text-davinci-003后继者!OpenAI发布了一个新的补全大模型:GPT-3.5-Turbo-Instruct,完全的指令模型,没有聊天优化
OpenAI最新发布了GPT-3.5-Turbo-Instruct,这是一款强大的指令遵循大模型。尽管官方没有发布官方博客介绍,但我们将在本文中详细探讨这一模型的特点以及其在人工智能领域的价值。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
OpenAI最新发布了GPT-3.5-Turbo-Instruct,这是一款强大的指令遵循大模型。尽管官方没有发布官方博客介绍,但我们将在本文中详细探讨这一模型的特点以及其在人工智能领域的价值。

最近,随着DeepSeek R1的火爆,推理大模型也进入大众的视野。但是,相比较此前的GPT-4o,推理大模型的区别是什么?它适合什么样的任务?推理大模型是如何训练出来的?很多人并不了解。本文将详细解释推理大模型的核心内容。
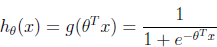
监督学习中的分类问题和Logistic回归常常被用于推荐问题中关于BPR的研究,但是为什么一定要用Logistic函数来建模和优化呢?本篇博客将带你揭晓奥秘~

在前面的博客中,我们已经对`Dask`做了一点简单的介绍了,在这篇博客中我们来对比一下`Dask`的`DataFrame`在不同条件下的运算性能,主要是连接操作的性能(merge)。
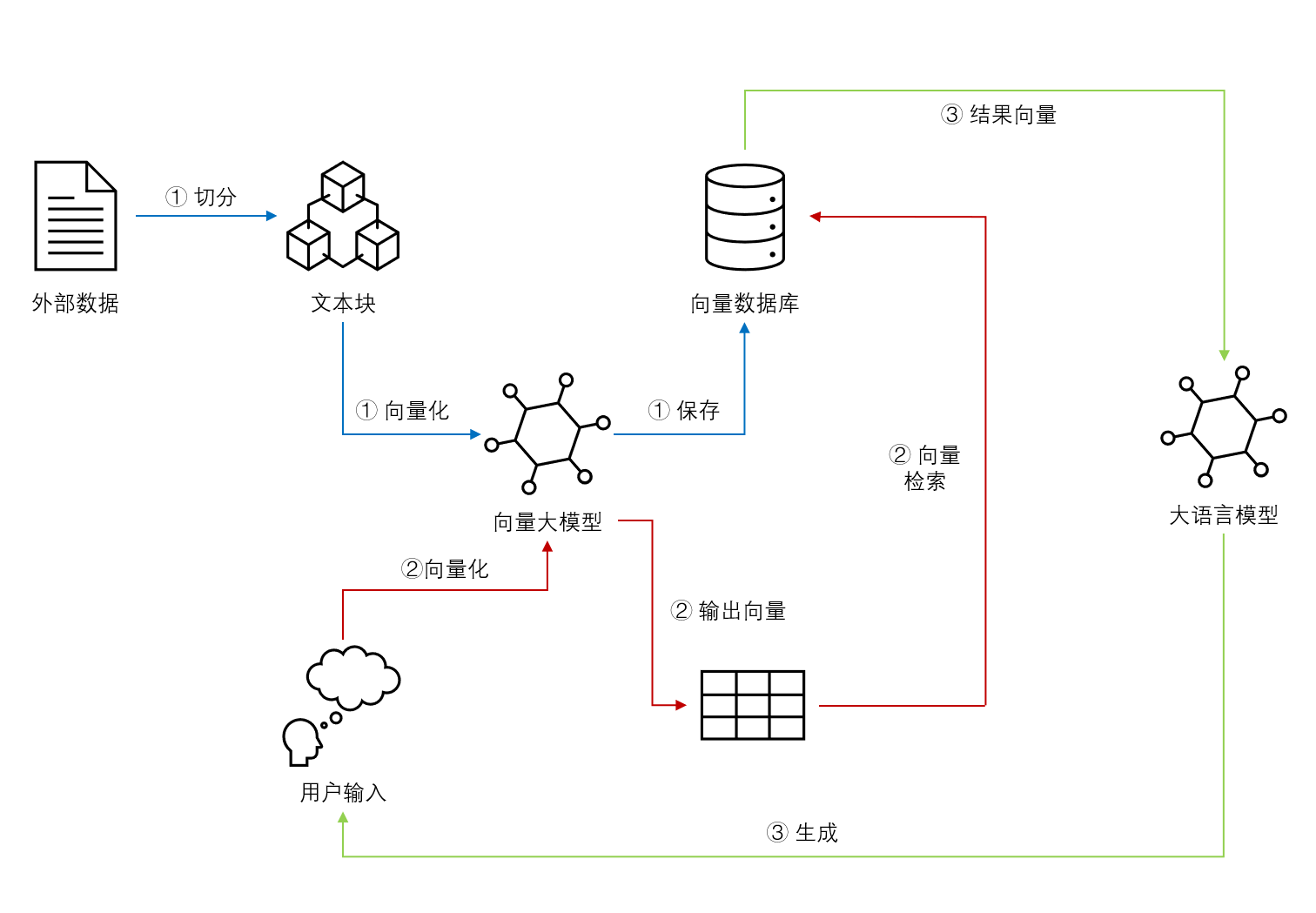
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。
美国有一家上市企业,叫做Roblox,号称是元宇宙龙头企业,被市场炒的火热。这家企业到底是什么样的业务,可以被认为是一家纯正的元宇宙企业。本文根据我收集的资料,为大家介绍一下。
机器学习是实现人工智能最重要的方法之一,包括深度学习等都属于机器学习中的一种方法。因此,机器学习的应用被认为是实现人工智能应用的重要途径。人工智能的应用目标是使用计算机(机器)来代替或者辅助人工来完成某项任务。机器学习在解决业务问题的应用需要谨慎考虑。本文提供一些步骤可以参考。
Spring Security可以帮助我们进行页面的权限控制和登录验证,在这篇博客中,我们将简要描述如何使用Spring Security进行登录验证。
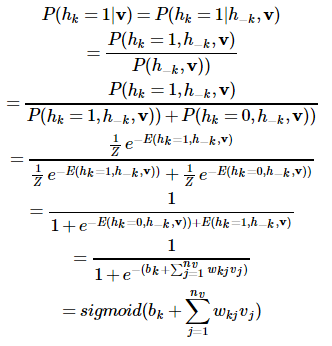
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是G.Hinton教授的一宝。Hinton教授是深度学习的开山鼻祖,也正是他在2006年的关于深度信念网络DBN的工作,以及逐层预训练的训练方法,开启了深度学习的序章。其中,DBN中在层间的预训练就采用了RBM算法模型。RBM是一种无向图模型,也是一种神经网络模型。
![[翻译]当推荐系统遇上深度学习](https://www.datalearner.com/resources/blog_images/2cdfcd04-ad6f-4183-9e6e-0c3b24ec4515.png)
翻译自Wann-Jiun Ma的Deep Learning Meets Recommendation Systems,主要讲了推荐系统的基础算法以及使用深度学习对电影的海报进行近似计算,从而推荐相似的电影。

Scikit-Learn有很优秀的机器学习处理思想,包括TensorFlow等新框架都借鉴了它的设计思想。最近的更新也让Scikit-Learn更加强大。在描述这个更新之前我们先简单看一下历史,然后让我们一起看看都有什么新内容吧。
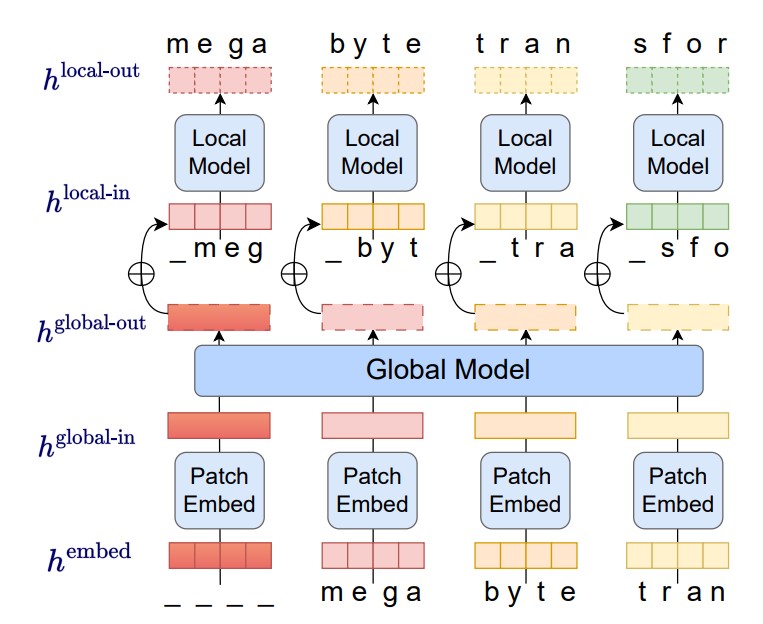
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!
使用pandas的DataFrame和dask的DataFrame保存数据到csv文件时候会出现两个换行符的情况。本文描述如何解决。

在编程的世界中,有不同层次的语言(language),这些语言有时候也称代码(code)。本文将简单介绍编程语言(Programming Language)、汇编语言(Assembly Language, ASM)、机器语言(Machine Language/Code)的区别。

时间序列数据分析的基础包含大量的统计知识。这篇博客主要用通俗的语言描述时间序列数据中涉及到的一些基本统计知识。
GGML是在大模型领域常见的一种文件格式。HuggingFace上著名的开发者Tom Jobbins经常发布带有GGML名称字样的大模型。通常是模型名+GGML后缀,那么这个名字的模型是什么?GGML格式的文件名的大模型是什么样的大模型格式?如何使用?本文将简单介绍。
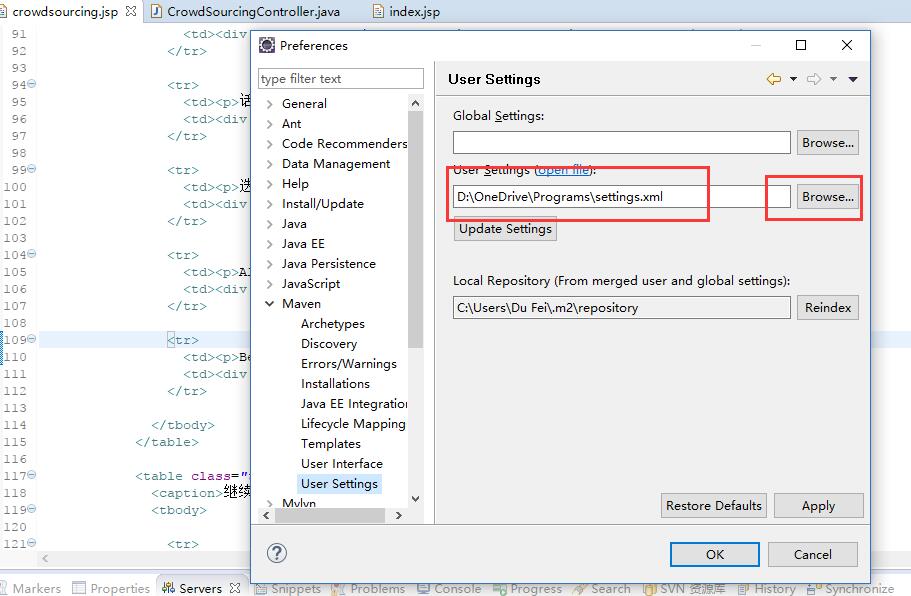
使用Maven作为构建工具,管理项目和依赖非常方便。这篇博客将简要介绍在Eclipse中如何使用Maven插件
Author Topic Model[ATM理解及公式推导]
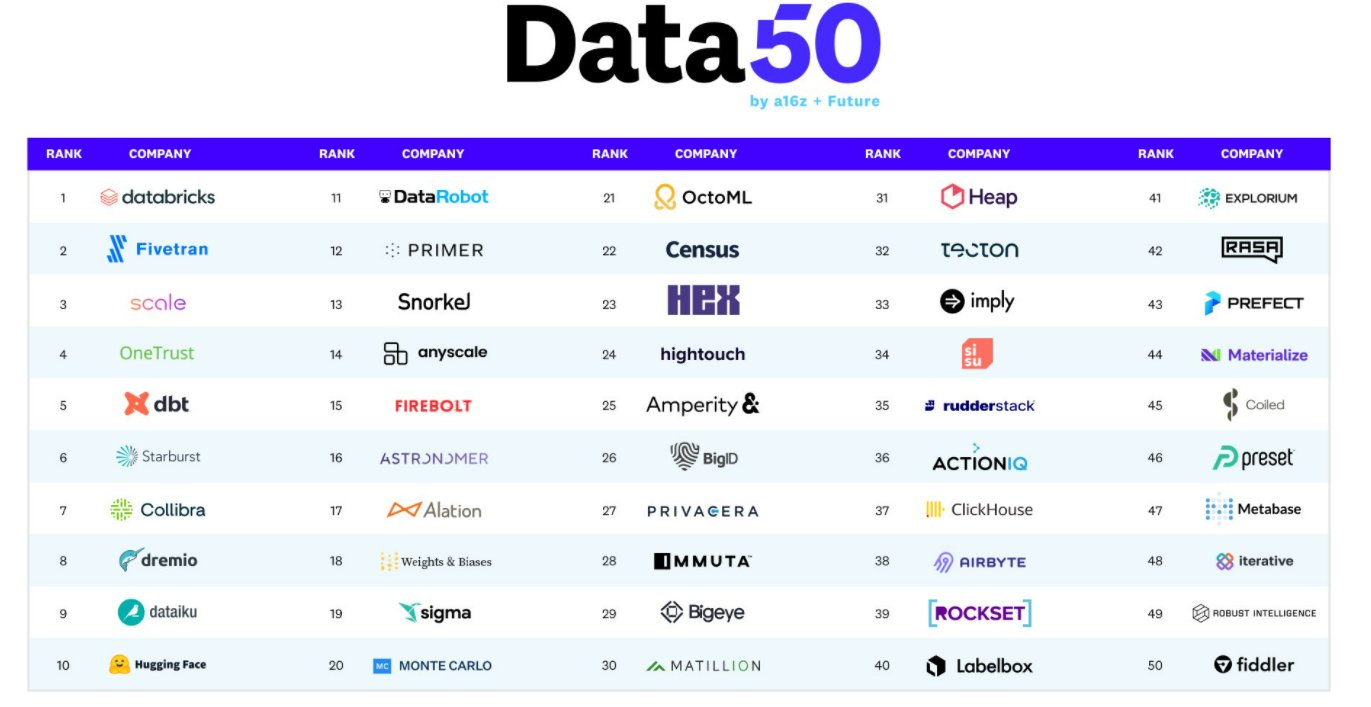
最近几年,数据的重要性在各个领域都获得了巨大的重视。因此,数据管理相关的业务也成为各项基础设施中增长最快的业务,目前的市场规模约700亿美元,占所有企业的基础设施支持约1/5。仅在2021年,数据处理相关的公司获得了数百亿的风险投资。为此,Future总结了2022年全球最大的50家数据创业企业。这里我们列举其中的最大的10个进行介绍。

大语言模型(Large Language Model,LLM)已经在很多领域都产生了巨大的影响。但是其中最为大家所期待的功能之一就是基于idea生成PPT、Word文档等。此前微软Office Copilot已经吸引了很多人的关注,但目前依然没有开放。而今天DataLearnerAI发现了一个类似的产品,来自洛杉矶初创企业Gamma的产品目前已经支持基于文本生成PPT、Word和网页应用了,本文带大家简单体验一下这个产品。

Qwen系列是阿里巴巴开源的一系列大语言模型。在此前的开源中,阿里巴巴共开源了3个系列的大模型,分别是70亿参数规模和140亿参数规模的Qwen-7B和Qwen-14B,还有一个是多模态大模型Qwen-VL。而此次阿里巴巴开源了720亿参数规模的Qwen-72b,是目前国内最大参数规模的开源大语言模型,应该也是全球范围内首次有和Llama2-70b同等规模的大语言模型开源。