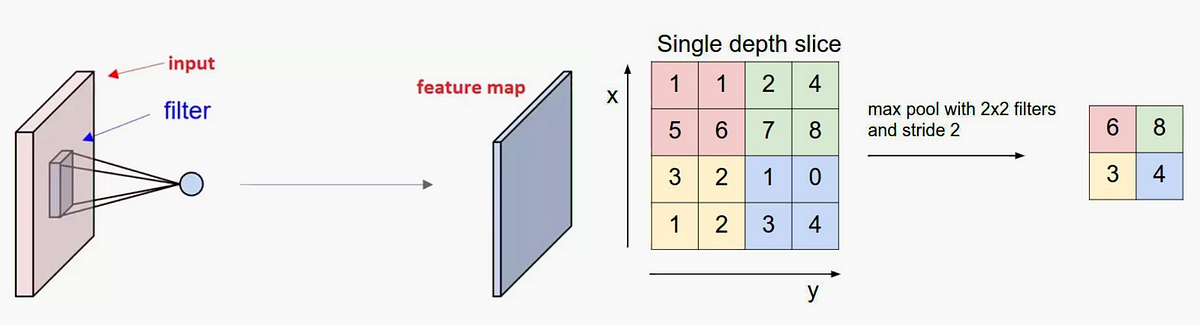
卷积神经网络是图像识别领域最重要的深度学习技术。也可以说是是本轮深度学习浪潮开始点。本文总结了CNN的三种高级技巧,分别是空洞卷积、显著图和反卷积技术。
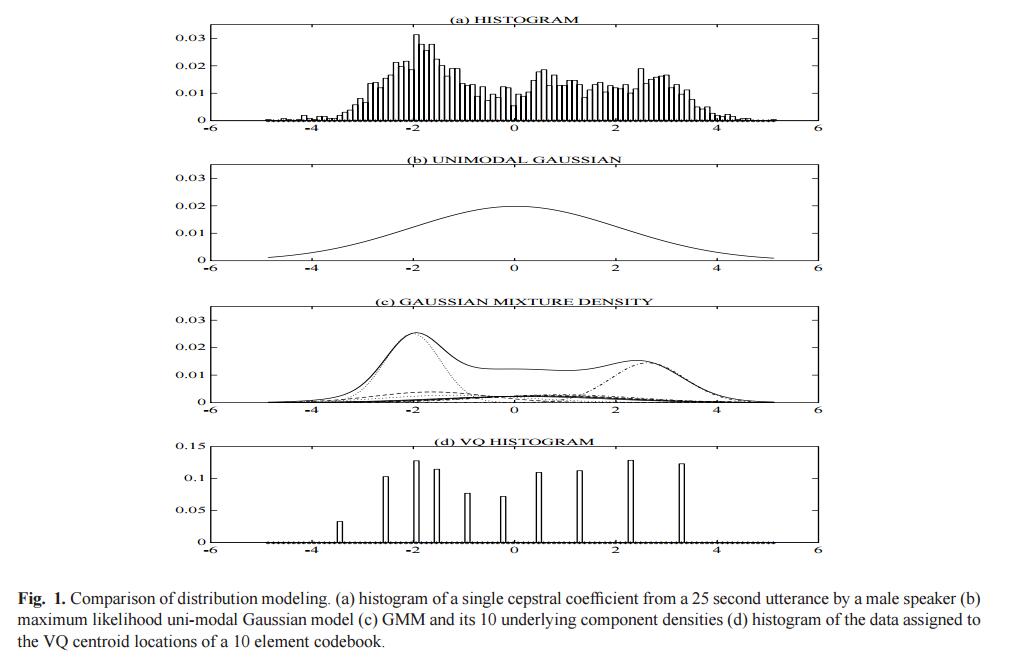
高斯混合模型是一个参数概率密度函数,它是一组高斯密度函数的加权求和。在生物统计领域,高斯混合模型通常是连续测度或者特征的概率分布的参数模型。高斯混合模型可以使用迭代的EM算法或者最大后验概率法估计参数。
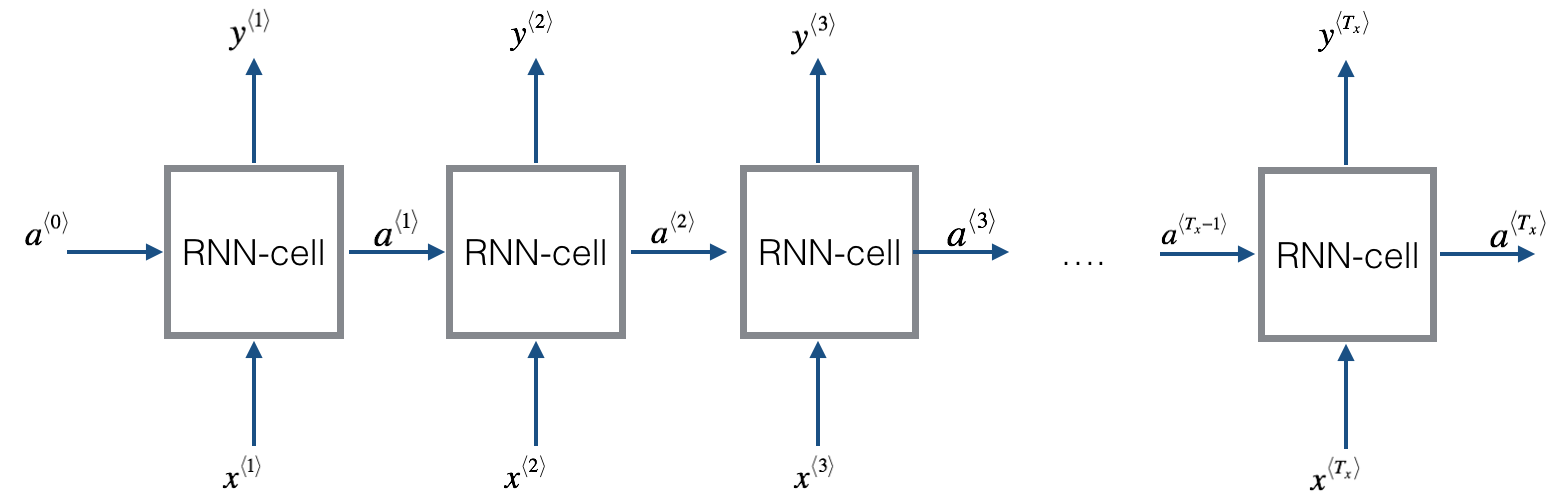
之前面的博客中,我们已经描述了基本的RNN模型。但是基本的RNN模型有一些缺点难以克服。其中梯度消失问题(Vanishing Gradients)最难以解决。为了解决这个问题,GRU(Gated Recurrent Unit)神经网络应运而生。本篇博客将描述GRU神经网络的工作原理。GRU主要思想来自下面两篇论文:
EM(expectation-maximization)算法是统计学中求统计模型的最大似然和最大后验参数估计的一种迭代式算法,模型一般是依赖于不可观测的潜在变量。
AdaBoost,全称是“Adaptive Boosting”,由Freund和Schapire在1995年首次提出,并在1996发布了一篇新的论文证明其在实际数据集中的效果。这篇博客主要解释AdaBoost的算法详情以及实现。它可以理解为是首个“boosting”方式的集成算法。是一个关注二分类的集成算法。
HMC(Hamiltonian Monte Carlo抽样算法详细介绍)
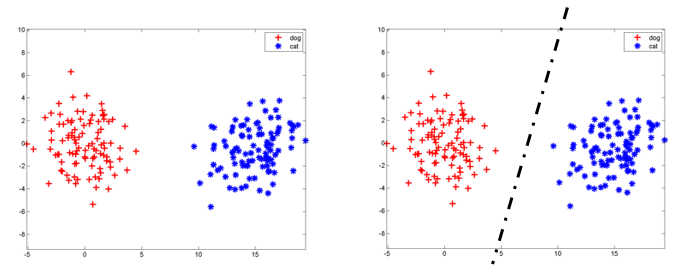
人工神经网络,简称神经网络,是一种模仿生物神经网络的结构和功能的数学模型或者计算模型。其实是一种与贝叶斯网络很像的一种算法。之前看过一些内容始终云里雾里,这次决定写一篇博客。弄懂这个基本原理,毕竟现在深度学习太火了。